Git Tools
By now, you’ve learned most of the day-to-day commands and workflows that you need to manage or maintain a Git repository for your source code control. You’ve accomplished the basic tasks of tracking and committing files, and you’ve harnessed the power of the staging area and lightweight topic branching and merging.
Now you’ll explore a number of very powerful things that Git can do that you may not necessarily use on a day-to-day basis but that you may need at some point.
Revision Selection
Git allows you to refer to a single commit, set of commits, or range of commits in a number of ways. They aren’t necessarily obvious but are helpful to know.
Single Revisions
You can obviously refer to any single commit by its full, 40-character SHA-1 hash, but there are more human-friendly ways to refer to commits as well. This section outlines the various ways you can refer to any commit.
Short SHA-1
Git is smart enough to figure out what commit you’re referring to if you provide the first few characters of the SHA-1 hash, as long as that partial hash is at least four characters long and unambiguous; that is, no other object in the object database can have a hash that begins with the same prefix.
For example, to examine a specific commit where you know you added certain functionality, you might first run the git log command to locate the commit:
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
In this case, say you’re interested in the commit whose hash begins with 1c002dd….
You can inspect that commit with any of the following variations of git show (assuming the shorter versions are unambiguous):
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b $ git show 1c002dd4b536e7479f $ git show 1c002d
Git can figure out a short, unique abbreviation for your SHA-1 values.
If you pass --abbrev-commit to the git log command, the output will use shorter values but keep them unique; it defaults to using seven characters but makes them longer if necessary to keep the SHA-1 unambiguous:
$ git log --abbrev-commit --pretty=oneline ca82a6d changed the version number 085bb3b removed unnecessary test code a11bef0 first commit
Generally, eight to ten characters are more than enough to be unique within a project. For example, as of February 2019, the Linux kernel (which is a fairly sizable project) has over 875,000 commits and almost seven million objects in its object database, with no two objects whose SHA-1s are identical in the first 12 characters.
A SHORT NOTE ABOUT SHA-1
A lot of people become concerned at some point that they will, by random happenstance, have two distinct objects in their repository that hash to the same SHA-1 value. What then?
If you do happen to commit an object that hashes to the same SHA-1 value as a previous different object in your repository, Git will see the previous object already in your Git database, assume it was already written and simply reuse it. If you try to check out that object again at some point, you’ll always get the data of the first object.
However, you should be aware of how ridiculously unlikely this scenario is.
The SHA-1 digest is 20 bytes or 160 bits.
The number of randomly hashed objects needed to ensure a 50% probability of a single collision is about 280
(the formula for determining collision probability is p = (n(n-1)/2) * (1/2^160)). 280
is 1.2 x 1024
or 1 million billion billion.
That’s 1,200 times the number of grains of sand on the earth.
Here’s an example to give you an idea of what it would take to get a SHA-1 collision. If all 6.5 billion humans on Earth were programming, and every second, each one was producing code that was the equivalent of the entire Linux kernel history (6.5 million Git objects) and pushing it into one enormous Git repository, it would take roughly 2 years until that repository contained enough objects to have a 50% probability of a single SHA-1 object collision. Thus, a SHA-1 collision is less likely than every member of your programming team being attacked and killed by wolves in unrelated incidents on the same night.
Branch References
One straightforward way to refer to a particular commit is if it’s the commit at the tip of a branch; in that case, you can simply use the branch name in any Git command that expects a reference to a commit.
For instance, if you want to examine the last commit object on a branch, the following commands are equivalent, assuming that the topic1 branch points to commit ca82a6d…:
$ git show ca82a6dff817ec66f44342007202690a93763949 $ git show topic1
If you want to see which specific SHA-1 a branch points to, or if you want to see what any of these examples boils down to in terms of SHA-1s, you can use a Git plumbing tool called rev-parse.
You can see Git Internals for more information about plumbing tools; basically, rev-parse exists for lower-level operations and isn’t designed to be used in day-to-day operations.
However, it can be helpful sometimes when you need to see what’s really going on.
Here you can run rev-parse on your branch.
$ git rev-parse topic1 ca82a6dff817ec66f44342007202690a93763949
RefLog Shortnames
One of the things Git does in the background while you’re working away is keep a ``reflog'' — a log of where your HEAD and branch references have been for the last few months.
You can see your reflog by using git reflog:
$ git reflog
734713b HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970 HEAD@{1}: merge phedders/rdocs: Merge made by the 'recursive' strategy.
1c002dd HEAD@{2}: commit: added some blame and merge stuff
1c36188 HEAD@{3}: rebase -i (squash): updating HEAD
95df984 HEAD@{4}: commit: # This is a combination of two commits.
1c36188 HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5 HEAD@{6}: rebase -i (pick): updating HEAD
Every time your branch tip is updated for any reason, Git stores that information for you in this temporary history.
You can use your reflog data to refer to older commits as well.
For example, if you want to see the fifth prior value of the HEAD of your repository, you can use the @{5} reference that you see in the reflog output:
$ git show HEAD@{5}
You can also use this syntax to see where a branch was some specific amount of time ago.
For instance, to see where your master branch was yesterday, you can type
$ git show master@{yesterday}
That would show you where tip of your master branch was yesterday.
This technique only works for data that’s still in your reflog, so you can’t use it to look for commits older than a few months.
To see reflog information formatted like the git log output, you can run git log -g:
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
It’s important to note that reflog information is strictly local — it’s a log only of what you’ve done in your repository.
The references won’t be the same on someone else’s copy of the repository; also, right after you initially clone a repository, you’ll have an empty reflog, as no activity has occurred yet in your repository.
Running git show HEAD@{2.months.ago} will show you the matching commit only if you cloned the project at least two months ago — if you cloned it any more recently than that, you’ll see only your first local commit.
Think of the reflog as Git’s version of shell history
If you have a UNIX or Linux background, you can think of the reflog as Git’s version of shell history, which emphasizes that what’s there is clearly relevant only for you and your ``session'', and has nothing to do with anyone else who might be working on the same machine.
Ancestry References
The other main way to specify a commit is via its ancestry.
If you place a ^ (caret) at the end of a reference, Git resolves it to mean the parent of that commit.
Suppose you look at the history of your project:
$ git log --pretty=format:'%h %s' --graph * 734713b fixed refs handling, added gc auto, updated tests * d921970 Merge commit 'phedders/rdocs' |\ | * 35cfb2b Some rdoc changes * | 1c002dd added some blame and merge stuff |/ * 1c36188 ignore *.gem * 9b29157 add open3_detach to gemspec file list
Then, you can see the previous commit by specifying HEAD^, which means ``the parent of HEAD'':
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Escaping the caret on Windows
On Windows in cmd.exe, ^ is a special character and needs to be treated differently.
You can either double it or put the commit reference in quotes:
$ git show HEAD^ # will NOT work on Windows $ git show HEAD^^ # OK $ git show "HEAD^" # OK
You can also specify a number after the ^ to identify which parent you want; for example, d921970^2 means `the second parent of d921970.''
This syntax is useful only for merge commits, which have more than one parent — the first parent of a merge commit is from the branch you were on when you merged (frequently `master), while the second parent of a merge commit is from the branch that was merged (say, topic):
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
Some rdoc changes
The other main ancestry specification is the ~ (tilde).
This also refers to the first parent, so HEAD~ and HEAD^ are equivalent.
The difference becomes apparent when you specify a number.
HEAD~2 means the first parent of the first parent,'' or the grandparent'' — it traverses the first parents the number of times you specify.
For example, in the history listed earlier, HEAD~3 would be
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
This can also be written HEAD~, which again is the first parent of the first parent of the first parent:
$ git show HEAD~~~
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
You can also combine these syntaxes — you can get the second parent of the previous reference (assuming it was a merge commit) by using HEAD~3^2, and so on.
Commit Ranges
Now that you can specify individual commits, let’s see how to specify ranges of commits. This is particularly useful for managing your branches — if you have a lot of branches, you can use range specifications to answer questions such as, ``What work is on this branch that I haven’t yet merged into my main branch?''
Double Dot
The most common range specification is the double-dot syntax. This basically asks Git to resolve a range of commits that are reachable from one commit but aren’t reachable from another. For example, say you have a commit history that looks like Example history for range selection..

Say you want to see what is in your experiment branch that hasn’t yet been merged into your master branch.
You can ask Git to show you a log of just those commits with master..experiment — that means `all commits reachable from `experiment that aren’t reachable from master.''
For the sake of brevity and clarity in these examples, the letters of the commit objects from the diagram are used in place of the actual log output in the order that they would display:
$ git log master..experiment D C
If, on the other hand, you want to see the opposite — all commits in master that aren’t in experiment — you can reverse the branch names.
experiment..master shows you everything in master not reachable from experiment:
$ git log experiment..master F E
This is useful if you want to keep the experiment branch up to date and preview what you’re about to merge.
Another frequent use of this syntax is to see what you’re about to push to a remote:
$ git log origin/master..HEAD
This command shows you any commits in your current branch that aren’t in the master branch on your origin remote.
If you run a git push and your current branch is tracking origin/master, the commits listed by git log origin/master..HEAD are the commits that will be transferred to the server.
You can also leave off one side of the syntax to have Git assume HEAD.
For example, you can get the same results as in the previous example by typing git log origin/master.. — Git substitutes HEAD if one side is missing.
Multiple Points
The double-dot syntax is useful as a shorthand, but perhaps you want to specify more than two branches to indicate your revision, such as seeing what commits are in any of several branches that aren’t in the branch you’re currently on.
Git allows you to do this by using either the ^ character or --not before any reference from which you don’t want to see reachable commits.
Thus, the following three commands are equivalent:
$ git log refA..refB $ git log ^refA refB $ git log refB --not refA
This is nice because with this syntax you can specify more than two references in your query, which you cannot do with the double-dot syntax.
For instance, if you want to see all commits that are reachable from refA or refB but not from refC, you can use either of:
$ git log refA refB ^refC $ git log refA refB --not refC
This makes for a very powerful revision query system that should help you figure out what is in your branches.
Triple Dot
The last major range-selection syntax is the triple-dot syntax, which specifies all the commits that are reachable by either of two references but not by both of them.
Look back at the example commit history in Example history for range selection..
If you want to see what is in master or experiment but not any common references, you can run:
$ git log master...experiment F E D C
Again, this gives you normal log output but shows you only the commit information for those four commits, appearing in the traditional commit date ordering.
A common switch to use with the log command in this case is --left-right, which shows you which side of the range each commit is in.
This helps make the output more useful:
$ git log --left-right master...experiment < F < E > D > C
With these tools, you can much more easily let Git know what commit or commits you want to inspect.
Interactive Staging
In this section, you’ll look at a few interactive Git commands that can help you craft your commits to include only certain combinations and parts of files. These tools are helpful if you modify a number of files extensively, then decide that you want those changes to be partitioned into several focused commits rather than one big messy commit. This way, you can make sure your commits are logically separate changesets and can be reviewed easily by the developers working with you.
If you run git add with the -i or --interactive option, Git enters an interactive shell mode, displaying something like this:
$ git add -i
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now>
You can see that this command shows you a much different view of your staging area than you’re probably used to — basically, the same information you get with git status but a bit more succinct and informative.
It lists the changes you’ve staged on the left and unstaged changes on the right.
After this comes a ``Commands'' section, which allows you to do a number of things like staging and unstaging files, staging parts of files, adding untracked files, and displaying diffs of what has been staged.
Staging and Unstaging Files
If you type u or 2 (for update) at the What now> prompt, you’re prompted for which files you want to stage:
What now> u
staged unstaged path
1: unchanged +0/-1 TODO
2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>
To stage the TODO and index.html files, you can type the numbers:
Update>> 1,2
staged unstaged path
* 1: unchanged +0/-1 TODO
* 2: unchanged +1/-1 index.html
3: unchanged +5/-1 lib/simplegit.rb
Update>>
The * next to each file means the file is selected to be staged.
If you press Enter after typing nothing at the Update>> prompt, Git takes anything selected and stages it for you:
Update>>
updated 2 paths
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now> s
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Now you can see that the TODO and index.html files are staged and the simplegit.rb file is still unstaged.
If you want to unstage the TODO file at this point, you use the r or 3 (for revert) option:
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now> r
staged unstaged path
1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> 1
staged unstaged path
* 1: +0/-1 nothing TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
Revert>> [enter]
reverted one path
Looking at your Git status again, you can see that you’ve unstaged the TODO file:
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now> s
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: unchanged +5/-1 lib/simplegit.rb
To see the diff of what you’ve staged, you can use the d or 6 (for diff) command.
It shows you a list of your staged files, and you can select the ones for which you would like to see the staged diff.
This is much like specifying git diff --cached on the command line:
*** Commands ***
1: [s]tatus 2: [u]pdate 3: [r]evert 4: [a]dd untracked
5: [p]atch 6: [d]iff 7: [q]uit 8: [h]elp
What now> d
staged unstaged path
1: +1/-1 nothing index.html
Review diff>> 1
diff --git a/index.html b/index.html
index 4d07108..4335f49 100644
--- a/index.html
+++ b/index.html
@@ -16,7 +16,7 @@ Date Finder
<p id="out">...</p>
-<div id="footer">contact : support@github.com</div>
+<div id="footer">contact : email.support@github.com</div>
<script type="text/javascript">
With these basic commands, you can use the interactive add mode to deal with your staging area a little more easily.
Staging Patches
It’s also possible for Git to stage certain parts of files and not the rest.
For example, if you make two changes to your simplegit.rb file and want to stage one of them and not the other, doing so is very easy in Git.
From the same interactive prompt explained in the previous section, type p or 5 (for patch).
Git will ask you which files you would like to partially stage; then, for each section of the selected files, it will display hunks of the file diff and ask if you would like to stage them, one by one:
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index dd5ecc4..57399e0 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -22,7 +22,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log -n 25 #{treeish}")
+ command("git log -n 30 #{treeish}")
end
def blame(path)
Stage this hunk [y,n,a,d,/,j,J,g,e,?]?
You have a lot of options at this point.
Typing ? shows a list of what you can do:
Stage this hunk [y,n,a,d,/,j,J,g,e,?]? ? y - stage this hunk n - do not stage this hunk a - stage this and all the remaining hunks in the file d - do not stage this hunk nor any of the remaining hunks in the file g - select a hunk to go to / - search for a hunk matching the given regex j - leave this hunk undecided, see next undecided hunk J - leave this hunk undecided, see next hunk k - leave this hunk undecided, see previous undecided hunk K - leave this hunk undecided, see previous hunk s - split the current hunk into smaller hunks e - manually edit the current hunk ? - print help
Generally, you’ll type y or n if you want to stage each hunk, but staging all of them in certain files or skipping a hunk decision until later can be helpful too.
If you stage one part of the file and leave another part unstaged, your status output will look like this:
What now> 1
staged unstaged path
1: unchanged +0/-1 TODO
2: +1/-1 nothing index.html
3: +1/-1 +4/-0 lib/simplegit.rb
The status of the simplegit.rb file is interesting.
It shows you that a couple of lines are staged and a couple are unstaged.
You’ve partially staged this file.
At this point, you can exit the interactive adding script and run git commit to commit the partially staged files.
You also don’t need to be in interactive add mode to do the partial-file staging — you can start the same script by using git add -p or git add --patch on the command line.
Furthermore, you can use patch mode for partially resetting files with the git reset --patch command, for checking out parts of files with the git checkout --patch command and for stashing parts of files with the git stash save --patch command.
We’ll go into more details on each of these as we get to more advanced usages of these commands.
Stashing and Cleaning
Often, when you’ve been working on part of your project, things are in a messy state and you want to switch branches for a bit to work on something else.
The problem is, you don’t want to do a commit of half-done work just so you can get back to this point later.
The answer to this issue is the git stash command.
Stashing takes the dirty state of your working directory — that is, your modified tracked files and staged changes — and saves it on a stack of unfinished changes that you can reapply at any time (even on a different branch).
Migrating to git stash push
As of late October 2017, there has been extensive discussion on the Git mailing list, wherein the command git stash save is being deprecated in favour of the existing alternative git stash push.
The main reason for this is that git stash push introduces the option of stashing selected pathspecs, something git stash save does not support.
git stash save is not going away any time soon, so don’t worry about it suddenly disappearing.
But you might want to start migrating over to the push alternative for the new functionality.
Stashing Your Work
To demonstrate stashing, you’ll go into your project and start working on a couple of files and possibly stage one of the changes.
If you run git status, you can see your dirty state:
$ git status Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: index.html Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: lib/simplegit.rb
Now you want to switch branches, but you don’t want to commit what you’ve been working on yet, so you’ll stash the changes.
To push a new stash onto your stack, run git stash or git stash push:
$ git stash Saved working directory and index state \ "WIP on master: 049d078 added the index file" HEAD is now at 049d078 added the index file (To restore them type "git stash apply")
You can now see that your working directory is clean:
$ git status # On branch master nothing to commit, working directory clean
At this point, you can switch branches and do work elsewhere; your changes are stored on your stack.
To see which stashes you’ve stored, you can use git stash list:
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051 Revert "added file_size"
stash@{2}: WIP on master: 21d80a5 added number to log
In this case, two stashes were saved previously, so you have access to three different stashed works.
You can reapply the one you just stashed by using the command shown in the help output of the original stash command: git stash apply.
If you want to apply one of the older stashes, you can specify it by naming it, like this: git stash apply stash@{2}.
If you don’t specify a stash, Git assumes the most recent stash and tries to apply it:
$ git stash apply On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: index.html modified: lib/simplegit.rb no changes added to commit (use "git add" and/or "git commit -a")
You can see that Git re-modifies the files you reverted when you saved the stash. In this case, you had a clean working directory when you tried to apply the stash, and you tried to apply it on the same branch you saved it from. Having a clean working directory and applying it on the same branch aren’t necessary to successfully apply a stash. You can save a stash on one branch, switch to another branch later, and try to reapply the changes. You can also have modified and uncommitted files in your working directory when you apply a stash — Git gives you merge conflicts if anything no longer applies cleanly.
The changes to your files were reapplied, but the file you staged before wasn’t restaged.
To do that, you must run the git stash apply command with a --index option to tell the command to try to reapply the staged changes.
If you had run that instead, you’d have gotten back to your original position:
$ git stash apply --index On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage) modified: index.html Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: lib/simplegit.rb
The apply option only tries to apply the stashed work — you continue to have it on your stack.
To remove it, you can run git stash drop with the name of the stash to remove:
$ git stash list
stash@{0}: WIP on master: 049d078 added the index file
stash@{1}: WIP on master: c264051 Revert "added file_size"
stash@{2}: WIP on master: 21d80a5 added number to log
$ git stash drop stash@{0}
Dropped stash@{0} (364e91f3f268f0900bc3ee613f9f733e82aaed43)
You can also run git stash pop to apply the stash and then immediately drop it from your stack.
Creative Stashing
There are a few stash variants that may also be helpful.
The first option that is quite popular is the --keep-index option to the git stash command.
This tells Git to not only include all staged content in the stash being created, but simultaneously leave it in the index.
$ git status -s M index.html M lib/simplegit.rb $ git stash --keep-index Saved working directory and index state WIP on master: 1b65b17 added the index file HEAD is now at 1b65b17 added the index file $ git status -s M index.html
Another common thing you may want to do with stash is to stash the untracked files as well as the tracked ones.
By default, git stash will stash only modified and staged tracked files.
If you specify --include-untracked or -u, Git will include untracked files in the stash being created.
However, including untracked files in the stash will still not include explicitly ignored files; to additionally include ignored files, use --all (or just -a).
$ git status -s M index.html M lib/simplegit.rb ?? new-file.txt $ git stash -u Saved working directory and index state WIP on master: 1b65b17 added the index file HEAD is now at 1b65b17 added the index file $ git status -s $
Finally, if you specify the --patch flag, Git will not stash everything that is modified but will instead prompt you interactively which of the changes you would like to stash and which you would like to keep in your working directory.
$ git stash --patch
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 66d332e..8bb5674 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -16,6 +16,10 @@ class SimpleGit
return `#{git_cmd} 2>&1`.chomp
end
end
+
+ def show(treeish = 'master')
+ command("git show #{treeish}")
+ end
end
test
Stash this hunk [y,n,q,a,d,/,e,?]? y
Saved working directory and index state WIP on master: 1b65b17 added the index file
Creating a Branch from a Stash
If you stash some work, leave it there for a while, and continue on the branch from which you stashed the work, you may have a problem reapplying the work.
If the apply tries to modify a file that you’ve since modified, you’ll get a merge conflict and will have to try to resolve it.
If you want an easier way to test the stashed changes again, you can run git stash branch <new branchname>, which creates a new branch for you with your selected branch name, checks out the commit you were on when you stashed your work, reapplies your work there, and then drops the stash if it applies successfully:
$ git stash branch testchanges
M index.html
M lib/simplegit.rb
Switched to a new branch 'testchanges'
On branch testchanges
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: index.html
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: lib/simplegit.rb
Dropped refs/stash@{0} (29d385a81d163dfd45a452a2ce816487a6b8b014)
This is a nice shortcut to recover stashed work easily and work on it in a new branch.
Cleaning your Working Directory
Finally, you may not want to stash some work or files in your working directory, but simply get rid of them; that’s what the git clean command is for.
Some common reasons for cleaning your working directory might be to remove cruft that has been generated by merges or external tools or to remove build artifacts in order to run a clean build.
You’ll want to be pretty careful with this command, since it’s designed to remove files from your working directory that are not tracked.
If you change your mind, there is often no retrieving the content of those files.
A safer option is to run git stash --all to remove everything but save it in a stash.
Assuming you do want to remove cruft files or clean your working directory, you can do so with git clean.
To remove all the untracked files in your working directory, you can run git clean -f -d, which removes any files and also any subdirectories that become empty as a result.
The -f means 'force' or `really do this,'' and is required if the Git configuration variable `clean.requireForce is not explicitly set to false.
If you ever want to see what it would do, you can run the command with the --dry-run (or -n) option, which means ``do a dry run and tell me what you would have removed''.
$ git clean -d -n Would remove test.o Would remove tmp/
By default, the git clean command will only remove untracked files that are not ignored.
Any file that matches a pattern in your .gitignore or other ignore files will not be removed.
If you want to remove those files too, such as to remove all .o files generated from a build so you can do a fully clean build, you can add a -x to the clean command.
$ git status -s M lib/simplegit.rb ?? build.TMP ?? tmp/ $ git clean -n -d Would remove build.TMP Would remove tmp/ $ git clean -n -d -x Would remove build.TMP Would remove test.o Would remove tmp/
If you don’t know what the git clean command is going to do, always run it with a -n first to double check before changing the -n to a -f and doing it for real.
The other way you can be careful about the process is to run it with the -i or ``interactive'' flag.
This will run the clean command in an interactive mode.
$ git clean -x -i
Would remove the following items:
build.TMP test.o
*** Commands ***
1: clean 2: filter by pattern 3: select by numbers 4: ask each 5: quit
6: help
What now>
This way you can step through each file individually or specify patterns for deletion interactively.
There is a quirky situation where you might need to be extra forceful in asking Git to clean your working directory.
If you happen to be in a working directory under which you’ve copied or cloned other Git repositories (perhaps as submodules), even git clean -fd will refuse to delete those directories.
In cases like that, you need to add a second -f option for emphasis.
Signing Your Work
Git is cryptographically secure, but it’s not foolproof. If you’re taking work from others on the internet and want to verify that commits are actually from a trusted source, Git has a few ways to sign and verify work using GPG.
GPG Introduction
First of all, if you want to sign anything you need to get GPG configured and your personal key installed.
$ gpg --list-keys /Users/schacon/.gnupg/pubring.gpg --------------------------------- pub 2048R/0A46826A 2014-06-04 uid Scott Chacon (Git signing key) <schacon@gmail.com> sub 2048R/874529A9 2014-06-04
If you don’t have a key installed, you can generate one with gpg --gen-key.
$ gpg --gen-key
Once you have a private key to sign with, you can configure Git to use it for signing things by setting the user.signingkey config setting.
$ git config --global user.signingkey 0A46826A
Now Git will use your key by default to sign tags and commits if you want.
Signing Tags
If you have a GPG private key setup, you can now use it to sign new tags.
All you have to do is use -s instead of -a:
$ git tag -s v1.5 -m 'my signed 1.5 tag' You need a passphrase to unlock the secret key for user: "Ben Straub <ben@straub.cc>" 2048-bit RSA key, ID 800430EB, created 2014-05-04
If you run git show on that tag, you can see your GPG signature attached to it:
$ git show v1.5
tag v1.5
Tagger: Ben Straub <ben@straub.cc>
Date: Sat May 3 20:29:41 2014 -0700
my signed 1.5 tag
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1
iQEcBAABAgAGBQJTZbQlAAoJEF0+sviABDDrZbQH/09PfE51KPVPlanr6q1v4/Ut
LQxfojUWiLQdg2ESJItkcuweYg+kc3HCyFejeDIBw9dpXt00rY26p05qrpnG+85b
hM1/PswpPLuBSr+oCIDj5GMC2r2iEKsfv2fJbNW8iWAXVLoWZRF8B0MfqX/YTMbm
ecorc4iXzQu7tupRihslbNkfvfciMnSDeSvzCpWAHl7h8Wj6hhqePmLm9lAYqnKp
8S5B/1SSQuEAjRZgI4IexpZoeKGVDptPHxLLS38fozsyi0QyDyzEgJxcJQVMXxVi
RUysgqjcpT8+iQM1PblGfHR4XAhuOqN5Fx06PSaFZhqvWFezJ28/CLyX5q+oIVk=
=EFTF
-----END PGP SIGNATURE-----
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700
changed the version number
Verifying Tags
To verify a signed tag, you use git tag -v <tag-name>.
This command uses GPG to verify the signature.
You need the signer’s public key in your keyring for this to work properly:
$ git tag -v v1.4.2.1 object 883653babd8ee7ea23e6a5c392bb739348b1eb61 type commit tag v1.4.2.1 tagger Junio C Hamano <junkio@cox.net> 1158138501 -0700 GIT 1.4.2.1 Minor fixes since 1.4.2, including git-mv and git-http with alternates. gpg: Signature made Wed Sep 13 02:08:25 2006 PDT using DSA key ID F3119B9A gpg: Good signature from "Junio C Hamano <junkio@cox.net>" gpg: aka "[jpeg image of size 1513]" Primary key fingerprint: 3565 2A26 2040 E066 C9A7 4A7D C0C6 D9A4 F311 9B9A
If you don’t have the signer’s public key, you get something like this instead:
gpg: Signature made Wed Sep 13 02:08:25 2006 PDT using DSA key ID F3119B9A gpg: Can't check signature: public key not found error: could not verify the tag 'v1.4.2.1'
Signing Commits
In more recent versions of Git (v1.7.9 and above), you can now also sign individual commits.
If you’re interested in signing commits directly instead of just the tags, all you need to do is add a -S to your git commit command.
$ git commit -a -S -m 'signed commit' You need a passphrase to unlock the secret key for user: "Scott Chacon (Git signing key) <schacon@gmail.com>" 2048-bit RSA key, ID 0A46826A, created 2014-06-04 [master 5c3386c] signed commit 4 files changed, 4 insertions(+), 24 deletions(-) rewrite Rakefile (100%) create mode 100644 lib/git.rb
To see and verify these signatures, there is also a --show-signature option to git log.
$ git log --show-signature -1
commit 5c3386cf54bba0a33a32da706aa52bc0155503c2
gpg: Signature made Wed Jun 4 19:49:17 2014 PDT using RSA key ID 0A46826A
gpg: Good signature from "Scott Chacon (Git signing key) <schacon@gmail.com>"
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Jun 4 19:49:17 2014 -0700
signed commit
Additionally, you can configure git log to check any signatures it finds and list them in its output with the %G? format.
$ git log --pretty="format:%h %G? %aN %s" 5c3386c G Scott Chacon signed commit ca82a6d N Scott Chacon changed the version number 085bb3b N Scott Chacon removed unnecessary test code a11bef0 N Scott Chacon first commit
Here we can see that only the latest commit is signed and valid and the previous commits are not.
In Git 1.8.3 and later, git merge and git pull can be told to inspect and reject when merging a commit that does not carry a trusted GPG signature with the --verify-signatures command.
If you use this option when merging a branch and it contains commits that are not signed and valid, the merge will not work.
$ git merge --verify-signatures non-verify fatal: Commit ab06180 does not have a GPG signature.
If the merge contains only valid signed commits, the merge command will show you all the signatures it has checked and then move forward with the merge.
$ git merge --verify-signatures signed-branch Commit 13ad65e has a good GPG signature by Scott Chacon (Git signing key) <schacon@gmail.com> Updating 5c3386c..13ad65e Fast-forward README | 2 ++ 1 file changed, 2 insertions(+)
You can also use the -S option with the git merge command to sign the resulting merge commit itself.
The following example both verifies that every commit in the branch to be merged is signed and furthermore signs the resulting merge commit.
$ git merge --verify-signatures -S signed-branch Commit 13ad65e has a good GPG signature by Scott Chacon (Git signing key) <schacon@gmail.com> You need a passphrase to unlock the secret key for user: "Scott Chacon (Git signing key) <schacon@gmail.com>" 2048-bit RSA key, ID 0A46826A, created 2014-06-04 Merge made by the 'recursive' strategy. README | 2 ++ 1 file changed, 2 insertions(+)
Everyone Must Sign
Signing tags and commits is great, but if you decide to use this in your normal workflow, you’ll have to make sure that everyone on your team understands how to do so. If you don’t, you’ll end up spending a lot of time helping people figure out how to rewrite their commits with signed versions. Make sure you understand GPG and the benefits of signing things before adopting this as part of your standard workflow.
Searching
With just about any size codebase, you’ll often need to find where a function is called or defined, or display the history of a method. Git provides a couple of useful tools for looking through the code and commits stored in its database quickly and easily. We’ll go through a few of them.
Git Grep
Git ships with a command called grep that allows you to easily search through any committed tree, the working directory, or even the index for a string or regular expression.
For the examples that follow, we’ll search through the source code for Git itself.
By default, git grep will look through the files in your working directory.
As a first variation, you can use either of the -n or --line-number options to print out the line numbers where Git has found matches:
$ git grep -n gmtime_r
compat/gmtime.c:3:#undef gmtime_r
compat/gmtime.c:8: return git_gmtime_r(timep, &result);
compat/gmtime.c:11:struct tm *git_gmtime_r(const time_t *timep, struct tm *result)
compat/gmtime.c:16: ret = gmtime_r(timep, result);
compat/mingw.c:826:struct tm *gmtime_r(const time_t *timep, struct tm *result)
compat/mingw.h:206:struct tm *gmtime_r(const time_t *timep, struct tm *result);
date.c:482: if (gmtime_r(&now, &now_tm))
date.c:545: if (gmtime_r(&time, tm)) {
date.c:758: /* gmtime_r() in match_digit() may have clobbered it */
git-compat-util.h:1138:struct tm *git_gmtime_r(const time_t *, struct tm *);
git-compat-util.h:1140:#define gmtime_r git_gmtime_r
In addition to the basic search shown above, git grep supports a plethora of other interesting options.
For instance, instead of printing all of the matches, you can ask git grep to summarize the output by showing you only which files contained the search string and how many matches there were in each file with the -c or --count option:
$ git grep --count gmtime_r compat/gmtime.c:4 compat/mingw.c:1 compat/mingw.h:1 date.c:3 git-compat-util.h:2
If you’re interested in the context of a search string, you can display the enclosing method or function for each matching string with either of the -p or --show-function options:
$ git grep -p gmtime_r *.c
date.c=static int match_multi_number(timestamp_t num, char c, const char *date,
date.c: if (gmtime_r(&now, &now_tm))
date.c=static int match_digit(const char *date, struct tm *tm, int *offset, int *tm_gmt)
date.c: if (gmtime_r(&time, tm)) {
date.c=int parse_date_basic(const char *date, timestamp_t *timestamp, int *offset)
date.c: /* gmtime_r() in match_digit() may have clobbered it */
As you can see, the gmtime_r routine is called from both the match_multi_number and match_digit functions in the date.c file (the third match displayed represents just the string appearing in a comment).
You can also search for complex combinations of strings with the --and flag, which ensures that multiple matches must occur in the same line of text.
For instance, let’s look for any lines that define a constant whose name contains either of the substrings LINK'' or BUF_MAX'', specifically in an older version of the Git codebase represented by the tag v1.8.0 (we’ll throw in the --break and --heading options which help split up the output into a more readable format):
$ git grep --break --heading \
-n -e '#define' --and \( -e LINK -e BUF_MAX \) v1.8.0
v1.8.0:builtin/index-pack.c
62:#define FLAG_LINK (1u<<20)
v1.8.0:cache.h
73:#define S_IFGITLINK 0160000
74:#define S_ISGITLINK(m) (((m) & S_IFMT) == S_IFGITLINK)
v1.8.0:environment.c
54:#define OBJECT_CREATION_MODE OBJECT_CREATION_USES_HARDLINKS
v1.8.0:strbuf.c
326:#define STRBUF_MAXLINK (2*PATH_MAX)
v1.8.0:symlinks.c
53:#define FL_SYMLINK (1 << 2)
v1.8.0:zlib.c
30:/* #define ZLIB_BUF_MAX ((uInt)-1) */
31:#define ZLIB_BUF_MAX ((uInt) 1024 * 1024 * 1024) /* 1GB */
The git grep command has a few advantages over normal searching commands like grep and ack.
The first is that it’s really fast, the second is that you can search through any tree in Git, not just the working directory.
As we saw in the above example, we looked for terms in an older version of the Git source code, not the version that was currently checked out.
Git Log Searching
Perhaps you’re looking not for where a term exists, but when it existed or was introduced.
The git log command has a number of powerful tools for finding specific commits by the content of their messages or even the content of the diff they introduce.
If, for example, we want to find out when the ZLIB_BUF_MAX constant was originally introduced, we can use the -S option (colloquially referred to as the Git ``pickaxe'' option) to tell Git to show us only those commits that changed the number of occurrences of that string.
$ git log -S ZLIB_BUF_MAX --oneline e01503b zlib: allow feeding more than 4GB in one go ef49a7a zlib: zlib can only process 4GB at a time
If we look at the diff of those commits, we can see that in ef49a7a the constant was introduced and in e01503b it was modified.
If you need to be more specific, you can provide a regular expression to search for with the -G option.
Line Log Search
Another fairly advanced log search that is insanely useful is the line history search.
Simply run git log with the -L option, and it will show you the history of a function or line of code in your codebase.
For example, if we wanted to see every change made to the function git_deflate_bound in the zlib.c file, we could run git log -L :git_deflate_bound:zlib.c.
This will try to figure out what the bounds of that function are and then look through the history and show us every change that was made to the function as a series of patches back to when the function was first created.
$ git log -L :git_deflate_bound:zlib.c
commit ef49a7a0126d64359c974b4b3b71d7ad42ee3bca
Author: Junio C Hamano <gitster@pobox.com>
Date: Fri Jun 10 11:52:15 2011 -0700
zlib: zlib can only process 4GB at a time
diff --git a/zlib.c b/zlib.c
--- a/zlib.c
+++ b/zlib.c
@@ -85,5 +130,5 @@
-unsigned long git_deflate_bound(z_streamp strm, unsigned long size)
+unsigned long git_deflate_bound(git_zstream *strm, unsigned long size)
{
- return deflateBound(strm, size);
+ return deflateBound(&strm->z, size);
}
commit 225a6f1068f71723a910e8565db4e252b3ca21fa
Author: Junio C Hamano <gitster@pobox.com>
Date: Fri Jun 10 11:18:17 2011 -0700
zlib: wrap deflateBound() too
diff --git a/zlib.c b/zlib.c
--- a/zlib.c
+++ b/zlib.c
@@ -81,0 +85,5 @@
+unsigned long git_deflate_bound(z_streamp strm, unsigned long size)
+{
+ return deflateBound(strm, size);
+}
+
If Git can’t figure out how to match a function or method in your programming language, you can also provide it with a regular expression (or regex).
For example, this would have done the same thing as the example above: git log -L '/unsigned long git_deflate_bound/',/^}/:zlib.c.
You could also give it a range of lines or a single line number and you’ll get the same sort of output.
Rewriting History
Many times, when working with Git, you may want to revise your local commit history.
One of the great things about Git is that it allows you to make decisions at the last possible moment.
You can decide what files go into which commits right before you commit with the staging area, you can decide that you didn’t mean to be working on something yet with git stash, and you can rewrite commits that already happened so they look like they happened in a different way.
This can involve changing the order of the commits, changing messages or modifying files in a commit, squashing together or splitting apart commits, or removing commits entirely — all before you share your work with others.
In this section, you’ll see how to accomplish these tasks so that you can make your commit history look the way you want before you share it with others.
Don’t push your work until you’re happy with it
One of the cardinal rules of Git is that, since so much work is local within your clone, you have a great deal of freedom to rewrite your history locally. However, once you push your work, it is a different story entirely, and you should consider pushed work as final unless you have good reason to change it. In short, you should avoid pushing your work until you’re happy with it and ready to share it with the rest of the world.
Changing the Last Commit
Changing your most recent commit is probably the most common rewriting of history that you’ll do. You’ll often want to do two basic things to your last commit: simply change the commit message, or change the actual content of the commit by adding, removing and modifying files.
If you simply want to modify your last commit message, that’s easy:
$ git commit --amend
The command above loads the previous commit message into an editor session, where you can make changes to the message, save those changes and exit. When you save and close the editor, the editor writes a new commit containing that updated commit message and makes it your new last commit.
If, on the other hand, you want to change the actual content of your last commit, the process works basically the same way — first make the changes you think you forgot, stage those changes, and the subsequent git commit --amend replaces that last commit with your new, improved commit.
You need to be careful with this technique because amending changes the SHA-1 of the commit. It’s like a very small rebase — don’t amend your last commit if you’ve already pushed it.
An amended commit may (or may not) need an amended commit message
When you amend a commit, you have the opportunity to change both the commit message and the content of the commit. If you amend the content of the commit substantially, you should almost certainly update the commit message to reflect that amended content.
On the other hand, if your amendments are suitably trivial (fixing a silly typo or adding a file you forgot to stage) such that the earlier commit message is just fine, you can simply make the changes, stage them, and avoid the unnecessary editor session entirely with:
$ git commit --amend --no-edit
Changing Multiple Commit Messages
To modify a commit that is farther back in your history, you must move to more complex tools.
Git doesn’t have a modify-history tool, but you can use the rebase tool to rebase a series of commits onto the HEAD they were originally based on instead of moving them to another one.
With the interactive rebase tool, you can then stop after each commit you want to modify and change the message, add files, or do whatever you wish.
You can run rebase interactively by adding the -i option to git rebase.
You must indicate how far back you want to rewrite commits by telling the command which commit to rebase onto.
For example, if you want to change the last three commit messages, or any of the commit messages in that group, you supply as an argument to git rebase -i the parent of the last commit you want to edit, which is HEAD~2^ or HEAD~3.
It may be easier to remember the ~3 because you’re trying to edit the last three commits, but keep in mind that you’re actually designating four commits ago, the parent of the last commit you want to edit:
$ git rebase -i HEAD~3
Remember again that this is a rebasing command — every commit in the range HEAD~3..HEAD with a changed message and all of its descendants will be rewritten.
Don’t include any commit you’ve already pushed to a central server — doing so will confuse other developers by providing an alternate version of the same change.
Running this command gives you a list of commits in your text editor that looks something like this:
pick f7f3f6d changed my name a bit pick 310154e updated README formatting and added blame pick a5f4a0d added cat-file # Rebase 710f0f8..a5f4a0d onto 710f0f8 # # Commands: # p, pick <commit> = use commit # r, reword <commit> = use commit, but edit the commit message # e, edit <commit> = use commit, but stop for amending # s, squash <commit> = use commit, but meld into previous commit # f, fixup <commit> = like "squash", but discard this commit's log message # x, exec <command> = run command (the rest of the line) using shell # b, break = stop here (continue rebase later with 'git rebase --continue') # d, drop <commit> = remove commit # l, label <label> = label current HEAD with a name # t, reset <label> = reset HEAD to a label # m, merge [-C <commit> | -c <commit>] <label> [# <oneline>] # . create a merge commit using the original merge commit's # . message (or the oneline, if no original merge commit was # . specified). Use -c <commit> to reword the commit message. # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. # # Note that empty commits are commented out
It’s important to note that these commits are listed in the opposite order than you normally see them using the log command.
If you run a log, you see something like this:
$ git log --pretty=format:"%h %s" HEAD~3..HEAD a5f4a0d added cat-file 310154e updated README formatting and added blame f7f3f6d changed my name a bit
Notice the reverse order.
The interactive rebase gives you a script that it’s going to run.
It will start at the commit you specify on the command line (HEAD~3) and replay the changes introduced in each of these commits from top to bottom.
It lists the oldest at the top, rather than the newest, because that’s the first one it will replay.
You need to edit the script so that it stops at the commit you want to edit. To do so, change the word `pick' to the word `edit' for each of the commits you want the script to stop after. For example, to modify only the third commit message, you change the file to look like this:
edit f7f3f6d changed my name a bit pick 310154e updated README formatting and added blame pick a5f4a0d added cat-file
When you save and exit the editor, Git rewinds you back to the last commit in that list and drops you on the command line with the following message:
$ git rebase -i HEAD~3
Stopped at f7f3f6d... changed my name a bit
You can amend the commit now, with
git commit --amend
Once you're satisfied with your changes, run
git rebase --continue
These instructions tell you exactly what to do. Type
$ git commit --amend
Change the commit message, and exit the editor. Then, run
$ git rebase --continue
This command will apply the other two commits automatically, and then you’re done. If you change pick to edit on more lines, you can repeat these steps for each commit you change to edit. Each time, Git will stop, let you amend the commit, and continue when you’re finished.
Reordering Commits
You can also use interactive rebases to reorder or remove commits entirely. If you want to remove the ``added cat-file'' commit and change the order in which the other two commits are introduced, you can change the rebase script from this
pick f7f3f6d changed my name a bit pick 310154e updated README formatting and added blame pick a5f4a0d added cat-file
to this:
pick 310154e updated README formatting and added blame pick f7f3f6d changed my name a bit
When you save and exit the editor, Git rewinds your branch to the parent of these commits, applies 310154e and then f7f3f6d, and then stops.
You effectively change the order of those commits and remove the ``added cat-file'' commit completely.
Squashing Commits
It’s also possible to take a series of commits and squash them down into a single commit with the interactive rebasing tool. The script puts helpful instructions in the rebase message:
# # Commands: # p, pick <commit> = use commit # r, reword <commit> = use commit, but edit the commit message # e, edit <commit> = use commit, but stop for amending # s, squash <commit> = use commit, but meld into previous commit # f, fixup <commit> = like "squash", but discard this commit's log message # x, exec <command> = run command (the rest of the line) using shell # b, break = stop here (continue rebase later with 'git rebase --continue') # d, drop <commit> = remove commit # l, label <label> = label current HEAD with a name # t, reset <label> = reset HEAD to a label # m, merge [-C <commit> | -c <commit>] <label> [# <oneline>] # . create a merge commit using the original merge commit's # . message (or the oneline, if no original merge commit was # . specified). Use -c <commit> to reword the commit message. # # These lines can be re-ordered; they are executed from top to bottom. # # If you remove a line here THAT COMMIT WILL BE LOST. # # However, if you remove everything, the rebase will be aborted. # # Note that empty commits are commented out
If, instead of pick'' or edit'', you specify ``squash'', Git applies both that change and the change directly before it and makes you merge the commit messages together.
So, if you want to make a single commit from these three commits, you make the script look like this:
pick f7f3f6d changed my name a bit squash 310154e updated README formatting and added blame squash a5f4a0d added cat-file
When you save and exit the editor, Git applies all three changes and then puts you back into the editor to merge the three commit messages:
# This is a combination of 3 commits. # The first commit's message is: changed my name a bit # This is the 2nd commit message: updated README formatting and added blame # This is the 3rd commit message: added cat-file
When you save that, you have a single commit that introduces the changes of all three previous commits.
Splitting a Commit
Splitting a commit undoes a commit and then partially stages and commits as many times as commits you want to end up with.
For example, suppose you want to split the middle commit of your three commits.
Instead of updated README formatting and added blame'', you want to split it into two commits: updated README formatting'' for the first, and added blame'' for the second.
You can do that in the edit'':rebase -i script by changing the instruction on the commit you want to split to
pick f7f3f6d changed my name a bit edit 310154e updated README formatting and added blame pick a5f4a0d added cat-file
Then, when the script drops you to the command line, you reset that commit, take the changes that have been reset, and create multiple commits out of them.
When you save and exit the editor, Git rewinds to the parent of the first commit in your list, applies the first commit (f7f3f6d), applies the second (310154e), and drops you to the console.
There, you can do a mixed reset of that commit with git reset HEAD^, which effectively undoes that commit and leaves the modified files unstaged.
Now you can stage and commit files until you have several commits, and run git rebase --continue when you’re done:
$ git reset HEAD^ $ git add README $ git commit -m 'updated README formatting' $ git add lib/simplegit.rb $ git commit -m 'added blame' $ git rebase --continue
Git applies the last commit (a5f4a0d) in the script, and your history looks like this:
$ git log -4 --pretty=format:"%h %s" 1c002dd added cat-file 9b29157 added blame 35cfb2b updated README formatting f3cc40e changed my name a bit
Once again, this changes the SHA-1s of all the commits in your list, so make sure no commit shows up in that list that you’ve already pushed to a shared repository.
The Nuclear Option: filter-branch
There is another history-rewriting option that you can use if you need to rewrite a larger number of commits in some scriptable way — for instance, changing your email address globally or removing a file from every commit.
The command is filter-branch, and it can rewrite huge swaths of your history, so you probably shouldn’t use it unless your project isn’t yet public and other people haven’t based work off the commits you’re about to rewrite.
However, it can be very useful.
You’ll learn a few of the common uses so you can get an idea of some of the things it’s capable of.
git filter-branch has many pitfalls, and is no longer the recommended way to rewrite history.
Instead, consider using git-filter-repo, which is a Python script that does a better job for most applications where you would normally turn to filter-branch.
Its documentation and source code can be found at https://github.com/newren/git-filter-repo.
Removing a File from Every Commit
This occurs fairly commonly.
Someone accidentally commits a huge binary file with a thoughtless git add ., and you want to remove it everywhere.
Perhaps you accidentally committed a file that contained a password, and you want to make your project open source.
filter-branch is the tool you probably want to use to scrub your entire history.
To remove a file named passwords.txt from your entire history, you can use the --tree-filter option to filter-branch:
$ git filter-branch --tree-filter 'rm -f passwords.txt' HEAD Rewrite 6b9b3cf04e7c5686a9cb838c3f36a8cb6a0fc2bd (21/21) Ref 'refs/heads/master' was rewritten
The --tree-filter option runs the specified command after each checkout of the project and then recommits the results.
In this case, you remove a file called passwords.txt from every snapshot, whether it exists or not.
If you want to remove all accidentally committed editor backup files, you can run something like git filter-branch --tree-filter 'rm -f *~' HEAD.
You’ll be able to watch Git rewriting trees and commits and then move the branch pointer at the end.
It’s generally a good idea to do this in a testing branch and then hard-reset your master branch after you’ve determined the outcome is what you really want.
To run filter-branch on all your branches, you can pass --all to the command.
Making a Subdirectory the New Root
Suppose you’ve done an import from another source control system and have subdirectories that make no sense (trunk, tags, and so on).
If you want to make the trunk subdirectory be the new project root for every commit, filter-branch can help you do that, too:
$ git filter-branch --subdirectory-filter trunk HEAD Rewrite 856f0bf61e41a27326cdae8f09fe708d679f596f (12/12) Ref 'refs/heads/master' was rewritten
Now your new project root is what was in the trunk subdirectory each time.
Git will also automatically remove commits that did not affect the subdirectory.
Changing Email Addresses Globally
Another common case is that you forgot to run git config to set your name and email address before you started working, or perhaps you want to open-source a project at work and change all your work email addresses to your personal address.
In any case, you can change email addresses in multiple commits in a batch with filter-branch as well.
You need to be careful to change only the email addresses that are yours, so you use --commit-filter:
$ git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" = "schacon@localhost" ];
then
GIT_AUTHOR_NAME="Scott Chacon";
GIT_AUTHOR_EMAIL="schacon@example.com";
git commit-tree "$@";
else
git commit-tree "$@";
fi' HEAD
This goes through and rewrites every commit to have your new address. Because commits contain the SHA-1 values of their parents, this command changes every commit SHA-1 in your history, not just those that have the matching email address.
Reset Demystified
Before moving on to more specialized tools, let’s talk about the Git reset and checkout commands.
These commands are two of the most confusing parts of Git when you first encounter them.
They do so many things that it seems hopeless to actually understand them and employ them properly.
For this, we recommend a simple metaphor.
The Three Trees
An easier way to think about reset and checkout is through the mental frame of Git being a content manager of three different trees.
By tree'' here, we really mean collection of files'', not specifically the data structure.
(There are a few cases where the index doesn’t exactly act like a tree, but for our purposes it is easier to think about it this way for now.)
Git as a system manages and manipulates three trees in its normal operation:
| Tree | Role |
|---|---|
| HEAD | Last commit snapshot, next parent |
| Index | Proposed next commit snapshot |
| Working Directory | Sandbox |
The HEAD
HEAD is the pointer to the current branch reference, which is in turn a pointer to the last commit made on that branch. That means HEAD will be the parent of the next commit that is created. It’s generally simplest to think of HEAD as the snapshot of your last commit on that branch.
In fact, it’s pretty easy to see what that snapshot looks like. Here is an example of getting the actual directory listing and SHA-1 checksums for each file in the HEAD snapshot:
$ git cat-file -p HEAD tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf author Scott Chacon 1301511835 -0700 committer Scott Chacon 1301511835 -0700 initial commit $ git ls-tree -r HEAD 100644 blob a906cb2a4a904a152... README 100644 blob 8f94139338f9404f2... Rakefile 040000 tree 99f1a6d12cb4b6f19... lib
The Git cat-file and ls-tree commands are ``plumbing'' commands that are used for lower level things and not really used in day-to-day work, but they help us see what’s going on here.
The Index
The index is your proposed next commit.
We’ve also been referring to this concept as Git’s `Staging Area'' as this is what Git looks at when you run `git commit.
Git populates this index with a list of all the file contents that were last checked out into your working directory and what they looked like when they were originally checked out.
You then replace some of those files with new versions of them, and git commit converts that into the tree for a new commit.
$ git ls-files -s 100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README 100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile 100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rb
Again, here we’re using git ls-files, which is more of a behind the scenes command that shows you what your index currently looks like.
The index is not technically a tree structure — it’s actually implemented as a flattened manifest — but for our purposes it’s close enough.
The Working Directory
Finally, you have your working directory (also commonly referred to as the `working tree'').
The other two trees store their content in an efficient but inconvenient manner, inside the `.git folder.
The working directory unpacks them into actual files, which makes it much easier for you to edit them.
Think of the working directory as a sandbox, where you can try changes out before committing them to your staging area (index) and then to history.
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 files
The Workflow
Git’s typical workflow is to record snapshots of your project in successively better states, by manipulating these three trees.
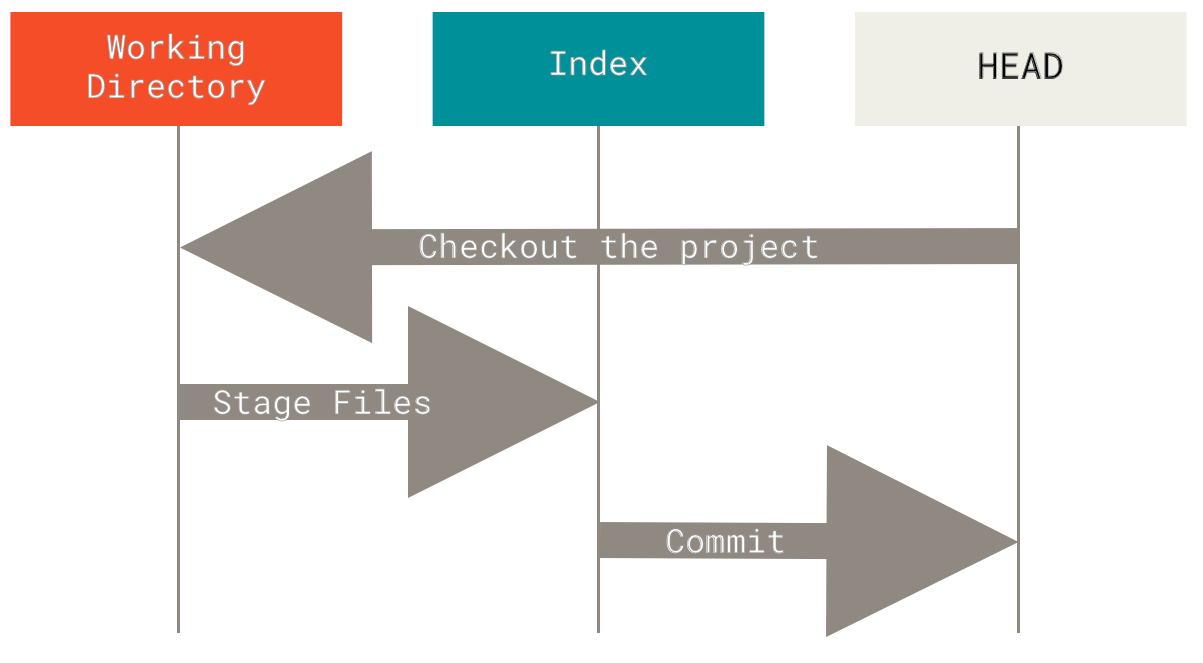
Let’s visualize this process: say you go into a new directory with a single file in it.
We’ll call this v1 of the file, and we’ll indicate it in blue.
Now we run git init, which will create a Git repository with a HEAD reference which points to the unborn master branch.
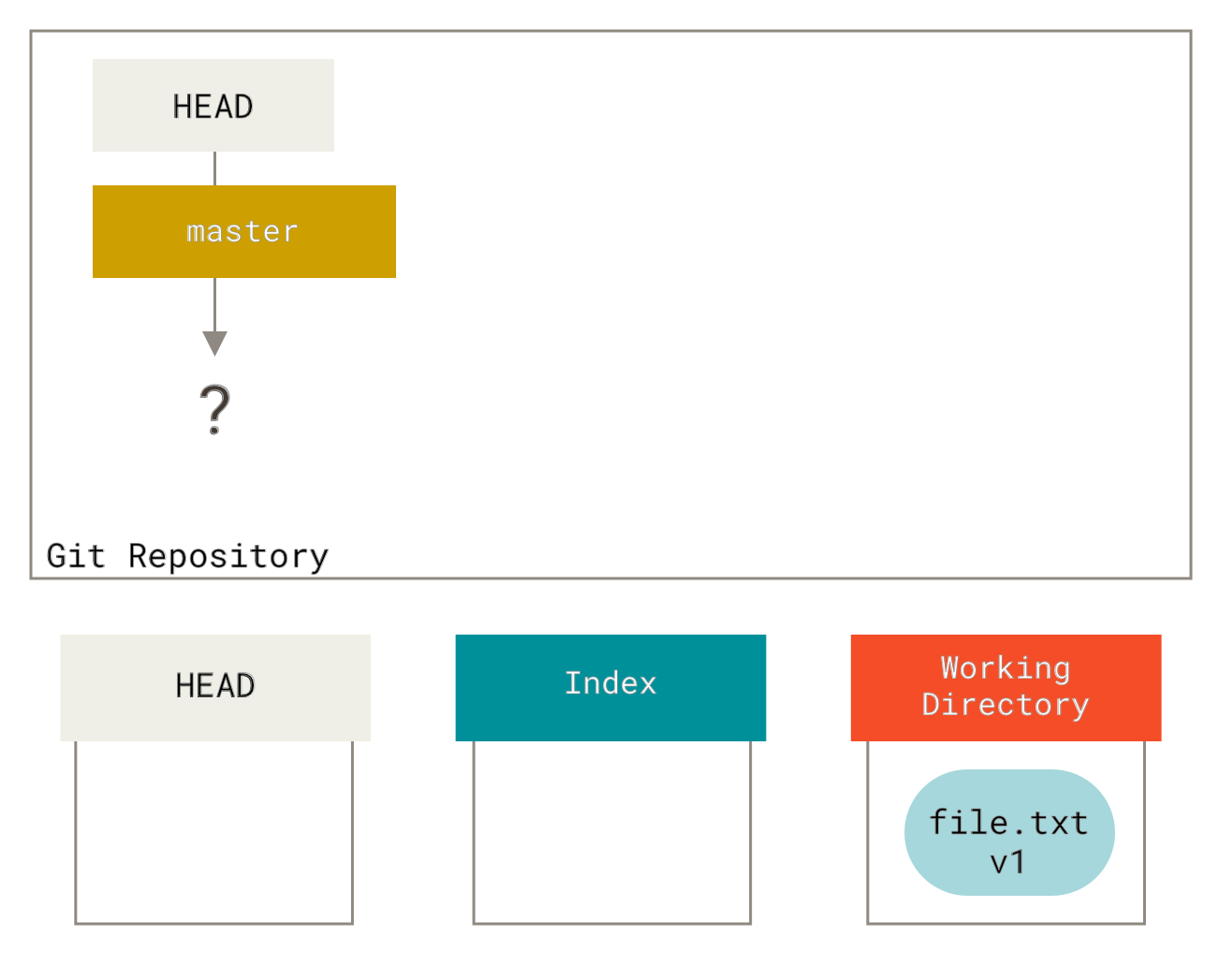
At this point, only the working directory tree has any content.
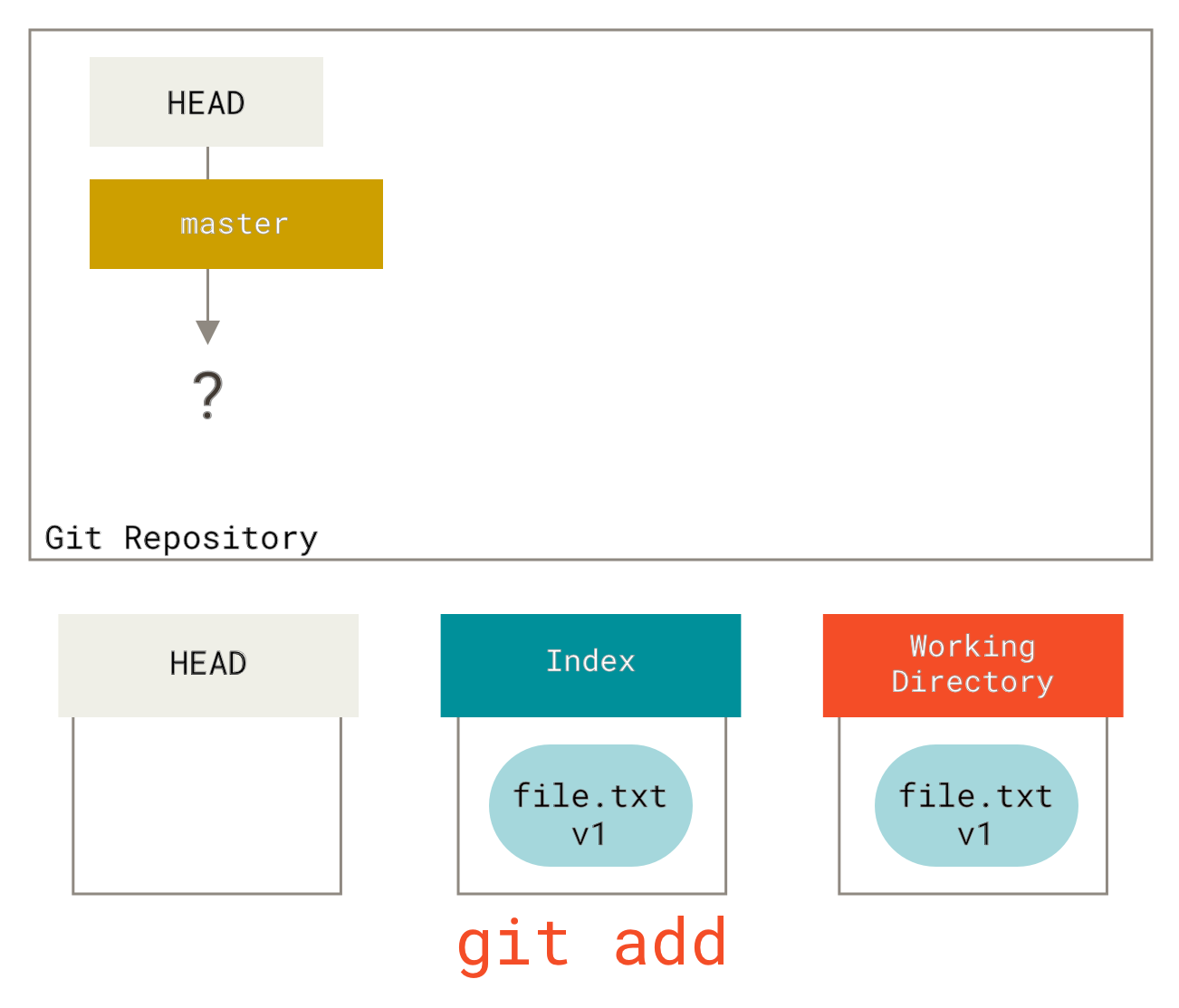
Now we want to commit this file, so we use git add to take content in the working directory and copy it to the index.
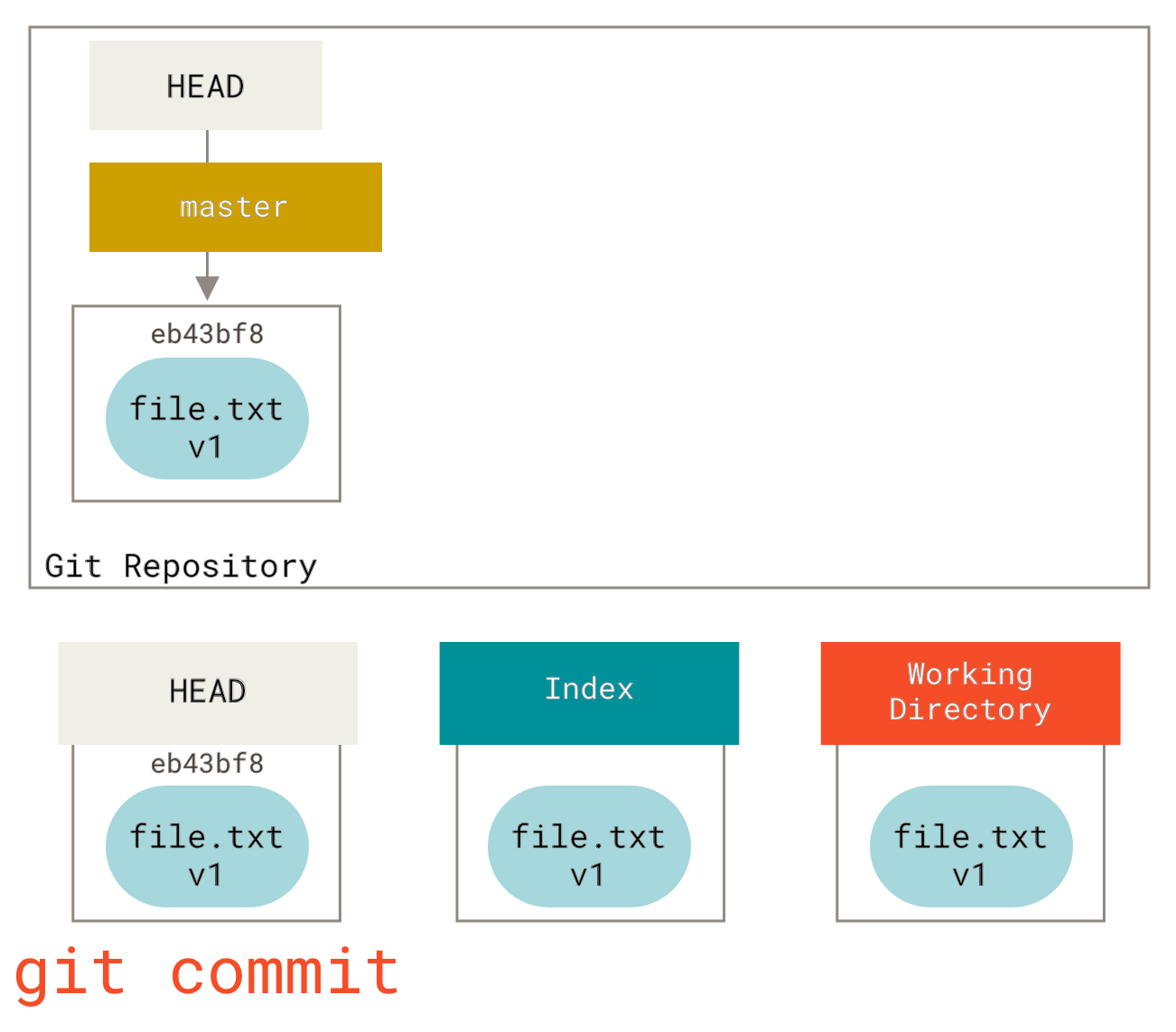
Then we run git commit, which takes the contents of the index and saves it as a permanent snapshot, creates a commit object which points to that snapshot, and updates master to point to that commit.
If we run git status, we’ll see no changes, because all three trees are the same.
Now we want to make a change to that file and commit it. We’ll go through the same process; first, we change the file in our working directory. Let’s call this v2 of the file, and indicate it in red.
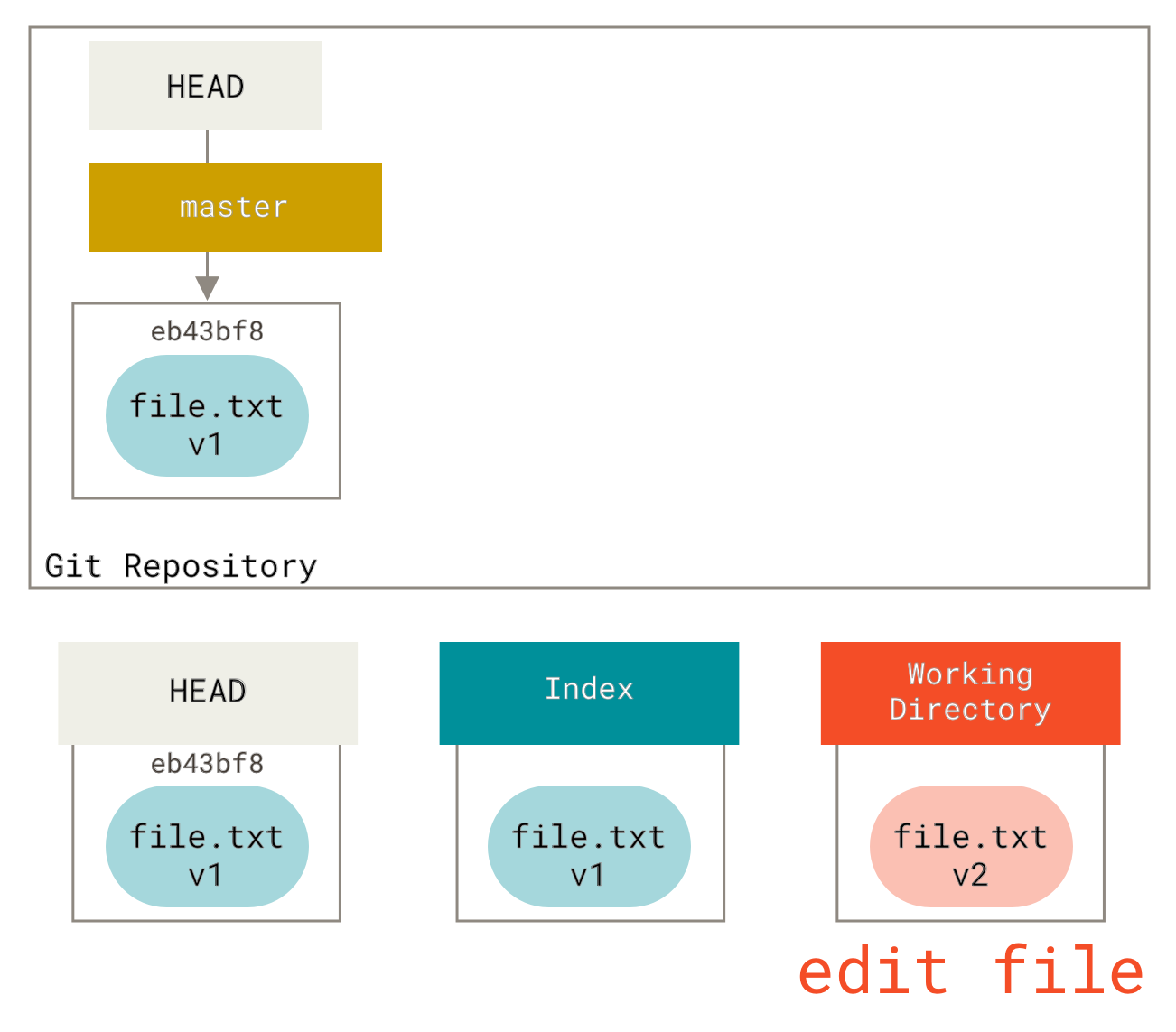
If we run git status right now, we’ll see the file in red as `Changes not staged for commit'', because that entry differs between the index and the working directory.
Next we run `git add on it to stage it into our index.
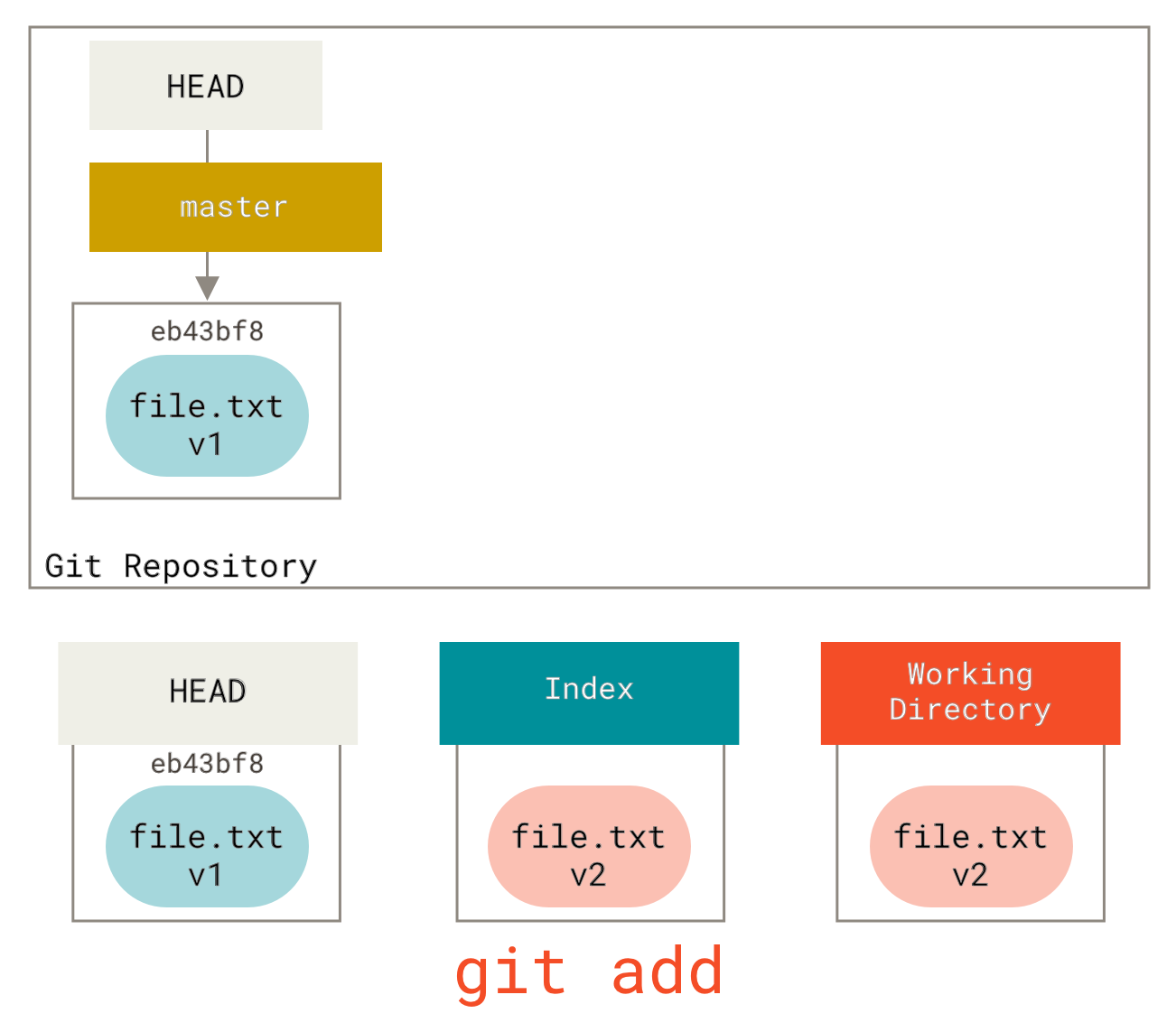
At this point, if we run git status, we will see the file in green under `Changes to be committed'' because the index and HEAD differ — that is, our proposed next commit is now different from our last commit.
Finally, we run `git commit to finalize the commit.
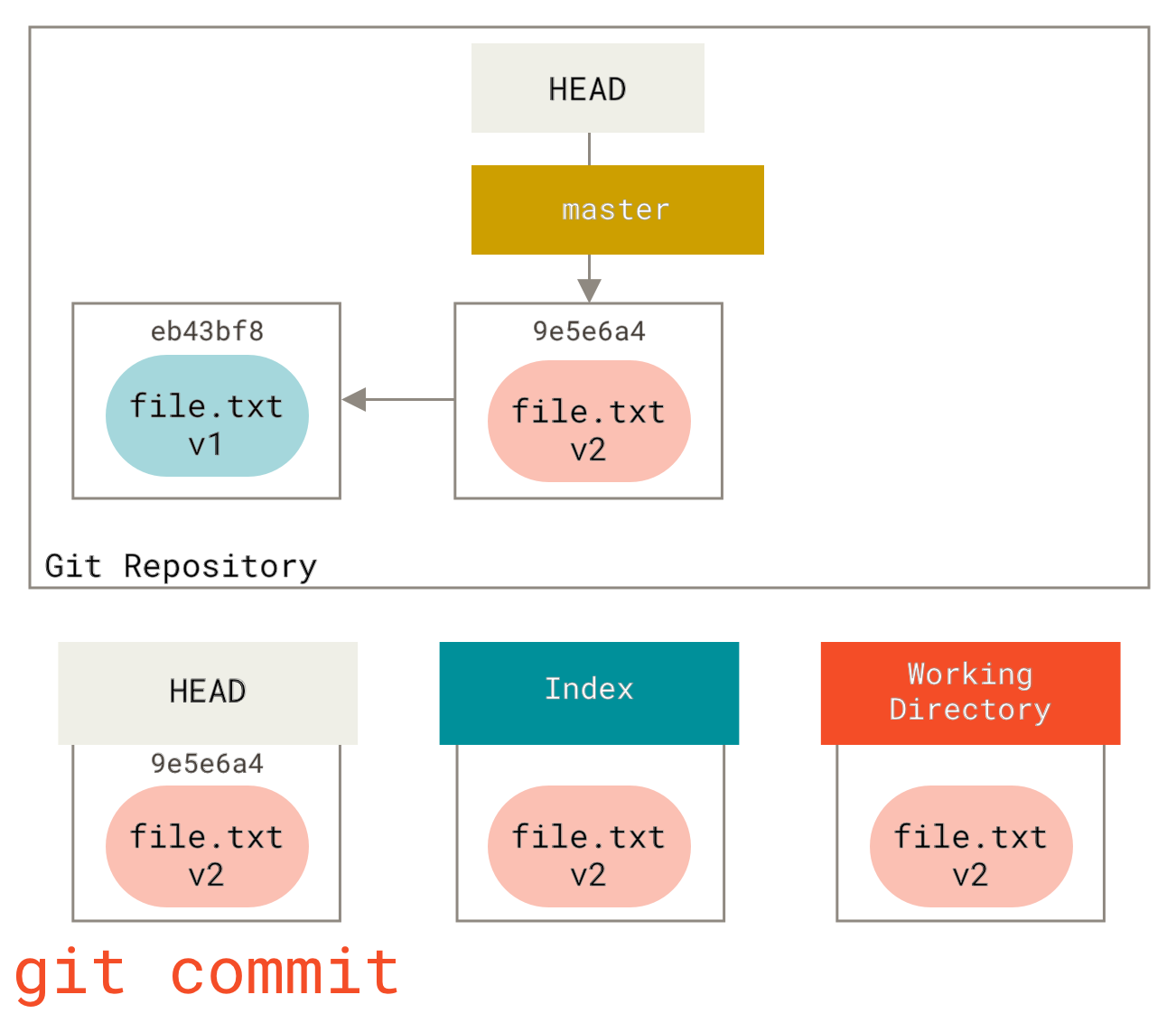
Now git status will give us no output, because all three trees are the same again.
Switching branches or cloning goes through a similar process. When you checkout a branch, it changes HEAD to point to the new branch ref, populates your index with the snapshot of that commit, then copies the contents of the index into your working Directory.
The Role of Reset
The reset command makes more sense when viewed in this context.
For the purposes of these examples, let’s say that we’ve modified file.txt again and committed it a third time.
So now our history looks like this:
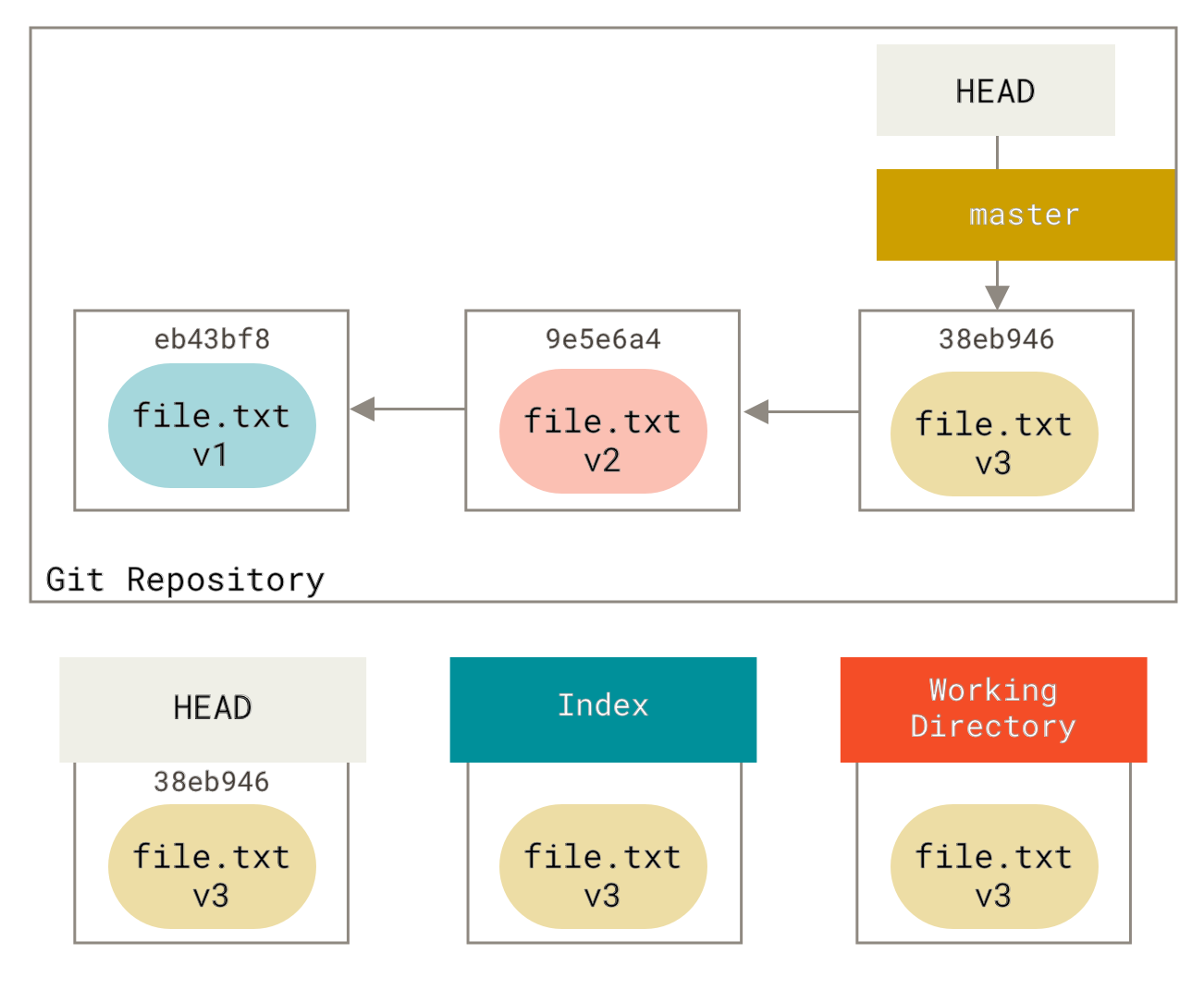
Let’s now walk through exactly what reset does when you call it.
It directly manipulates these three trees in a simple and predictable way.
It does up to three basic operations.
Step 1: Move HEAD
The first thing reset will do is move what HEAD points to.
This isn’t the same as changing HEAD itself (which is what checkout does); reset moves the branch that HEAD is pointing to.
This means if HEAD is set to the master branch (i.e. you’re currently on the master branch), running git reset 9e5e6a4 will start by making master point to 9e5e6a4.
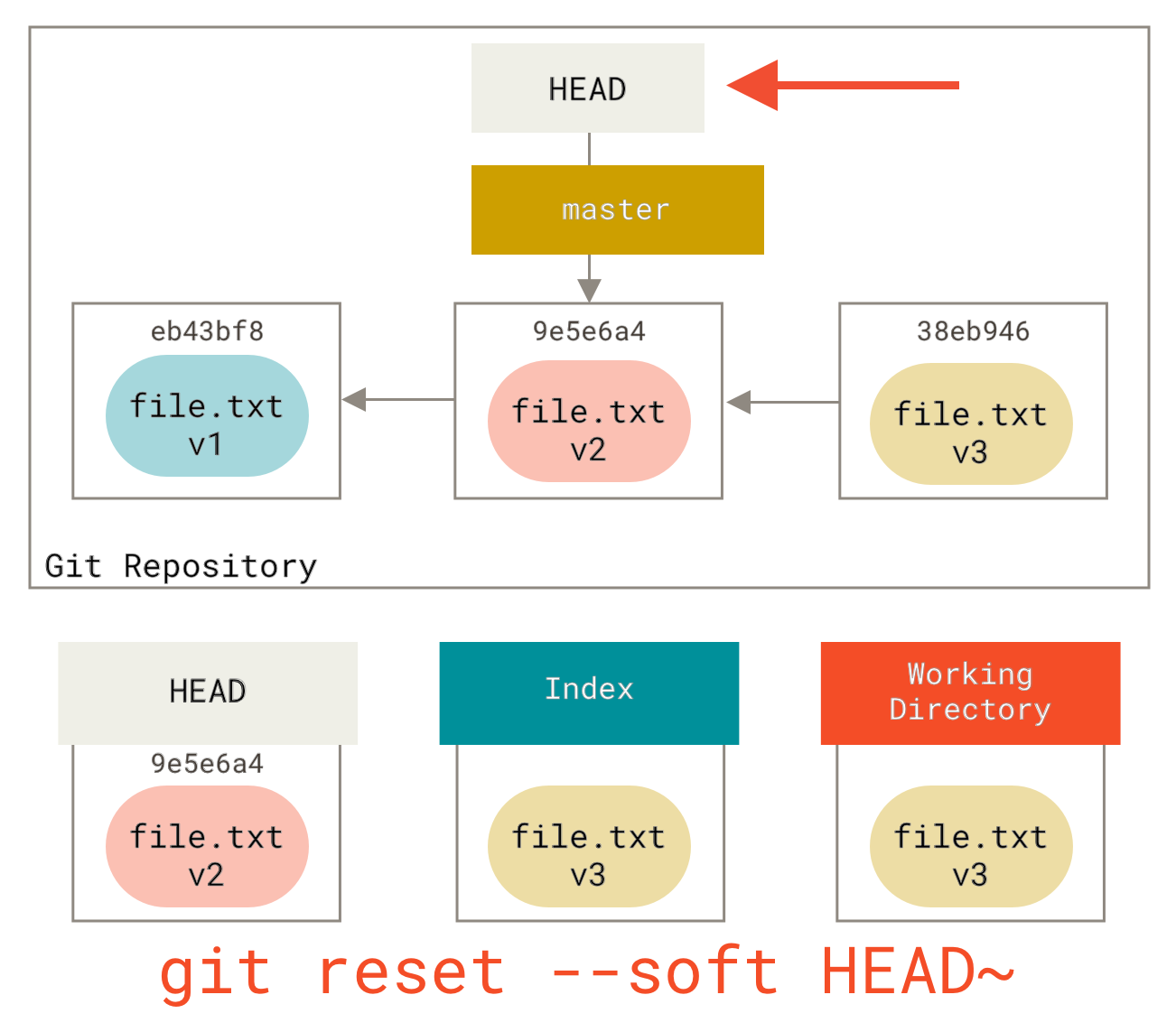
No matter what form of reset with a commit you invoke, this is the first thing it will always try to do.
With reset --soft, it will simply stop there.
Now take a second to look at that diagram and realize what happened: it essentially undid the last git commit command.
When you run git commit, Git creates a new commit and moves the branch that HEAD points to up to it.
When you reset back to HEAD~ (the parent of HEAD), you are moving the branch back to where it was, without changing the index or working directory.
You could now update the index and run git commit again to accomplish what git commit --amend would have done (see Changing the Last Commit).
Step 2: Updating the Index (--mixed)
Note that if you run git status now you’ll see in green the difference between the index and what the new HEAD is.
The next thing reset will do is to update the index with the contents of whatever snapshot HEAD now points to.
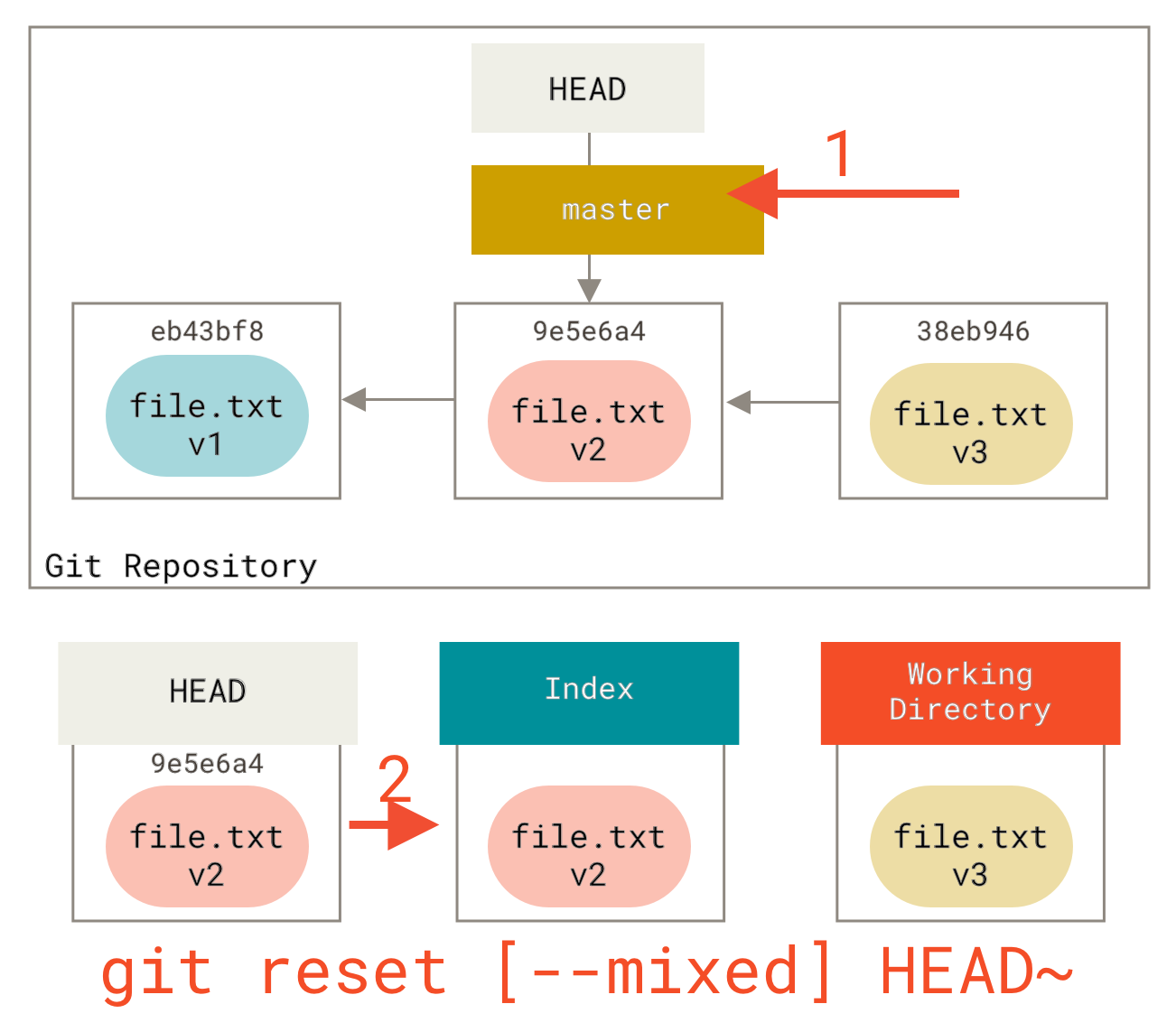
If you specify the --mixed option, reset will stop at this point.
This is also the default, so if you specify no option at all (just git reset HEAD~ in this case), this is where the command will stop.
Now take another second to look at that diagram and realize what happened: it still undid your last commit, but also unstaged everything.
You rolled back to before you ran all your git add and git commit commands.
Step 3: Updating the Working Directory (--hard)
The third thing that reset will do is to make the working directory look like the index.
If you use the --hard option, it will continue to this stage.
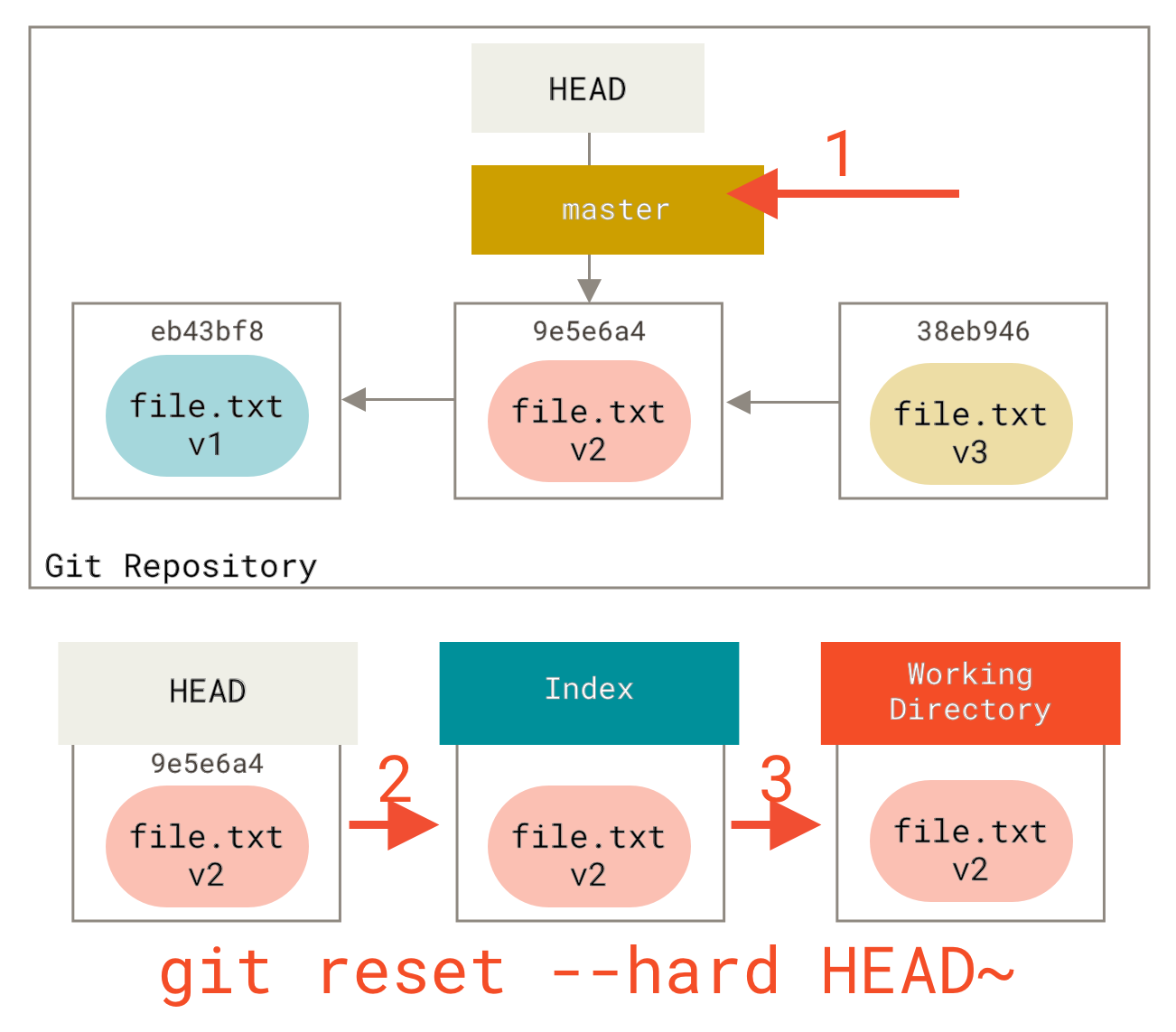
So let’s think about what just happened.
You undid your last commit, the git add and git commit commands, and all the work you did in your working directory.
It’s important to note that this flag (--hard) is the only way to make the reset command dangerous, and one of the very few cases where Git will actually destroy data.
Any other invocation of reset can be pretty easily undone, but the --hard option cannot, since it forcibly overwrites files in the working directory.
In this particular case, we still have the v3 version of our file in a commit in our Git DB, and we could get it back by looking at our reflog, but if we had not committed it, Git still would have overwritten the file and it would be unrecoverable.
Recap
The reset command overwrites these three trees in a specific order, stopping when you tell it to:
-
Move the branch HEAD points to (stop here if
--soft) -
Make the index look like HEAD (stop here unless
--hard) -
Make the working directory look like the index
Reset With a Path
That covers the behavior of reset in its basic form, but you can also provide it with a path to act upon.
If you specify a path, reset will skip step 1, and limit the remainder of its actions to a specific file or set of files.
This actually sort of makes sense — HEAD is just a pointer, and you can’t point to part of one commit and part of another.
But the index and working directory can be partially updated, so reset proceeds with steps 2 and 3.
So, assume we run git reset file.txt.
This form (since you did not specify a commit SHA-1 or branch, and you didn’t specify --soft or --hard) is shorthand for git reset --mixed HEAD file.txt, which will:
-
Move the branch HEAD points to (skipped)
-
Make the index look like HEAD (stop here)
So it essentially just copies file.txt from HEAD to the index.
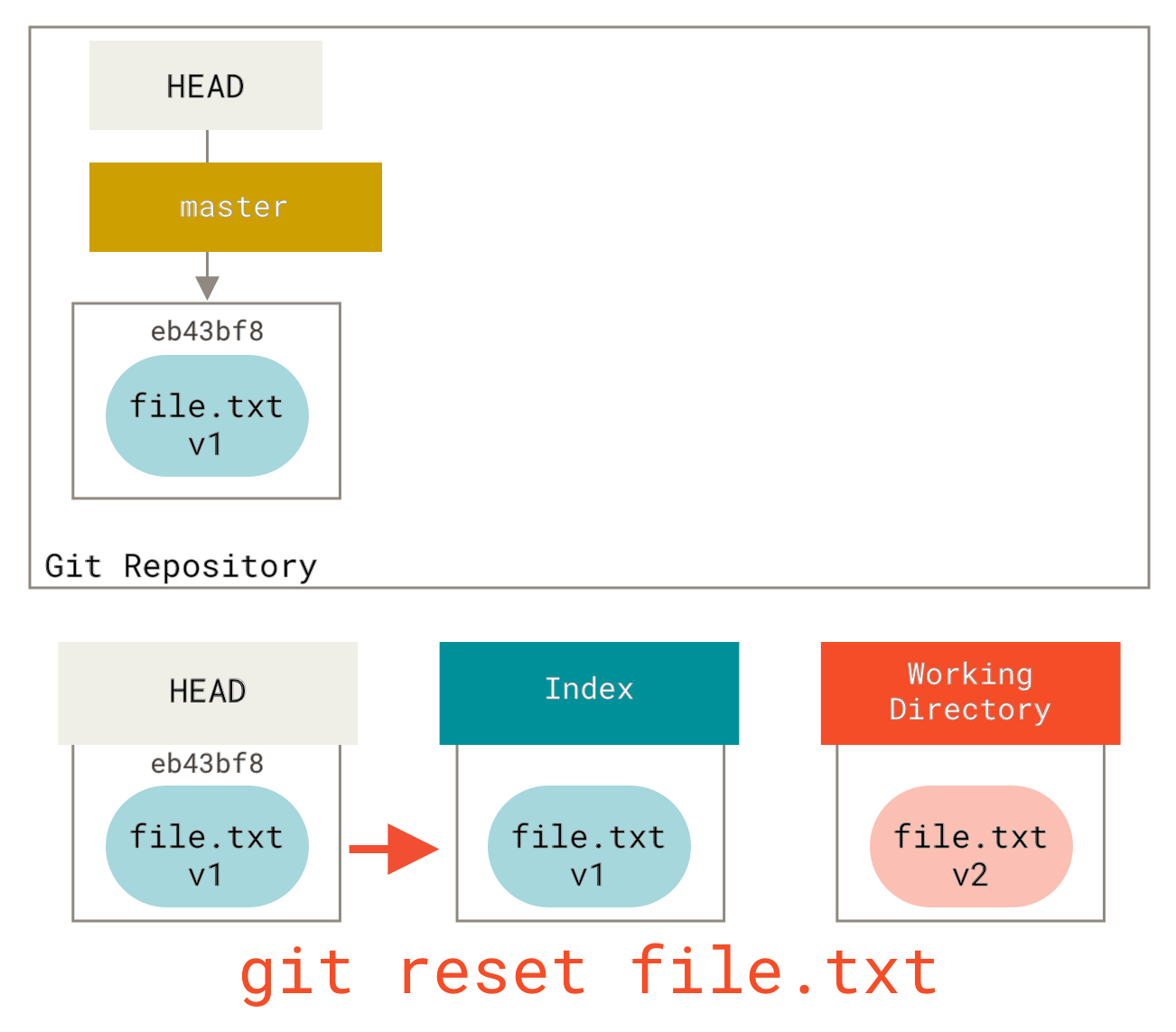
This has the practical effect of unstaging the file.
If we look at the diagram for that command and think about what git add does, they are exact opposites.
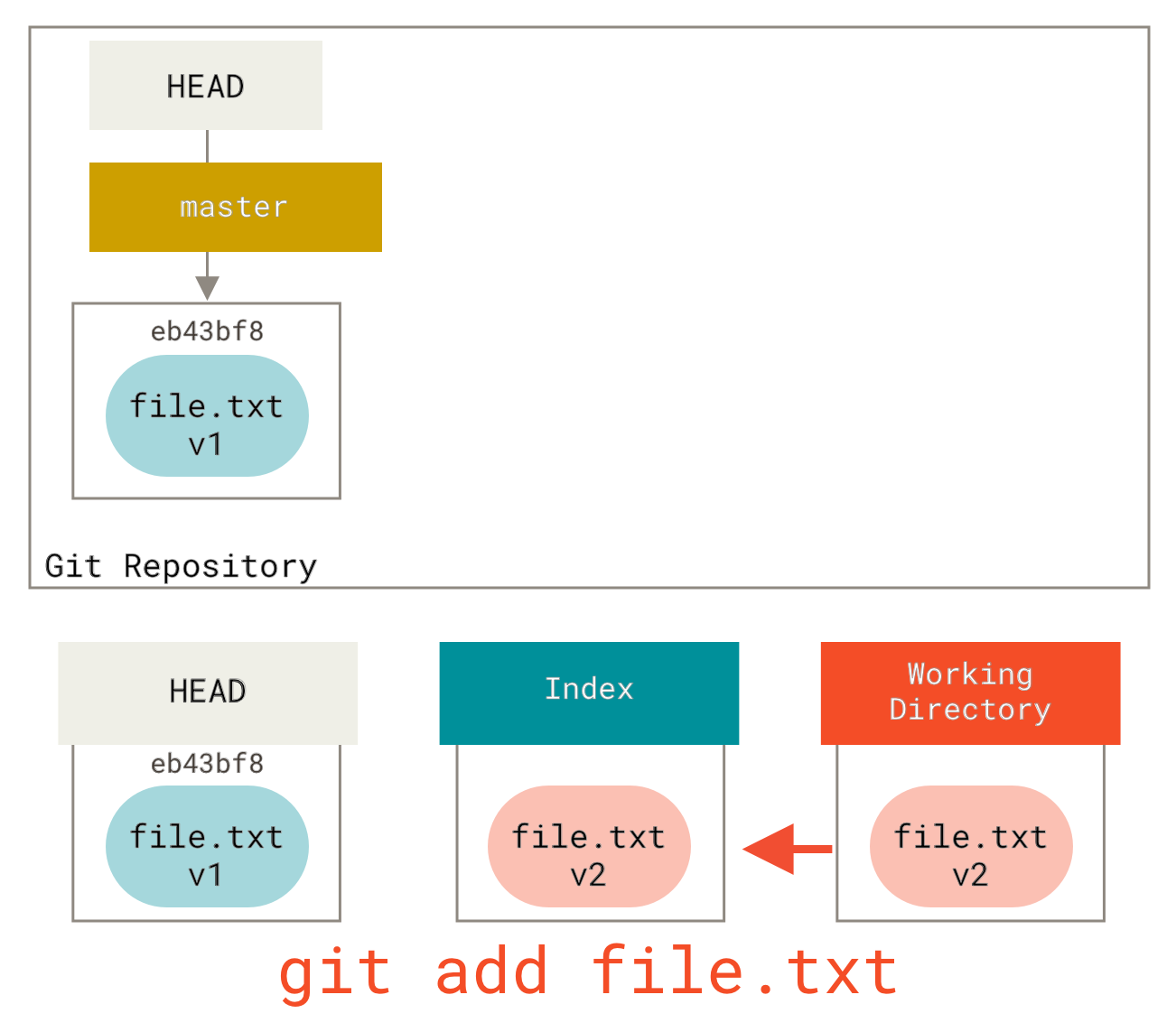
This is why the output of the git status command suggests that you run this to unstage a file.
(See Unstaging a Staged File for more on this.)
We could just as easily not let Git assume we meant `pull the data from HEAD'' by specifying a specific commit to pull that file version from.
We would just run something like `git reset eb43bf file.txt.
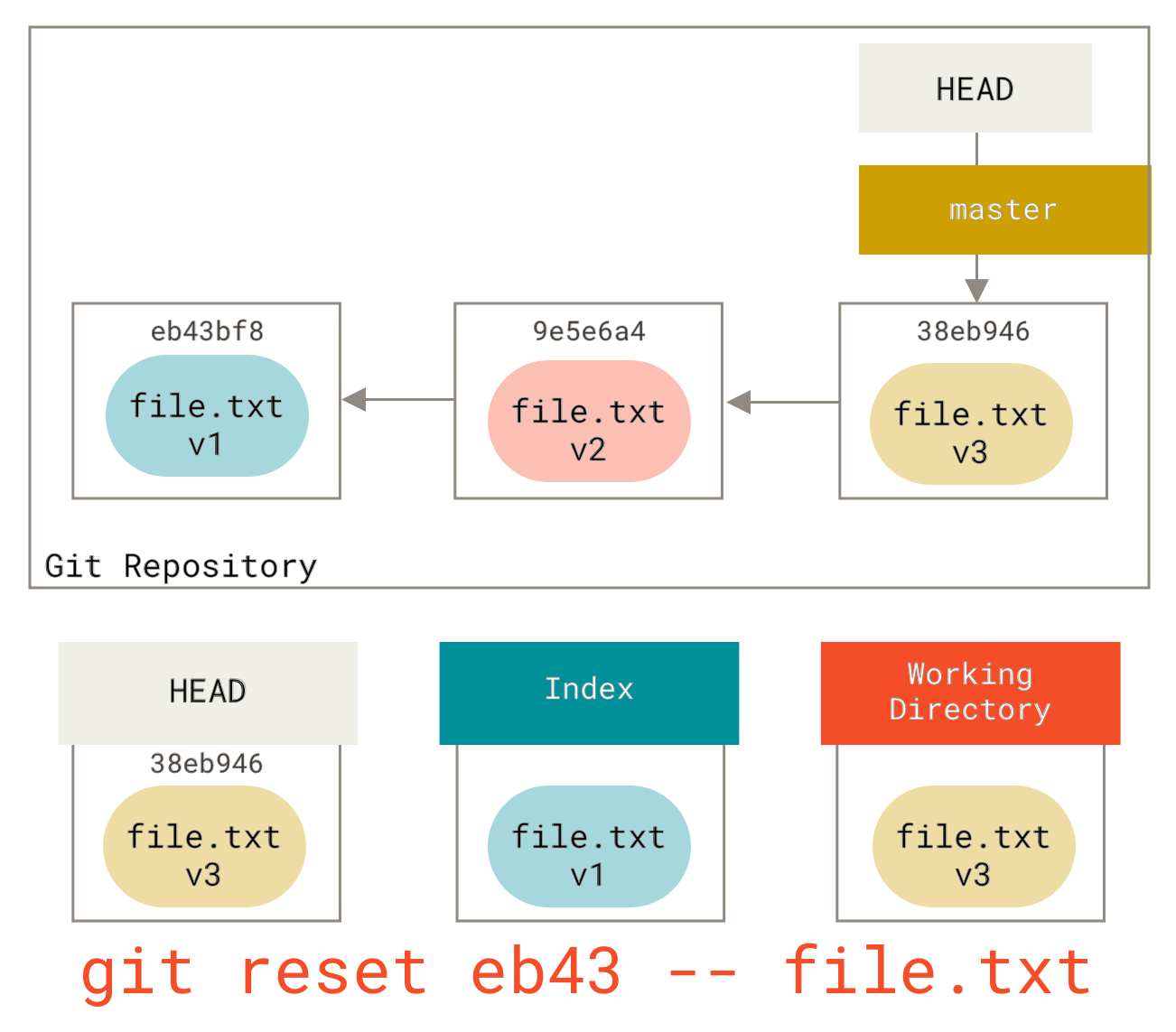
This effectively does the same thing as if we had reverted the content of the file to v1 in the working directory, ran git add on it, then reverted it back to v3 again (without actually going through all those steps).
If we run git commit now, it will record a change that reverts that file back to v1, even though we never actually had it in our working directory again.
It’s also interesting to note that like git add, the reset command will accept a --patch option to unstage content on a hunk-by-hunk basis.
So you can selectively unstage or revert content.
Squashing
Let’s look at how to do something interesting with this newfound power — squashing commits.
Say you have a series of commits with messages like oops.'', WIP'' and `forgot this file''.
You can use `reset to quickly and easily squash them into a single commit that makes you look really smart.
(Squashing Commits shows another way to do this, but in this example it’s simpler to use reset.)
Let’s say you have a project where the first commit has one file, the second commit added a new file and changed the first, and the third commit changed the first file again. The second commit was a work in progress and you want to squash it down.
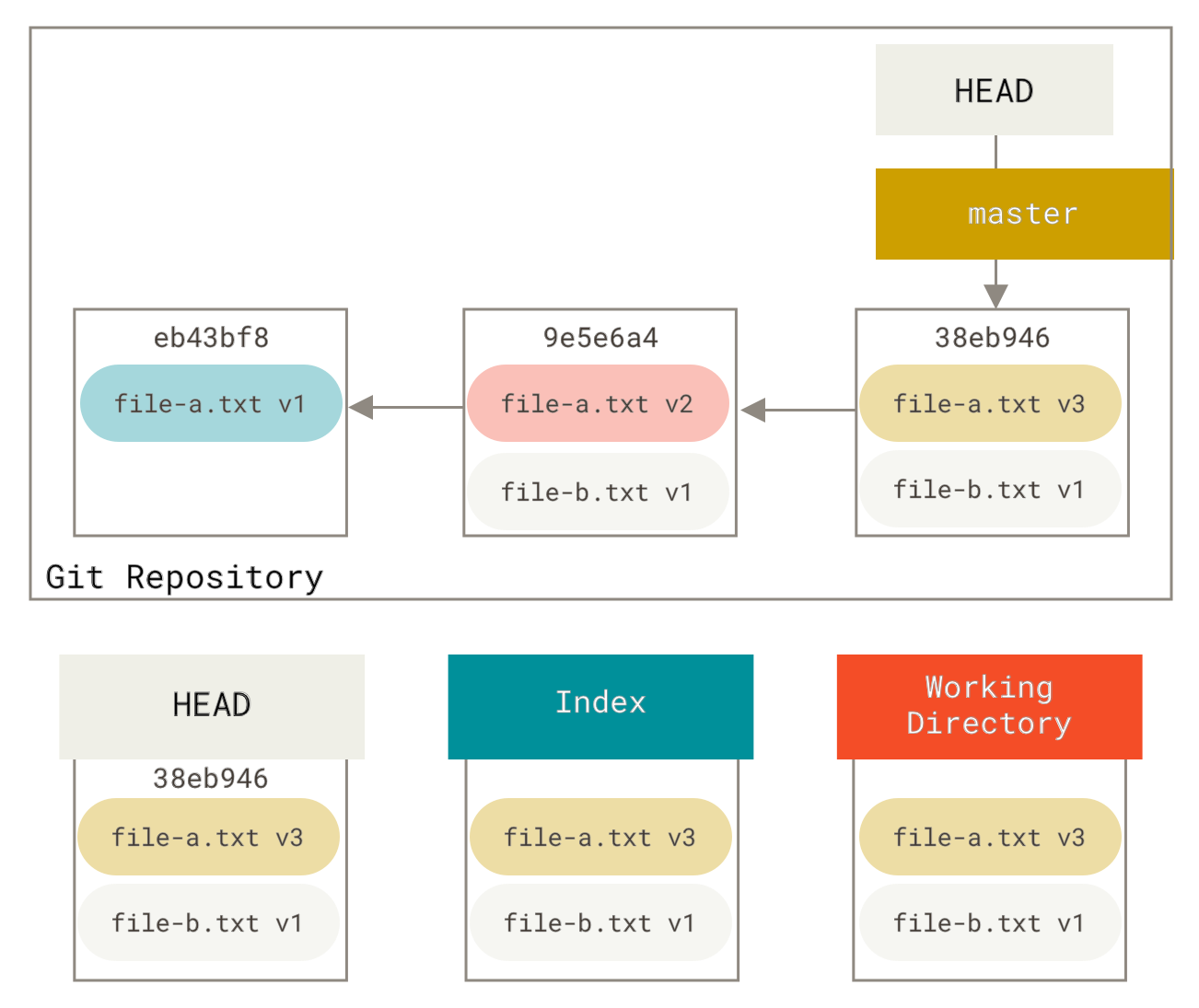
You can run git reset --soft HEAD~2 to move the HEAD branch back to an older commit (the most recent commit you want to keep):
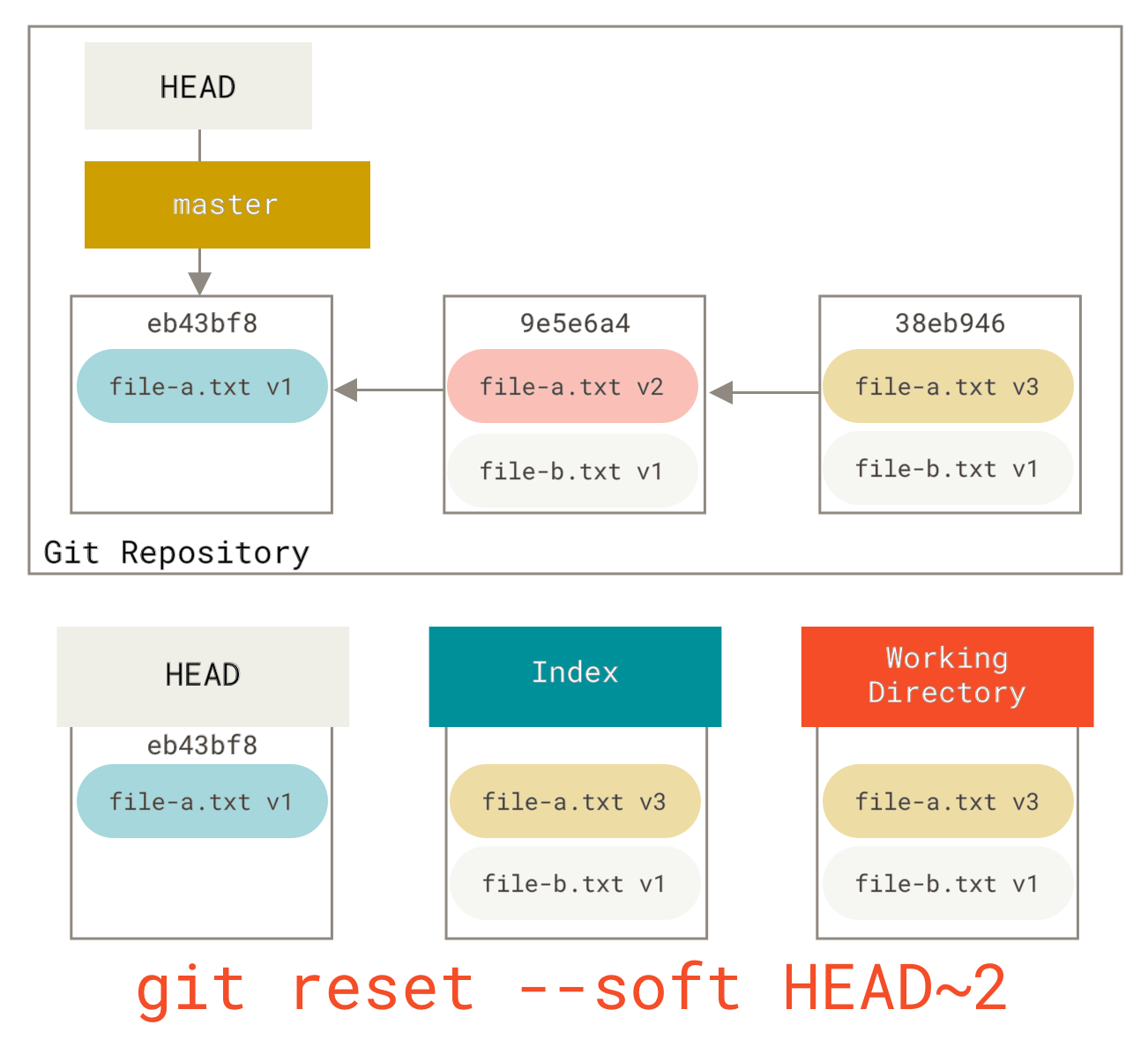
And then simply run git commit again:
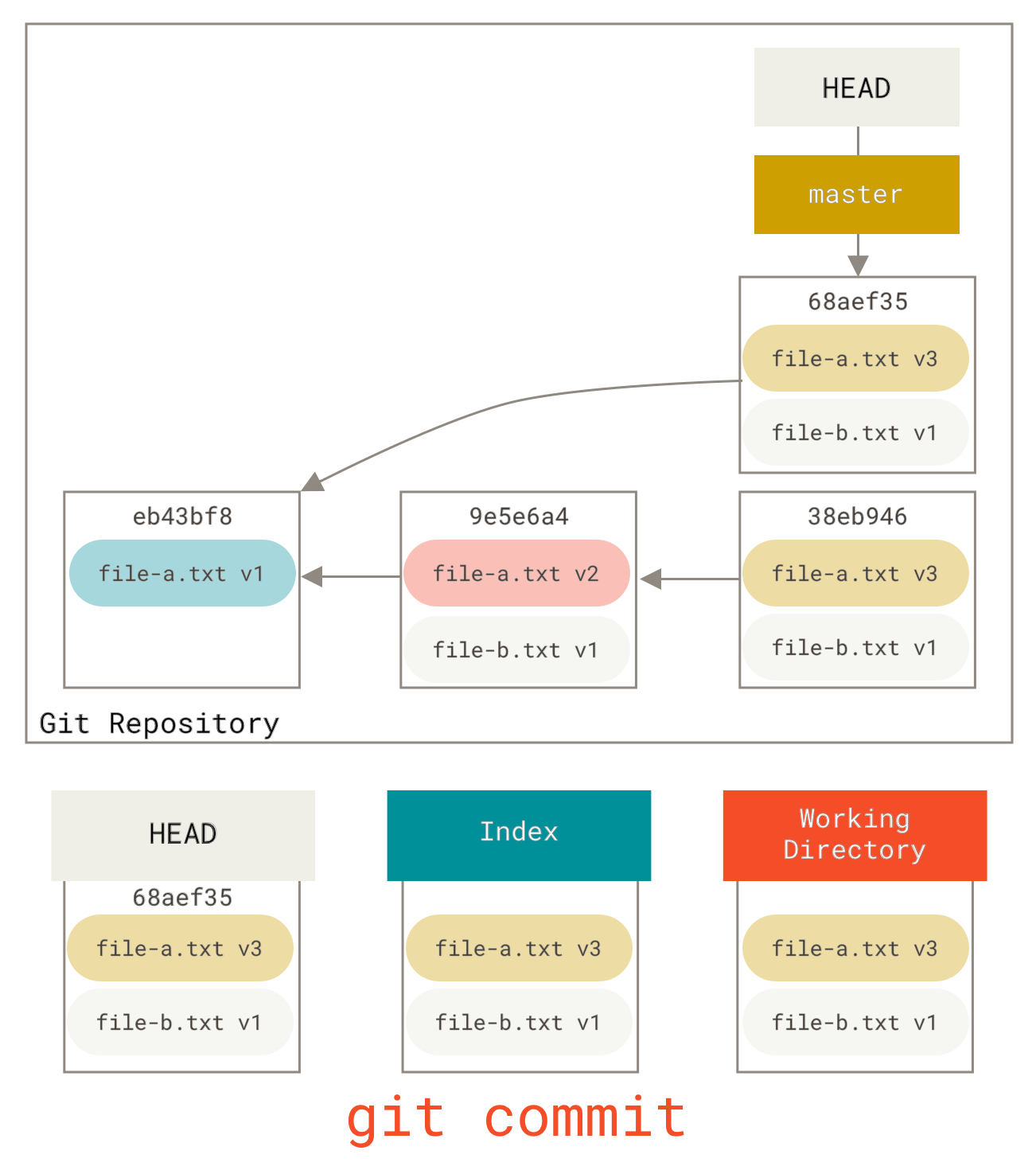
Now you can see that your reachable history, the history you would push, now looks like you had one commit with file-a.txt v1, then a second that both modified file-a.txt to v3 and added file-b.txt.
The commit with the v2 version of the file is no longer in the history.
Check It Out
Finally, you may wonder what the difference between checkout and reset is.
Like reset, checkout manipulates the three trees, and it is a bit different depending on whether you give the command a file path or not.
Without Paths
Running git checkout [branch] is pretty similar to running git reset --hard [branch] in that it updates all three trees for you to look like [branch], but there are two important differences.
First, unlike reset --hard, checkout is working-directory safe; it will check to make sure it’s not blowing away files that have changes to them.
Actually, it’s a bit smarter than that — it tries to do a trivial merge in the working directory, so all of the files you haven’t changed will be updated.
reset --hard, on the other hand, will simply replace everything across the board without checking.
The second important difference is how checkout updates HEAD.
Whereas reset will move the branch that HEAD points to, checkout will move HEAD itself to point to another branch.
For instance, say we have master and develop branches which point at different commits, and we’re currently on develop (so HEAD points to it).
If we run git reset master, develop itself will now point to the same commit that master does.
If we instead run git checkout master, develop does not move, HEAD itself does.
HEAD will now point to master.
So, in both cases we’re moving HEAD to point to commit A, but how we do so is very different.
reset will move the branch HEAD points to, checkout moves HEAD itself.
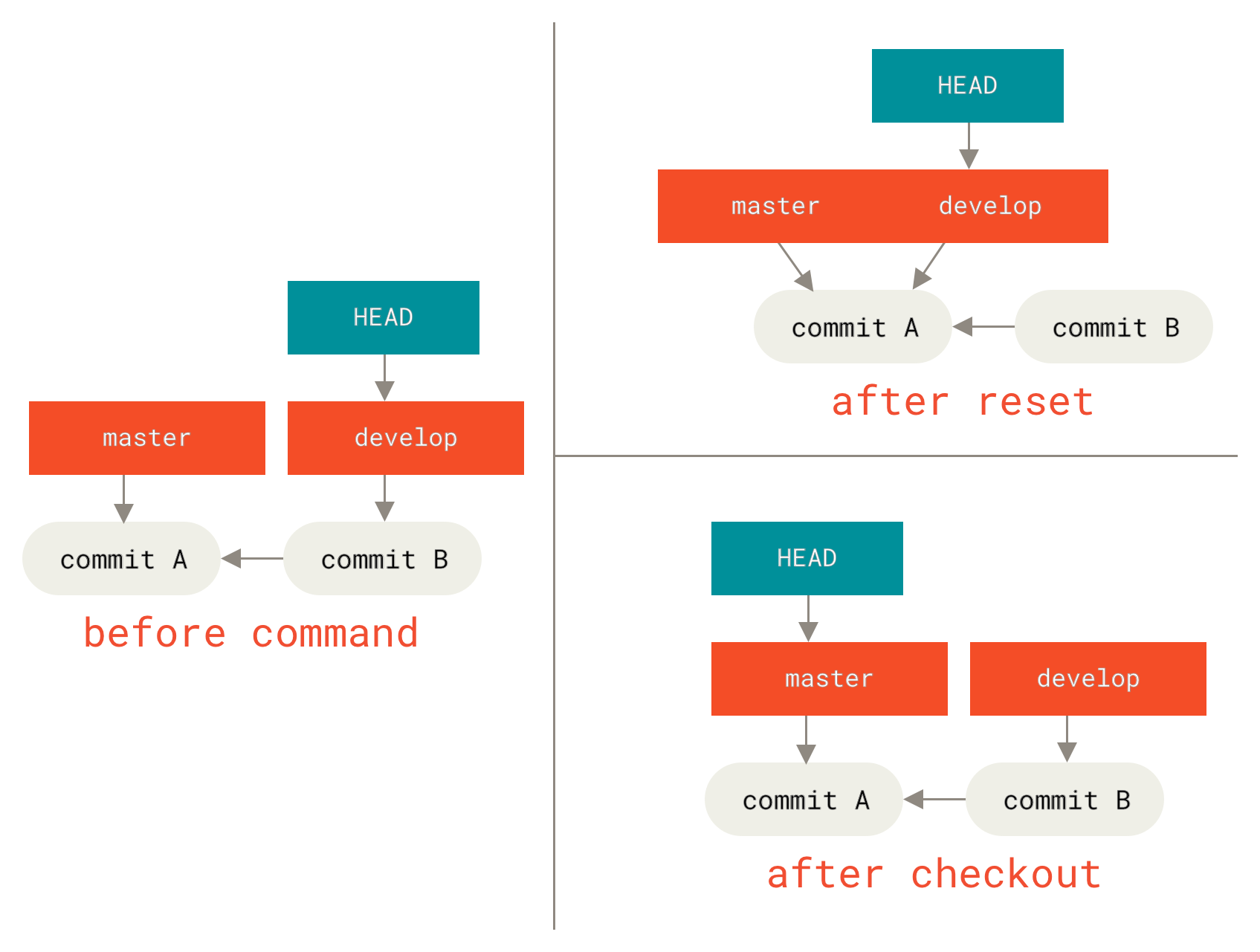
With Paths
The other way to run checkout is with a file path, which, like reset, does not move HEAD.
It is just like git reset [branch] file in that it updates the index with that file at that commit, but it also overwrites the file in the working directory.
It would be exactly like git reset --hard [branch] file (if reset would let you run that) — it’s not working-directory safe, and it does not move HEAD.
Also, like git reset and git add, checkout will accept a --patch option to allow you to selectively revert file contents on a hunk-by-hunk basis.
Summary
Hopefully now you understand and feel more comfortable with the reset command, but are probably still a little confused about how exactly it differs from checkout and could not possibly remember all the rules of the different invocations.
Here’s a cheat-sheet for which commands affect which trees.
The HEAD'' column reads REF'' if that command moves the reference (branch) that HEAD points to, and ``HEAD'' if it moves HEAD itself.
Pay especial attention to the 'WD Safe?' column — if it says NO, take a second to think before running that command.
| HEAD | Index | Workdir | WD Safe? | |
|---|---|---|---|---|
| Commit Level | ||||
reset --soft [commit] |
REF | NO | NO | YES |
reset [commit] |
REF | YES | NO | YES |
reset --hard [commit] |
REF | YES | YES | NO |
checkout <commit> |
HEAD | YES | YES | YES |
| File Level | ||||
reset [commit] <paths> |
NO | YES | NO | YES |
checkout [commit] <paths> |
NO | YES | YES | NO |
Advanced Merging
Merging in Git is typically fairly easy. Since Git makes it easy to merge another branch multiple times, it means that you can have a very long lived branch but you can keep it up to date as you go, solving small conflicts often, rather than be surprised by one enormous conflict at the end of the series.
However, sometimes tricky conflicts do occur. Unlike some other version control systems, Git does not try to be overly clever about merge conflict resolution. Git’s philosophy is to be smart about determining when a merge resolution is unambiguous, but if there is a conflict, it does not try to be clever about automatically resolving it. Therefore, if you wait too long to merge two branches that diverge quickly, you can run into some issues.
In this section, we’ll go over what some of those issues might be and what tools Git gives you to help handle these more tricky situations. We’ll also cover some of the different, non-standard types of merges you can do, as well as see how to back out of merges that you’ve done.
Merge Conflicts
While we covered some basics on resolving merge conflicts in Basic Merge Conflicts, for more complex conflicts, Git provides a few tools to help you figure out what’s going on and how to better deal with the conflict.
First of all, if at all possible, try to make sure your working directory is clean before doing a merge that may have conflicts. If you have work in progress, either commit it to a temporary branch or stash it. This makes it so that you can undo anything you try here. If you have unsaved changes in your working directory when you try a merge, some of these tips may help you preserve that work.
Let’s walk through a very simple example. We have a super simple Ruby file that prints 'hello world'.
#! /usr/bin/env ruby def hello puts 'hello world' end hello()
In our repository, we create a new branch named whitespace and proceed to change all the Unix line endings to DOS line endings, essentially changing every line of the file, but just with whitespace.
Then we change the line hello world'' to hello mundo''.
$ git checkout -b whitespace Switched to a new branch 'whitespace' $ unix2dos hello.rb unix2dos: converting file hello.rb to DOS format ... $ git commit -am 'converted hello.rb to DOS' [whitespace 3270f76] converted hello.rb to DOS 1 file changed, 7 insertions(+), 7 deletions(-) $ vim hello.rb $ git diff -b diff --git a/hello.rb b/hello.rb index ac51efd..e85207e 100755 --- a/hello.rb +++ b/hello.rb @@ -1,7 +1,7 @@ #! /usr/bin/env ruby def hello - puts 'hello world' + puts 'hello mundo'^M end hello() $ git commit -am 'hello mundo change' [whitespace 6d338d2] hello mundo change 1 file changed, 1 insertion(+), 1 deletion(-)
Now we switch back to our master branch and add some documentation for the function.
$ git checkout master Switched to branch 'master' $ vim hello.rb $ git diff diff --git a/hello.rb b/hello.rb index ac51efd..36c06c8 100755 --- a/hello.rb +++ b/hello.rb @@ -1,5 +1,6 @@ #! /usr/bin/env ruby +# prints out a greeting def hello puts 'hello world' end $ git commit -am 'document the function' [master bec6336] document the function 1 file changed, 1 insertion(+)
Now we try to merge in our whitespace branch and we’ll get conflicts because of the whitespace changes.
$ git merge whitespace Auto-merging hello.rb CONFLICT (content): Merge conflict in hello.rb Automatic merge failed; fix conflicts and then commit the result.
Aborting a Merge
We now have a few options.
First, let’s cover how to get out of this situation.
If you perhaps weren’t expecting conflicts and don’t want to quite deal with the situation yet, you can simply back out of the merge with git merge --abort.
$ git status -sb ## master UU hello.rb $ git merge --abort $ git status -sb ## master
The git merge --abort option tries to revert back to your state before you ran the merge.
The only cases where it may not be able to do this perfectly would be if you had unstashed, uncommitted changes in your working directory when you ran it, otherwise it should work fine.
If for some reason you just want to start over, you can also run git reset --hard HEAD, and your repository will be back to the last committed state.
Remember that any uncommitted work will be lost, so make sure you don’t want any of your changes.
Ignoring Whitespace
In this specific case, the conflicts are whitespace related. We know this because the case is simple, but it’s also pretty easy to tell in real cases when looking at the conflict because every line is removed on one side and added again on the other. By default, Git sees all of these lines as being changed, so it can’t merge the files.
The default merge strategy can take arguments though, and a few of them are about properly ignoring whitespace changes.
If you see that you have a lot of whitespace issues in a merge, you can simply abort it and do it again, this time with -Xignore-all-space or -Xignore-space-change.
The first option ignores whitespace completely when comparing lines, the second treats sequences of one or more whitespace characters as equivalent.
$ git merge -Xignore-space-change whitespace Auto-merging hello.rb Merge made by the 'recursive' strategy. hello.rb | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-)
Since in this case, the actual file changes were not conflicting, once we ignore the whitespace changes, everything merges just fine.
This is a lifesaver if you have someone on your team who likes to occasionally reformat everything from spaces to tabs or vice-versa.
Manual File Re-merging
Though Git handles whitespace pre-processing pretty well, there are other types of changes that perhaps Git can’t handle automatically, but are scriptable fixes. As an example, let’s pretend that Git could not handle the whitespace change and we needed to do it by hand.
What we really need to do is run the file we’re trying to merge in through a dos2unix program before trying the actual file merge.
So how would we do that?
First, we get into the merge conflict state. Then we want to get copies of my version of the file, their version (from the branch we’re merging in) and the common version (from where both sides branched off). Then we want to fix up either their side or our side and re-try the merge again for just this single file.
Getting the three file versions is actually pretty easy.
Git stores all of these versions in the index under stages'' which each have numbers associated with them.
Stage 1 is the common ancestor, stage 2 is your version and stage 3 is from the theirs'').MERGE_HEAD, the version you’re merging in (
You can extract a copy of each of these versions of the conflicted file with the git show command and a special syntax.
$ git show :1:hello.rb > hello.common.rb $ git show :2:hello.rb > hello.ours.rb $ git show :3:hello.rb > hello.theirs.rb
If you want to get a little more hard core, you can also use the ls-files -u plumbing command to get the actual SHA-1s of the Git blobs for each of these files.
$ git ls-files -u 100755 ac51efdc3df4f4fd328d1a02ad05331d8e2c9111 1 hello.rb 100755 36c06c8752c78d2aff89571132f3bf7841a7b5c3 2 hello.rb 100755 e85207e04dfdd5eb0a1e9febbc67fd837c44a1cd 3 hello.rb
The :1:hello.rb is just a shorthand for looking up that blob SHA-1.
Now that we have the content of all three stages in our working directory, we can manually fix up theirs to fix the whitespace issue and re-merge the file with the little-known git merge-file command which does just that.
$ dos2unix hello.theirs.rb
dos2unix: converting file hello.theirs.rb to Unix format ...
$ git merge-file -p \
hello.ours.rb hello.common.rb hello.theirs.rb > hello.rb
$ git diff -b
diff --cc hello.rb
index 36c06c8,e85207e..0000000
--- a/hello.rb
+++ b/hello.rb
@@@ -1,8 -1,7 +1,8 @@@
#! /usr/bin/env ruby
+# prints out a greeting
def hello
- puts 'hello world'
+ puts 'hello mundo'
end
hello()
At this point we have nicely merged the file.
In fact, this actually works better than the ignore-space-change option because this actually fixes the whitespace changes before merge instead of simply ignoring them.
In the ignore-space-change merge, we actually ended up with a few lines with DOS line endings, making things mixed.
If you want to get an idea before finalizing this commit about what was actually changed between one side or the other, you can ask git diff to compare what is in your working directory that you’re about to commit as the result of the merge to any of these stages.
Let’s go through them all.
To compare your result to what you had in your branch before the merge, in other words, to see what the merge introduced, you can run git diff --ours
$ git diff --ours * Unmerged path hello.rb diff --git a/hello.rb b/hello.rb index 36c06c8..44d0a25 100755 --- a/hello.rb +++ b/hello.rb @@ -2,7 +2,7 @@ # prints out a greeting def hello - puts 'hello world' + puts 'hello mundo' end hello()
So here we can easily see that what happened in our branch, what we’re actually introducing to this file with this merge, is changing that single line.
If we want to see how the result of the merge differed from what was on their side, you can run git diff --theirs.
In this and the following example, we have to use -b to strip out the whitespace because we’re comparing it to what is in Git, not our cleaned up hello.theirs.rb file.
$ git diff --theirs -b * Unmerged path hello.rb diff --git a/hello.rb b/hello.rb index e85207e..44d0a25 100755 --- a/hello.rb +++ b/hello.rb @@ -1,5 +1,6 @@ #! /usr/bin/env ruby +# prints out a greeting def hello puts 'hello mundo' end
Finally, you can see how the file has changed from both sides with git diff --base.
$ git diff --base -b * Unmerged path hello.rb diff --git a/hello.rb b/hello.rb index ac51efd..44d0a25 100755 --- a/hello.rb +++ b/hello.rb @@ -1,7 +1,8 @@ #! /usr/bin/env ruby +# prints out a greeting def hello - puts 'hello world' + puts 'hello mundo' end hello()
At this point we can use the git clean command to clear out the extra files we created to do the manual merge but no longer need.
$ git clean -f Removing hello.common.rb Removing hello.ours.rb Removing hello.theirs.rb
Checking Out Conflicts
Perhaps we’re not happy with the resolution at this point for some reason, or maybe manually editing one or both sides still didn’t work well and we need more context.
Let’s change up the example a little. For this example, we have two longer lived branches that each have a few commits in them but create a legitimate content conflict when merged.
$ git log --graph --oneline --decorate --all * f1270f7 (HEAD, master) update README * 9af9d3b add a README * 694971d update phrase to hola world | * e3eb223 (mundo) add more tests | * 7cff591 add testing script | * c3ffff1 changed text to hello mundo |/ * b7dcc89 initial hello world code
We now have three unique commits that live only on the master branch and three others that live on the mundo branch.
If we try to merge the mundo branch in, we get a conflict.
$ git merge mundo Auto-merging hello.rb CONFLICT (content): Merge conflict in hello.rb Automatic merge failed; fix conflicts and then commit the result.
We would like to see what the merge conflict is. If we open up the file, we’ll see something like this:
#! /usr/bin/env ruby def hello <<<<<<< HEAD puts 'hola world' ======= puts 'hello mundo' >>>>>>> mundo end hello()
Both sides of the merge added content to this file, but some of the commits modified the file in the same place that caused this conflict.
Let’s explore a couple of tools that you now have at your disposal to determine how this conflict came to be. Perhaps it’s not obvious how exactly you should fix this conflict. You need more context.
One helpful tool is git checkout with the --conflict option.
This will re-checkout the file again and replace the merge conflict markers.
This can be useful if you want to reset the markers and try to resolve them again.
You can pass --conflict either diff3 or merge (which is the default).
If you pass it diff3, Git will use a slightly different version of conflict markers, not only giving you the ours'' and theirs'' versions, but also the ``base'' version inline to give you more context.
$ git checkout --conflict=diff3 hello.rb
Once we run that, the file will look like this instead:
#! /usr/bin/env ruby def hello <<<<<<< ours puts 'hola world' ||||||| base puts 'hello world' ======= puts 'hello mundo' >>>>>>> theirs end hello()
If you like this format, you can set it as the default for future merge conflicts by setting the merge.conflictstyle setting to diff3.
$ git config --global merge.conflictstyle diff3
The git checkout command can also take --ours and --theirs options, which can be a really fast way of just choosing either one side or the other without merging things at all.
This can be particularly useful for conflicts of binary files where you can simply choose one side, or where you only want to merge certain files in from another branch — you can do the merge and then checkout certain files from one side or the other before committing.
Merge Log
Another useful tool when resolving merge conflicts is git log.
This can help you get context on what may have contributed to the conflicts.
Reviewing a little bit of history to remember why two lines of development were touching the same area of code can be really helpful sometimes.
To get a full list of all of the unique commits that were included in either branch involved in this merge, we can use the ``triple dot'' syntax that we learned in Triple Dot.
$ git log --oneline --left-right HEAD...MERGE_HEAD < f1270f7 update README < 9af9d3b add a README < 694971d update phrase to hola world > e3eb223 add more tests > 7cff591 add testing script > c3ffff1 changed text to hello mundo
That’s a nice list of the six total commits involved, as well as which line of development each commit was on.
We can further simplify this though to give us much more specific context.
If we add the --merge option to git log, it will only show the commits in either side of the merge that touch a file that’s currently conflicted.
$ git log --oneline --left-right --merge < 694971d update phrase to hola world > c3ffff1 changed text to hello mundo
If you run that with the -p option instead, you get just the diffs to the file that ended up in conflict.
This can be really helpful in quickly giving you the context you need to help understand why something conflicts and how to more intelligently resolve it.
Combined Diff Format
Since Git stages any merge results that are successful, when you run git diff while in a conflicted merge state, you only get what is currently still in conflict.
This can be helpful to see what you still have to resolve.
When you run git diff directly after a merge conflict, it will give you information in a rather unique diff output format.
$ git diff diff --cc hello.rb index 0399cd5,59727f0..0000000 --- a/hello.rb +++ b/hello.rb @@@ -1,7 -1,7 +1,11 @@@ #! /usr/bin/env ruby def hello ++<<<<<<< HEAD + puts 'hola world' ++======= + puts 'hello mundo' ++>>>>>>> mundo end hello()
The format is called Combined Diff'' and gives you two columns of data next to each line.
The first column shows you if that line is different (added or removed) between the ours'' branch and the file in your working directory and the second column does the same between the ``theirs'' branch and your working directory copy.
So in that example you can see that the <<<<<<< and >>>>>>> lines are in the working copy but were not in either side of the merge.
This makes sense because the merge tool stuck them in there for our context, but we’re expected to remove them.
If we resolve the conflict and run git diff again, we’ll see the same thing, but it’s a little more useful.
$ vim hello.rb $ git diff diff --cc hello.rb index 0399cd5,59727f0..0000000 --- a/hello.rb +++ b/hello.rb @@@ -1,7 -1,7 +1,7 @@@ #! /usr/bin/env ruby def hello - puts 'hola world' - puts 'hello mundo' ++ puts 'hola mundo' end hello()
This shows us that hola world'' was in our side but not in the working copy, that hello mundo'' was in their side but not in the working copy and finally that ``hola mundo'' was not in either side but is now in the working copy.
This can be useful to review before committing the resolution.
You can also get this from the git log for any merge to see how something was resolved after the fact.
Git will output this format if you run git show on a merge commit, or if you add a --cc option to a git log -p (which by default only shows patches for non-merge commits).
$ git log --cc -p -1
commit 14f41939956d80b9e17bb8721354c33f8d5b5a79
Merge: f1270f7 e3eb223
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Sep 19 18:14:49 2014 +0200
Merge branch 'mundo'
Conflicts:
hello.rb
diff --cc hello.rb
index 0399cd5,59727f0..e1d0799
--- a/hello.rb
+++ b/hello.rb
@@@ -1,7 -1,7 +1,7 @@@
#! /usr/bin/env ruby
def hello
- puts 'hola world'
- puts 'hello mundo'
++ puts 'hola mundo'
end
hello()
Undoing Merges
Now that you know how to create a merge commit, you’ll probably make some by mistake. One of the great things about working with Git is that it’s okay to make mistakes, because it’s possible (and in many cases easy) to fix them.
Merge commits are no different.
Let’s say you started work on a topic branch, accidentally merged it into master, and now your commit history looks like this:
There are two ways to approach this problem, depending on what your desired outcome is.
Fix the references
If the unwanted merge commit only exists on your local repository, the easiest and best solution is to move the branches so that they point where you want them to.
In most cases, if you follow the errant git merge with git reset --hard HEAD~, this will reset the branch pointers so they look like this:
git reset --hard HEAD~We covered reset back in Reset Demystified, so it shouldn’t be too hard to figure out what’s going on here.
Here’s a quick refresher: reset --hard usually goes through three steps:
-
Move the branch HEAD points to. In this case, we want to move
masterto where it was before the merge commit (C6). -
Make the index look like HEAD.
-
Make the working directory look like the index.
The downside of this approach is that it’s rewriting history, which can be problematic with a shared repository.
Check out The Perils of Rebasing for more on what can happen; the short version is that if other people have the commits you’re rewriting, you should probably avoid reset.
This approach also won’t work if any other commits have been created since the merge; moving the refs would effectively lose those changes.
Reverse the commit
If moving the branch pointers around isn’t going to work for you, Git gives you the option of making a new commit which undoes all the changes from an existing one. Git calls this operation a ``revert'', and in this particular scenario, you’d invoke it like this:
$ git revert -m 1 HEAD [master b1d8379] Revert "Merge branch 'topic'"
The -m 1 flag indicates which parent is the `mainline'' and should be kept.
When you invoke a merge into `HEAD (git merge topic), the new commit has two parents: the first one is HEAD (C6), and the second is the tip of the branch being merged in (C4).
In this case, we want to undo all the changes introduced by merging in parent #2 (C4), while keeping all the content from parent #1 (C6).
The history with the revert commit looks like this:
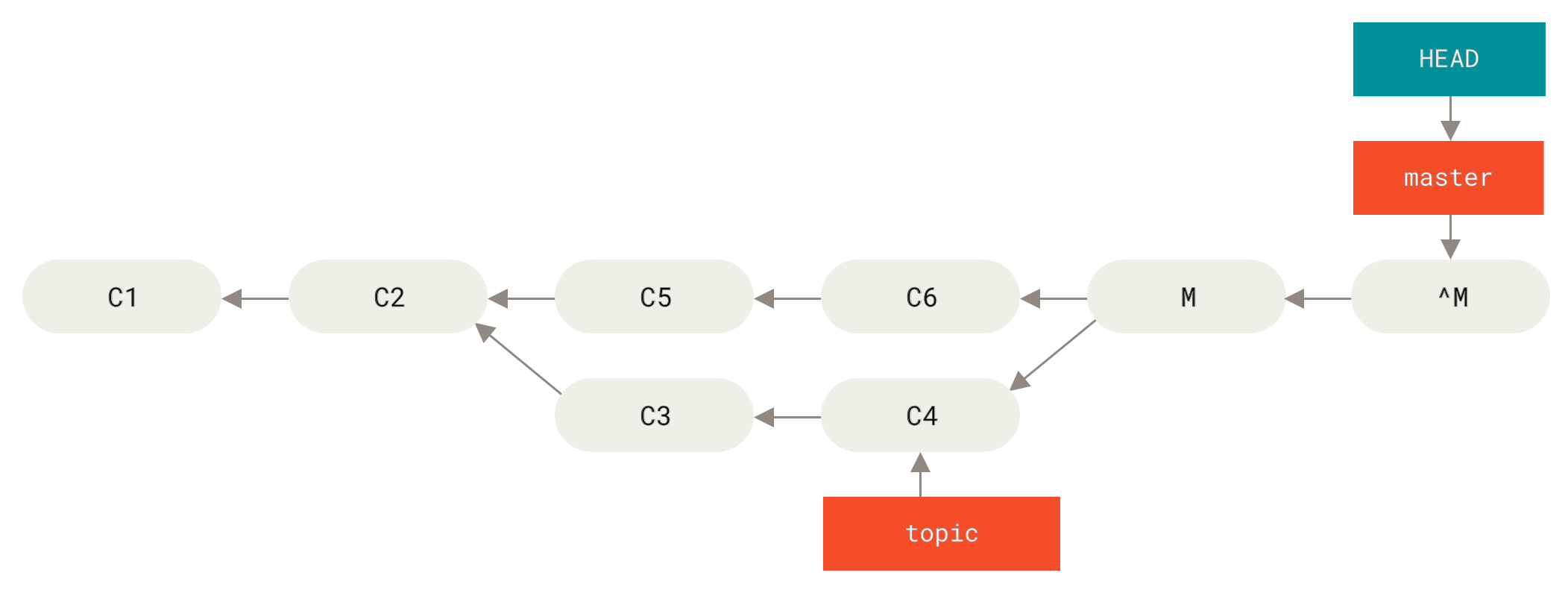
git revert -m 1The new commit ^M has exactly the same contents as C6, so starting from here it’s as if the merge never happened, except that the now-unmerged commits are still in HEAD’s history.
Git will get confused if you try to merge `topic into master again:
$ git merge topic Already up-to-date.
There’s nothing in topic that isn’t already reachable from master.
What’s worse, if you add work to topic and merge again, Git will only bring in the changes since the reverted merge:
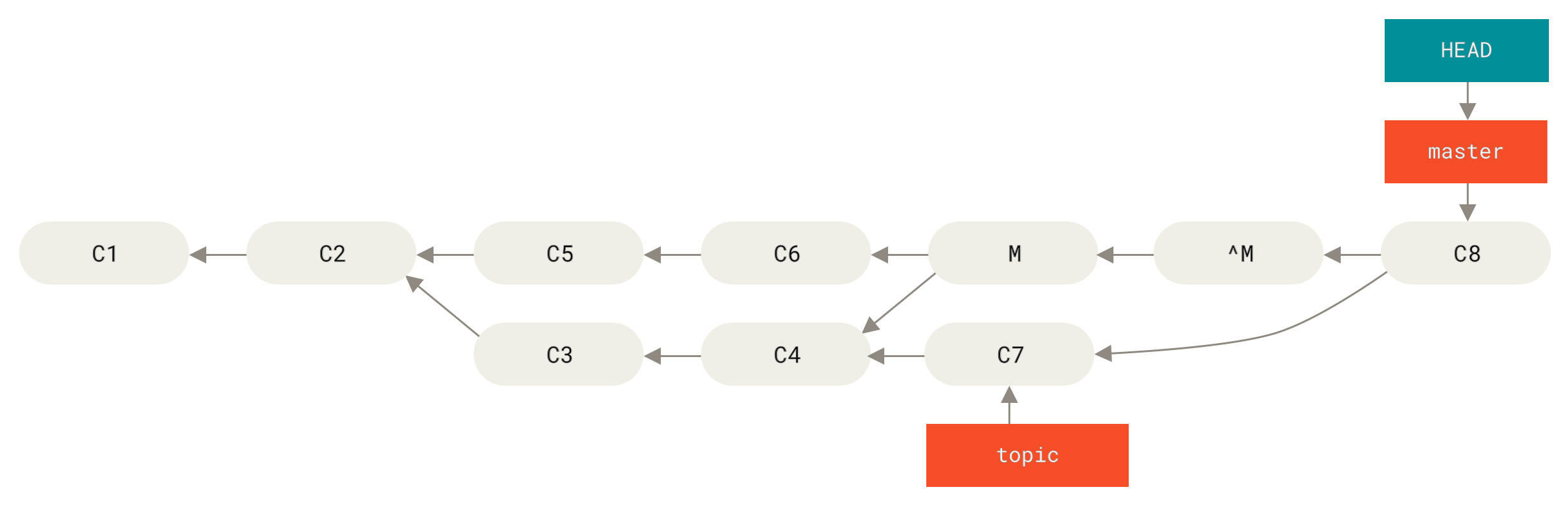
The best way around this is to un-revert the original merge, since now you want to bring in the changes that were reverted out, then create a new merge commit:
$ git revert ^M [master 09f0126] Revert "Revert "Merge branch 'topic'"" $ git merge topic
In this example, M and ^M cancel out.
^^M effectively merges in the changes from C3 and C4, and C8 merges in the changes from C7, so now topic is fully merged.
Other Types of Merges
So far we’ve covered the normal merge of two branches, normally handled with what is called the ``recursive'' strategy of merging. There are other ways to merge branches together however. Let’s cover a few of them quickly.
Our or Theirs Preference
First of all, there is another useful thing we can do with the normal `recursive'' mode of merging.
We’ve already seen the `ignore-all-space and ignore-space-change options which are passed with a -X but we can also tell Git to favor one side or the other when it sees a conflict.
By default, when Git sees a conflict between two branches being merged, it will add merge conflict markers into your code and mark the file as conflicted and let you resolve it.
If you would prefer for Git to simply choose a specific side and ignore the other side instead of letting you manually resolve the conflict, you can pass the merge command either a -Xours or -Xtheirs.
If Git sees this, it will not add conflict markers. Any differences that are mergeable, it will merge. Any differences that conflict, it will simply choose the side you specify in whole, including binary files.
If we go back to the ``hello world'' example we were using before, we can see that merging in our branch causes conflicts.
$ git merge mundo Auto-merging hello.rb CONFLICT (content): Merge conflict in hello.rb Resolved 'hello.rb' using previous resolution. Automatic merge failed; fix conflicts and then commit the result.
However if we run it with -Xours or -Xtheirs it does not.
$ git merge -Xours mundo Auto-merging hello.rb Merge made by the 'recursive' strategy. hello.rb | 2 +- test.sh | 2 ++ 2 files changed, 3 insertions(+), 1 deletion(-) create mode 100644 test.sh
In that case, instead of getting conflict markers in the file with hello mundo'' on one side and hola world'' on the other, it will simply pick ``hola world''.
However, all the other non-conflicting changes on that branch are merged successfully in.
This option can also be passed to the git merge-file command we saw earlier by running something like git merge-file --ours for individual file merges.
If you want to do something like this but not have Git even try to merge changes from the other side in, there is a more draconian option, which is the ours'' merge strategy.
This is different from the ours'' recursive merge option.
This will basically do a fake merge. It will record a new merge commit with both branches as parents, but it will not even look at the branch you’re merging in. It will simply record as the result of the merge the exact code in your current branch.
$ git merge -s ours mundo Merge made by the 'ours' strategy. $ git diff HEAD HEAD~ $
You can see that there is no difference between the branch we were on and the result of the merge.
This can often be useful to basically trick Git into thinking that a branch is already merged when doing a merge later on.
For example, say you branched off a release branch and have done some work on it that you will want to merge back into your master branch at some point.
In the meantime some bugfix on master needs to be backported into your release branch.
You can merge the bugfix branch into the release branch and also merge -s ours the same branch into your master branch (even though the fix is already there) so when you later merge the release branch again, there are no conflicts from the bugfix.
Subtree Merging
The idea of the subtree merge is that you have two projects, and one of the projects maps to a subdirectory of the other one. When you specify a subtree merge, Git is often smart enough to figure out that one is a subtree of the other and merge appropriately.
We’ll go through an example of adding a separate project into an existing project and then merging the code of the second into a subdirectory of the first.
First, we’ll add the Rack application to our project. We’ll add the Rack project as a remote reference in our own project and then check it out into its own branch:
$ git remote add rack_remote https://github.com/rack/rack $ git fetch rack_remote --no-tags warning: no common commits remote: Counting objects: 3184, done. remote: Compressing objects: 100% (1465/1465), done. remote: Total 3184 (delta 1952), reused 2770 (delta 1675) Receiving objects: 100% (3184/3184), 677.42 KiB | 4 KiB/s, done. Resolving deltas: 100% (1952/1952), done. From https://github.com/rack/rack * [new branch] build -> rack_remote/build * [new branch] master -> rack_remote/master * [new branch] rack-0.4 -> rack_remote/rack-0.4 * [new branch] rack-0.9 -> rack_remote/rack-0.9 $ git checkout -b rack_branch rack_remote/master Branch rack_branch set up to track remote branch refs/remotes/rack_remote/master. Switched to a new branch "rack_branch"
Now we have the root of the Rack project in our rack_branch branch and our own project in the master branch.
If you check out one and then the other, you can see that they have different project roots:
$ ls AUTHORS KNOWN-ISSUES Rakefile contrib lib COPYING README bin example test $ git checkout master Switched to branch "master" $ ls README
This is sort of a strange concept. Not all the branches in your repository actually have to be branches of the same project. It’s not common, because it’s rarely helpful, but it’s fairly easy to have branches contain completely different histories.
In this case, we want to pull the Rack project into our master project as a subdirectory.
We can do that in Git with git read-tree.
You’ll learn more about read-tree and its friends in Git Internals, but for now know that it reads the root tree of one branch into your current staging area and working directory.
We just switched back to your master branch, and we pull the rack_branch branch into the rack subdirectory of our master branch of our main project:
$ git read-tree --prefix=rack/ -u rack_branch
When we commit, it looks like we have all the Rack files under that subdirectory – as though we copied them in from a tarball. What gets interesting is that we can fairly easily merge changes from one of the branches to the other. So, if the Rack project updates, we can pull in upstream changes by switching to that branch and pulling:
$ git checkout rack_branch $ git pull
Then, we can merge those changes back into our master branch.
To pull in the changes and prepopulate the commit message, use the --squash option, as well as the recursive merge strategy’s -Xsubtree option.
(The recursive strategy is the default here, but we include it for clarity.)
$ git checkout master $ git merge --squash -s recursive -Xsubtree=rack rack_branch Squash commit -- not updating HEAD Automatic merge went well; stopped before committing as requested
All the changes from the Rack project are merged in and ready to be committed locally.
You can also do the opposite – make changes in the rack subdirectory of your master branch and then merge them into your rack_branch branch later to submit them to the maintainers or push them upstream.
This gives us a way to have a workflow somewhat similar to the submodule workflow without using submodules (which we will cover in Submodules). We can keep branches with other related projects in our repository and subtree merge them into our project occasionally. It is nice in some ways, for example all the code is committed to a single place. However, it has other drawbacks in that it’s a bit more complex and easier to make mistakes in reintegrating changes or accidentally pushing a branch into an unrelated repository.
Another slightly weird thing is that to get a diff between what you have in your rack subdirectory and the code in your rack_branch branch – to see if you need to merge them – you can’t use the normal diff command.
Instead, you must run git diff-tree with the branch you want to compare to:
$ git diff-tree -p rack_branch
Or, to compare what is in your rack subdirectory with what the master branch on the server was the last time you fetched, you can run
$ git diff-tree -p rack_remote/master
Rerere
The git rerere functionality is a bit of a hidden feature.
The name stands for ``reuse recorded resolution'' and, as the name implies, it allows you to ask Git to remember how you’ve resolved a hunk conflict so that the next time it sees the same conflict, Git can resolve it for you automatically.
There are a number of scenarios in which this functionality might be really handy.
One of the examples that is mentioned in the documentation is when you want to make sure a long-lived topic branch will ultimately merge cleanly, but you don’t want to have a bunch of intermediate merge commits cluttering up your commit history.
With rerere enabled, you can attempt the occasional merge, resolve the conflicts, then back out of the merge.
If you do this continuously, then the final merge should be easy because rerere can just do everything for you automatically.
This same tactic can be used if you want to keep a branch rebased so you don’t have to deal with the same rebasing conflicts each time you do it. Or if you want to take a branch that you merged and fixed a bunch of conflicts and then decide to rebase it instead — you likely won’t have to do all the same conflicts again.
Another application of rerere is where you merge a bunch of evolving topic branches together into a testable head occasionally, as the Git project itself often does.
If the tests fail, you can rewind the merges and re-do them without the topic branch that made the tests fail without having to re-resolve the conflicts again.
To enable rerere functionality, you simply have to run this config setting:
$ git config --global rerere.enabled true
You can also turn it on by creating the .git/rr-cache directory in a specific repository, but the config setting is clearer and enables that feature globally for you.
Now let’s see a simple example, similar to our previous one.
Let’s say we have a file named hello.rb that looks like this:
#! /usr/bin/env ruby def hello puts 'hello world' end
In one branch we change the word hello'' to hola'', then in another branch we change the world'' to mundo'', just like before.
When we merge the two branches together, we’ll get a merge conflict:
$ git merge i18n-world Auto-merging hello.rb CONFLICT (content): Merge conflict in hello.rb Recorded preimage for 'hello.rb' Automatic merge failed; fix conflicts and then commit the result.
You should notice the new line Recorded preimage for FILE in there.
Otherwise it should look exactly like a normal merge conflict.
At this point, rerere can tell us a few things.
Normally, you might run git status at this point to see what all conflicted:
$ git status # On branch master # Unmerged paths: # (use "git reset HEAD <file>..." to unstage) # (use "git add <file>..." to mark resolution) # # both modified: hello.rb #
However, git rerere will also tell you what it has recorded the pre-merge state for with git rerere status:
$ git rerere status hello.rb
And git rerere diff will show the current state of the resolution — what you started with to resolve and what you’ve resolved it to.
$ git rerere diff --- a/hello.rb +++ b/hello.rb @@ -1,11 +1,11 @@ #! /usr/bin/env ruby def hello -<<<<<<< - puts 'hello mundo' -======= +<<<<<<< HEAD puts 'hola world' ->>>>>>> +======= + puts 'hello mundo' +>>>>>>> i18n-world end
Also (and this isn’t really related to rerere), you can use git ls-files -u to see the conflicted files and the before, left and right versions:
$ git ls-files -u 100644 39804c942a9c1f2c03dc7c5ebcd7f3e3a6b97519 1 hello.rb 100644 a440db6e8d1fd76ad438a49025a9ad9ce746f581 2 hello.rb 100644 54336ba847c3758ab604876419607e9443848474 3 hello.rb
Now you can resolve it to just be puts 'hola mundo' and you can run git rerere diff again to see what rerere will remember:
$ git rerere diff --- a/hello.rb +++ b/hello.rb @@ -1,11 +1,7 @@ #! /usr/bin/env ruby def hello -<<<<<<< - puts 'hello mundo' -======= - puts 'hola world' ->>>>>>> + puts 'hola mundo' end
So that basically says, when Git sees a hunk conflict in a hello.rb file that has hello mundo'' on one side and hola world'' on the other, it will resolve it to ``hola mundo''.
Now we can mark it as resolved and commit it:
$ git add hello.rb $ git commit Recorded resolution for 'hello.rb'. [master 68e16e5] Merge branch 'i18n'
You can see that it "Recorded resolution for FILE".
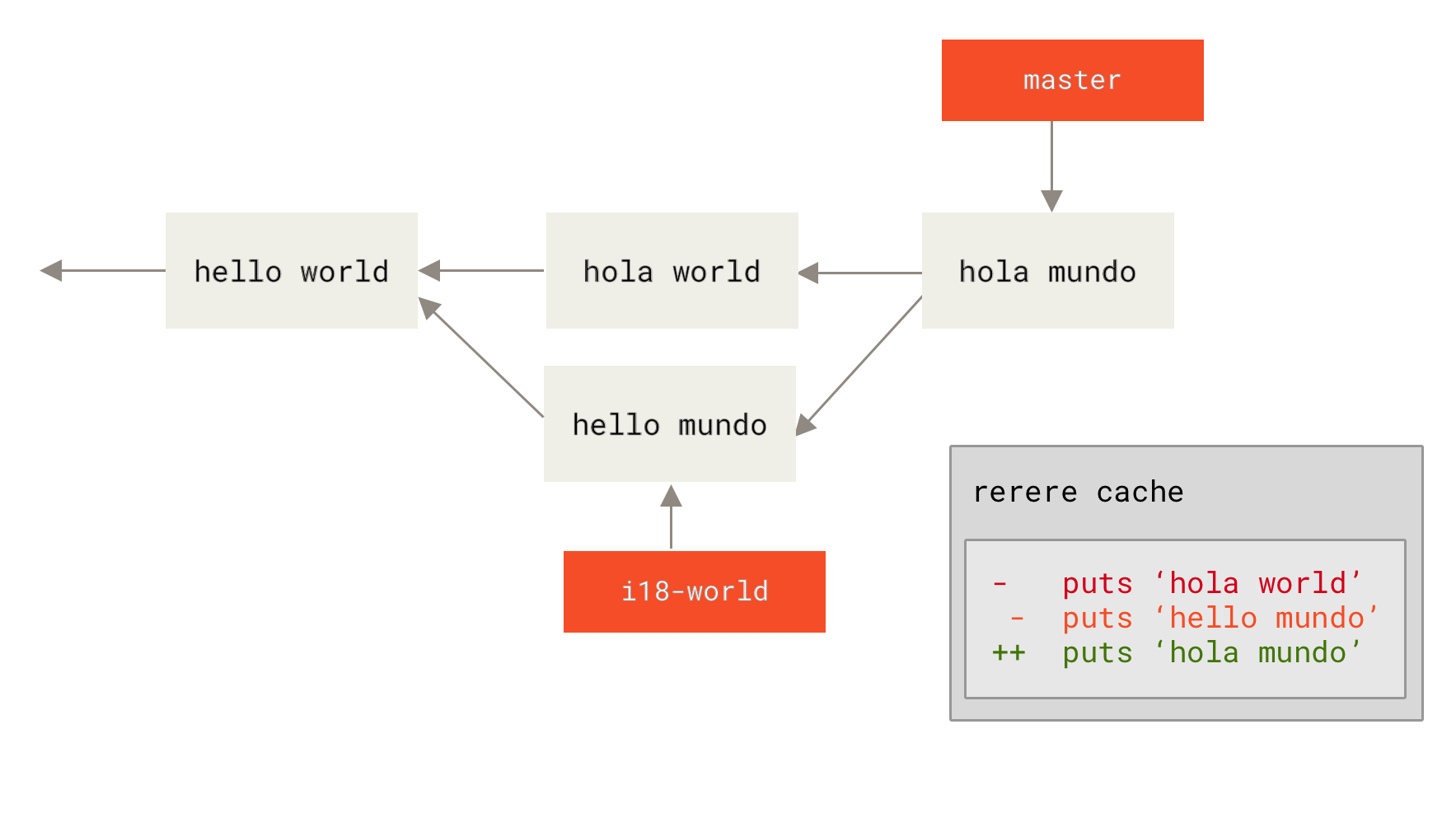
Now, let’s undo that merge and then rebase it on top of our master branch instead.
We can move our branch back by using git reset as we saw in Reset Demystified.
$ git reset --hard HEAD^ HEAD is now at ad63f15 i18n the hello
Our merge is undone. Now let’s rebase the topic branch.
$ git checkout i18n-world Switched to branch 'i18n-world' $ git rebase master First, rewinding head to replay your work on top of it... Applying: i18n one word Using index info to reconstruct a base tree... Falling back to patching base and 3-way merge... Auto-merging hello.rb CONFLICT (content): Merge conflict in hello.rb Resolved 'hello.rb' using previous resolution. Failed to merge in the changes. Patch failed at 0001 i18n one word
Now, we got the same merge conflict like we expected, but take a look at the Resolved FILE using previous resolution line.
If we look at the file, we’ll see that it’s already been resolved, there are no merge conflict markers in it.
#! /usr/bin/env ruby def hello puts 'hola mundo' end
Also, git diff will show you how it was automatically re-resolved:
$ git diff diff --cc hello.rb index a440db6,54336ba..0000000 --- a/hello.rb +++ b/hello.rb @@@ -1,7 -1,7 +1,7 @@@ #! /usr/bin/env ruby def hello - puts 'hola world' - puts 'hello mundo' ++ puts 'hola mundo' end
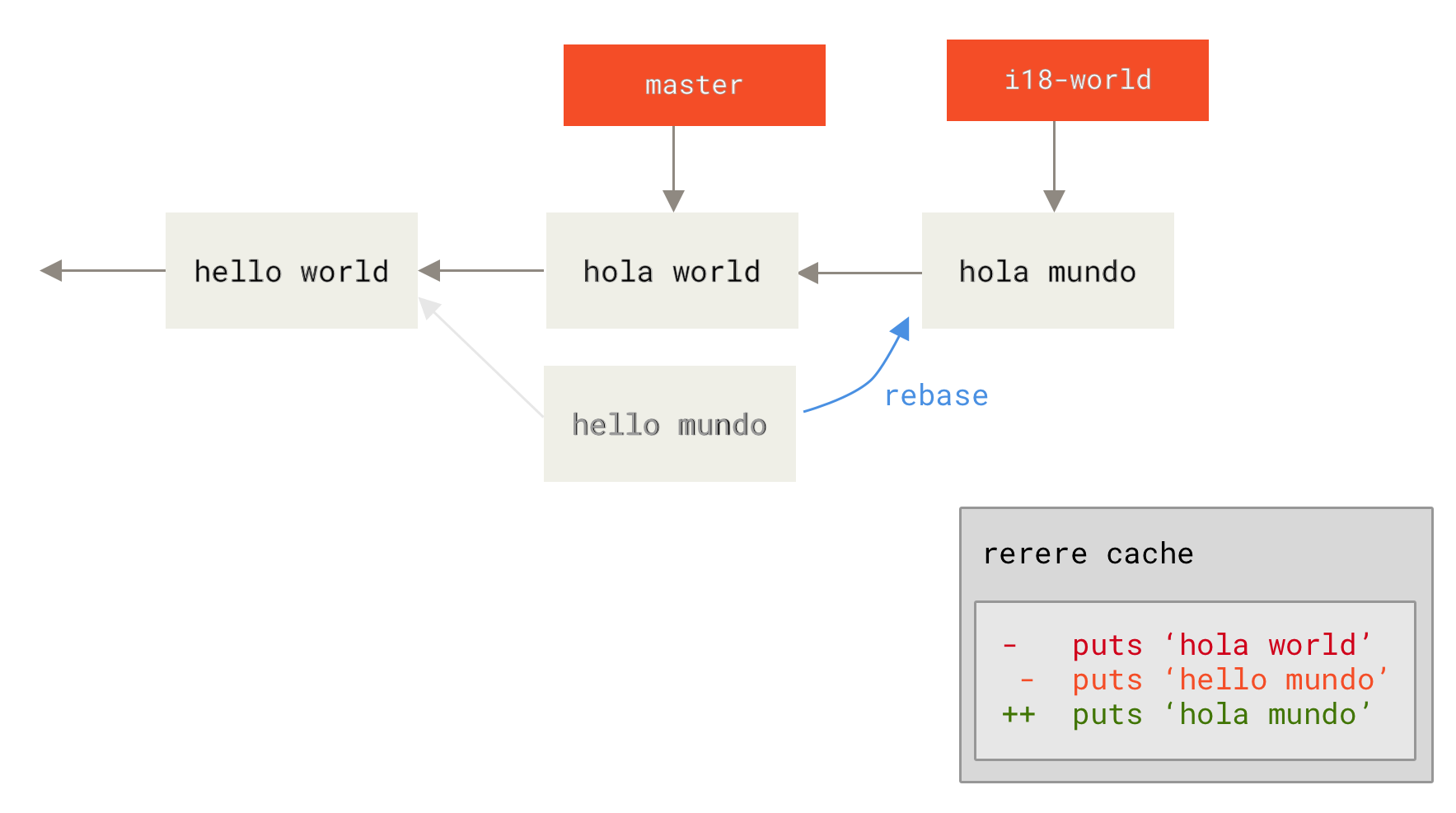
You can also recreate the conflicted file state with git checkout:
$ git checkout --conflict=merge hello.rb $ cat hello.rb #! /usr/bin/env ruby def hello <<<<<<< ours puts 'hola world' ======= puts 'hello mundo' >>>>>>> theirs end
We saw an example of this in Advanced Merging.
For now though, let’s re-resolve it by just running git rerere again:
$ git rerere Resolved 'hello.rb' using previous resolution. $ cat hello.rb #! /usr/bin/env ruby def hello puts 'hola mundo' end
We have re-resolved the file automatically using the rerere cached resolution.
You can now add and continue the rebase to complete it.
$ git add hello.rb $ git rebase --continue Applying: i18n one word
So, if you do a lot of re-merges, or want to keep a topic branch up to date with your master branch without a ton of merges, or you rebase often, you can turn on rerere to help your life out a bit.
Debugging with Git
In addition to being primarily for version control, Git also provides a couple commands to help you debug your source code projects. Because Git is designed to handle nearly any type of content, these tools are pretty generic, but they can often help you hunt for a bug or culprit when things go wrong.
File Annotation
If you track down a bug in your code and want to know when it was introduced and why, file annotation is often your best tool.
It shows you what commit was the last to modify each line of any file.
So if you see that a method in your code is buggy, you can annotate the file with git blame to determine which commit was responsible for the introduction of that line.
The following example uses git blame to determine which commit and committer was responsible for lines in the top-level Linux kernel Makefile and, further, uses the -L option to restrict the output of the annotation to lines 69 through 82 of that file:
$ git blame -L 69,82 Makefile
b8b0618cf6fab (Cheng Renquan 2009-05-26 16:03:07 +0800 69) ifeq ("$(origin V)", "command line")
b8b0618cf6fab (Cheng Renquan 2009-05-26 16:03:07 +0800 70) KBUILD_VERBOSE = $(V)
^1da177e4c3f4 (Linus Torvalds 2005-04-16 15:20:36 -0700 71) endif
^1da177e4c3f4 (Linus Torvalds 2005-04-16 15:20:36 -0700 72) ifndef KBUILD_VERBOSE
^1da177e4c3f4 (Linus Torvalds 2005-04-16 15:20:36 -0700 73) KBUILD_VERBOSE = 0
^1da177e4c3f4 (Linus Torvalds 2005-04-16 15:20:36 -0700 74) endif
^1da177e4c3f4 (Linus Torvalds 2005-04-16 15:20:36 -0700 75)
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 76) ifeq ($(KBUILD_VERBOSE),1)
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 77) quiet =
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 78) Q =
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 79) else
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 80) quiet=quiet_
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 81) Q = @
066b7ed955808 (Michal Marek 2014-07-04 14:29:30 +0200 82) endif
Notice that the first field is the partial SHA-1 of the commit that last modified that line.
The next two fields are values extracted from that commit — the author name and the authored date of that commit — so you can easily see who modified that line and when.
After that come the line number and the content of the file.
Also note the ^1da177e4c3f4 commit lines, where the ^ prefix designates lines that were introduced in the repository’s initial commit and have remained unchanged ever since.
This is a tad confusing, because now you’ve seen at least three different ways that Git uses the ^ to modify a commit SHA-1, but that is what it means here.
Another cool thing about Git is that it doesn’t track file renames explicitly.
It records the snapshots and then tries to figure out what was renamed implicitly, after the fact.
One of the interesting features of this is that you can ask it to figure out all sorts of code movement as well.
If you pass -C to git blame, Git analyzes the file you’re annotating and tries to figure out where snippets of code within it originally came from if they were copied from elsewhere.
For example, say you are refactoring a file named GITServerHandler.m into multiple files, one of which is GITPackUpload.m.
By blaming GITPackUpload.m with the -C option, you can see where sections of the code originally came from:
$ git blame -C -L 141,153 GITPackUpload.m
f344f58d GITServerHandler.m (Scott 2009-01-04 141)
f344f58d GITServerHandler.m (Scott 2009-01-04 142) - (void) gatherObjectShasFromC
f344f58d GITServerHandler.m (Scott 2009-01-04 143) {
70befddd GITServerHandler.m (Scott 2009-03-22 144) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 145)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 146) NSString *parentSha;
ad11ac80 GITPackUpload.m (Scott 2009-03-24 147) GITCommit *commit = [g
ad11ac80 GITPackUpload.m (Scott 2009-03-24 148)
ad11ac80 GITPackUpload.m (Scott 2009-03-24 149) //NSLog(@"GATHER COMMI
ad11ac80 GITPackUpload.m (Scott 2009-03-24 150)
56ef2caf GITServerHandler.m (Scott 2009-01-05 151) if(commit) {
56ef2caf GITServerHandler.m (Scott 2009-01-05 152) [refDict setOb
56ef2caf GITServerHandler.m (Scott 2009-01-05 153)
This is really useful. Normally, you get as the original commit the commit where you copied the code over, because that is the first time you touched those lines in this file. Git tells you the original commit where you wrote those lines, even if it was in another file.
Binary Search
Annotating a file helps if you know where the issue is to begin with.
If you don’t know what is breaking, and there have been dozens or hundreds of commits since the last state where you know the code worked, you’ll likely turn to git bisect for help.
The bisect command does a binary search through your commit history to help you identify as quickly as possible which commit introduced an issue.
Let’s say you just pushed out a release of your code to a production environment, you’re getting bug reports about something that wasn’t happening in your development environment, and you can’t imagine why the code is doing that.
You go back to your code, and it turns out you can reproduce the issue, but you can’t figure out what is going wrong.
You can bisect the code to find out.
First you run git bisect start to get things going, and then you use git bisect bad to tell the system that the current commit you’re on is broken.
Then, you must tell bisect when the last known good state was, using git bisect good <good_commit>:
$ git bisect start $ git bisect bad $ git bisect good v1.0 Bisecting: 6 revisions left to test after this [ecb6e1bc347ccecc5f9350d878ce677feb13d3b2] error handling on repo
Git figured out that about 12 commits came between the commit you marked as the last good commit (v1.0) and the current bad version, and it checked out the middle one for you.
At this point, you can run your test to see if the issue exists as of this commit.
If it does, then it was introduced sometime before this middle commit; if it doesn’t, then the problem was introduced sometime after the middle commit.
It turns out there is no issue here, and you tell Git that by typing git bisect good and continue your journey:
$ git bisect good Bisecting: 3 revisions left to test after this [b047b02ea83310a70fd603dc8cd7a6cd13d15c04] secure this thing
Now you’re on another commit, halfway between the one you just tested and your bad commit.
You run your test again and find that this commit is broken, so you tell Git that with git bisect bad:
$ git bisect bad Bisecting: 1 revisions left to test after this [f71ce38690acf49c1f3c9bea38e09d82a5ce6014] drop exceptions table
This commit is fine, and now Git has all the information it needs to determine where the issue was introduced. It tells you the SHA-1 of the first bad commit and show some of the commit information and which files were modified in that commit so you can figure out what happened that may have introduced this bug:
$ git bisect good
b047b02ea83310a70fd603dc8cd7a6cd13d15c04 is first bad commit
commit b047b02ea83310a70fd603dc8cd7a6cd13d15c04
Author: PJ Hyett <pjhyett@example.com>
Date: Tue Jan 27 14:48:32 2009 -0800
secure this thing
:040000 040000 40ee3e7821b895e52c1695092db9bdc4c61d1730
f24d3c6ebcfc639b1a3814550e62d60b8e68a8e4 M config
When you’re finished, you should run git bisect reset to reset your HEAD to where you were before you started, or you’ll end up in a weird state:
$ git bisect reset
This is a powerful tool that can help you check hundreds of commits for an introduced bug in minutes.
In fact, if you have a script that will exit 0 if the project is good or non-0 if the project is bad, you can fully automate git bisect.
First, you again tell it the scope of the bisect by providing the known bad and good commits.
You can do this by listing them with the bisect start command if you want, listing the known bad commit first and the known good commit second:
$ git bisect start HEAD v1.0 $ git bisect run test-error.sh
Doing so automatically runs test-error.sh on each checked-out commit until Git finds the first broken commit.
You can also run something like make or make tests or whatever you have that runs automated tests for you.
Submodules
It often happens that while working on one project, you need to use another project from within it. Perhaps it’s a library that a third party developed or that you’re developing separately and using in multiple parent projects. A common issue arises in these scenarios: you want to be able to treat the two projects as separate yet still be able to use one from within the other.
Here’s an example. Suppose you’re developing a website and creating Atom feeds. Instead of writing your own Atom-generating code, you decide to use a library. You’re likely to have to either include this code from a shared library like a CPAN install or Ruby gem, or copy the source code into your own project tree. The issue with including the library is that it’s difficult to customize the library in any way and often more difficult to deploy it, because you need to make sure every client has that library available. The issue with copying the code into your own project is that any custom changes you make are difficult to merge when upstream changes become available.
Git addresses this issue using submodules. Submodules allow you to keep a Git repository as a subdirectory of another Git repository. This lets you clone another repository into your project and keep your commits separate.
Starting with Submodules
We’ll walk through developing a simple project that has been split up into a main project and a few sub-projects.
Let’s start by adding an existing Git repository as a submodule of the repository that we’re working on.
To add a new submodule you use the git submodule add command with the absolute or relative URL of the project you would like to start tracking.
In this example, we’ll add a library called ``DbConnector''.
$ git submodule add https://github.com/chaconinc/DbConnector Cloning into 'DbConnector'... remote: Counting objects: 11, done. remote: Compressing objects: 100% (10/10), done. remote: Total 11 (delta 0), reused 11 (delta 0) Unpacking objects: 100% (11/11), done. Checking connectivity... done.
By default, submodules will add the subproject into a directory named the same as the repository, in this case ``DbConnector''. You can add a different path at the end of the command if you want it to go elsewhere.
If you run git status at this point, you’ll notice a few things.
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: .gitmodules new file: DbConnector
First you should notice the new .gitmodules file.
This is a configuration file that stores the mapping between the project’s URL and the local subdirectory you’ve pulled it into:
[submodule "DbConnector"] path = DbConnector url = https://github.com/chaconinc/DbConnector
If you have multiple submodules, you’ll have multiple entries in this file.
It’s important to note that this file is version-controlled with your other files, like your .gitignore file.
It’s pushed and pulled with the rest of your project.
This is how other people who clone this project know where to get the submodule projects from.
Since the URL in the .gitmodules file is what other people will first try to clone/fetch from, make sure to use a URL that they can access if possible.
For example, if you use a different URL to push to than others would to pull from, use the one that others have access to.
You can overwrite this value locally with git config submodule.DbConnector.url PRIVATE_URL for your own use.
When applicable, a relative URL can be helpful.
The other listing in the git status output is the project folder entry.
If you run git diff on that, you see something interesting:
$ git diff --cached DbConnector diff --git a/DbConnector b/DbConnector new file mode 160000 index 0000000..c3f01dc --- /dev/null +++ b/DbConnector @@ -0,0 +1 @@ +Subproject commit c3f01dc8862123d317dd46284b05b6892c7b29bc
Although DbConnector is a subdirectory in your working directory, Git sees it as a submodule and doesn’t track its contents when you’re not in that directory.
Instead, Git sees it as a particular commit from that repository.
If you want a little nicer diff output, you can pass the --submodule option to git diff.
$ git diff --cached --submodule diff --git a/.gitmodules b/.gitmodules new file mode 100644 index 0000000..71fc376 --- /dev/null +++ b/.gitmodules @@ -0,0 +1,3 @@ +[submodule "DbConnector"] + path = DbConnector + url = https://github.com/chaconinc/DbConnector Submodule DbConnector 0000000...c3f01dc (new submodule)
When you commit, you see something like this:
$ git commit -am 'added DbConnector module' [master fb9093c] added DbConnector module 2 files changed, 4 insertions(+) create mode 100644 .gitmodules create mode 160000 DbConnector
Notice the 160000 mode for the DbConnector entry.
That is a special mode in Git that basically means you’re recording a commit as a directory entry rather than a subdirectory or a file.
Lastly, push these changes:
$ git push origin master
Cloning a Project with Submodules
Here we’ll clone a project with a submodule in it. When you clone such a project, by default you get the directories that contain submodules, but none of the files within them yet:
$ git clone https://github.com/chaconinc/MainProject Cloning into 'MainProject'... remote: Counting objects: 14, done. remote: Compressing objects: 100% (13/13), done. remote: Total 14 (delta 1), reused 13 (delta 0) Unpacking objects: 100% (14/14), done. Checking connectivity... done. $ cd MainProject $ ls -la total 16 drwxr-xr-x 9 schacon staff 306 Sep 17 15:21 . drwxr-xr-x 7 schacon staff 238 Sep 17 15:21 .. drwxr-xr-x 13 schacon staff 442 Sep 17 15:21 .git -rw-r--r-- 1 schacon staff 92 Sep 17 15:21 .gitmodules drwxr-xr-x 2 schacon staff 68 Sep 17 15:21 DbConnector -rw-r--r-- 1 schacon staff 756 Sep 17 15:21 Makefile drwxr-xr-x 3 schacon staff 102 Sep 17 15:21 includes drwxr-xr-x 4 schacon staff 136 Sep 17 15:21 scripts drwxr-xr-x 4 schacon staff 136 Sep 17 15:21 src $ cd DbConnector/ $ ls $
The DbConnector directory is there, but empty.
You must run two commands: git submodule init to initialize your local configuration file, and git submodule update to fetch all the data from that project and check out the appropriate commit listed in your superproject:
$ git submodule init Submodule 'DbConnector' (https://github.com/chaconinc/DbConnector) registered for path 'DbConnector' $ git submodule update Cloning into 'DbConnector'... remote: Counting objects: 11, done. remote: Compressing objects: 100% (10/10), done. remote: Total 11 (delta 0), reused 11 (delta 0) Unpacking objects: 100% (11/11), done. Checking connectivity... done. Submodule path 'DbConnector': checked out 'c3f01dc8862123d317dd46284b05b6892c7b29bc'
Now your DbConnector subdirectory is at the exact state it was in when you committed earlier.
There is another way to do this which is a little simpler, however.
If you pass --recurse-submodules to the git clone command, it will automatically initialize and update each submodule in the repository, including nested submodules if any of the submodules in the repository have submodules themselves.
$ git clone --recurse-submodules https://github.com/chaconinc/MainProject Cloning into 'MainProject'... remote: Counting objects: 14, done. remote: Compressing objects: 100% (13/13), done. remote: Total 14 (delta 1), reused 13 (delta 0) Unpacking objects: 100% (14/14), done. Checking connectivity... done. Submodule 'DbConnector' (https://github.com/chaconinc/DbConnector) registered for path 'DbConnector' Cloning into 'DbConnector'... remote: Counting objects: 11, done. remote: Compressing objects: 100% (10/10), done. remote: Total 11 (delta 0), reused 11 (delta 0) Unpacking objects: 100% (11/11), done. Checking connectivity... done. Submodule path 'DbConnector': checked out 'c3f01dc8862123d317dd46284b05b6892c7b29bc'
If you already cloned the project and forgot --recurse-submodules, you can combine the git submodule init and git submodule update steps by running git submodule update --init.
To also initialize, fetch and checkout any nested submodules, you can use the foolproof git submodule update --init --recursive.
Working on a Project with Submodules
Now we have a copy of a project with submodules in it and will collaborate with our teammates on both the main project and the submodule project.
Pulling in Upstream Changes from the Submodule Remote
The simplest model of using submodules in a project would be if you were simply consuming a subproject and wanted to get updates from it from time to time but were not actually modifying anything in your checkout. Let’s walk through a simple example there.
If you want to check for new work in a submodule, you can go into the directory and run git fetch and git merge the upstream branch to update the local code.
$ git fetch From https://github.com/chaconinc/DbConnector c3f01dc..d0354fc master -> origin/master $ git merge origin/master Updating c3f01dc..d0354fc Fast-forward scripts/connect.sh | 1 + src/db.c | 1 + 2 files changed, 2 insertions(+)
Now if you go back into the main project and run git diff --submodule you can see that the submodule was updated and get a list of commits that were added to it.
If you don’t want to type --submodule every time you run git diff, you can set it as the default format by setting the diff.submodule config value to ``log''.
$ git config --global diff.submodule log $ git diff Submodule DbConnector c3f01dc..d0354fc: > more efficient db routine > better connection routine
If you commit at this point then you will lock the submodule into having the new code when other people update.
There is an easier way to do this as well, if you prefer to not manually fetch and merge in the subdirectory.
If you run git submodule update --remote, Git will go into your submodules and fetch and update for you.
$ git submodule update --remote DbConnector remote: Counting objects: 4, done. remote: Compressing objects: 100% (2/2), done. remote: Total 4 (delta 2), reused 4 (delta 2) Unpacking objects: 100% (4/4), done. From https://github.com/chaconinc/DbConnector 3f19983..d0354fc master -> origin/master Submodule path 'DbConnector': checked out 'd0354fc054692d3906c85c3af05ddce39a1c0644'
This command will by default assume that you want to update the checkout to the master branch of the submodule repository.
You can, however, set this to something different if you want.
For example, if you want to have the DbConnector submodule track that repository’s `stable'' branch, you can set it in either your `.gitmodules file (so everyone else also tracks it), or just in your local .git/config file.
Let’s set it in the .gitmodules file:
$ git config -f .gitmodules submodule.DbConnector.branch stable $ git submodule update --remote remote: Counting objects: 4, done. remote: Compressing objects: 100% (2/2), done. remote: Total 4 (delta 2), reused 4 (delta 2) Unpacking objects: 100% (4/4), done. From https://github.com/chaconinc/DbConnector 27cf5d3..c87d55d stable -> origin/stable Submodule path 'DbConnector': checked out 'c87d55d4c6d4b05ee34fbc8cb6f7bf4585ae6687'
If you leave off the -f .gitmodules it will only make the change for you, but it probably makes more sense to track that information with the repository so everyone else does as well.
When we run git status at this point, Git will show us that we have ``new commits'' on the submodule.
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: .gitmodules modified: DbConnector (new commits) no changes added to commit (use "git add" and/or "git commit -a")
If you set the configuration setting status.submodulesummary, Git will also show you a short summary of changes to your submodules:
$ git config status.submodulesummary 1 $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: .gitmodules modified: DbConnector (new commits) Submodules changed but not updated: * DbConnector c3f01dc...c87d55d (4): > catch non-null terminated lines
At this point if you run git diff we can see both that we have modified our .gitmodules file and also that there are a number of commits that we’ve pulled down and are ready to commit to our submodule project.
$ git diff
diff --git a/.gitmodules b/.gitmodules
index 6fc0b3d..fd1cc29 100644
--- a/.gitmodules
+++ b/.gitmodules
@@ -1,3 +1,4 @@
[submodule "DbConnector"]
path = DbConnector
url = https://github.com/chaconinc/DbConnector
+ branch = stable
Submodule DbConnector c3f01dc..c87d55d:
> catch non-null terminated lines
> more robust error handling
> more efficient db routine
> better connection routine
This is pretty cool as we can actually see the log of commits that we’re about to commit to in our submodule.
Once committed, you can see this information after the fact as well when you run git log -p.
$ git log -p --submodule
commit 0a24cfc121a8a3c118e0105ae4ae4c00281cf7ae
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Sep 17 16:37:02 2014 +0200
updating DbConnector for bug fixes
diff --git a/.gitmodules b/.gitmodules
index 6fc0b3d..fd1cc29 100644
--- a/.gitmodules
+++ b/.gitmodules
@@ -1,3 +1,4 @@
[submodule "DbConnector"]
path = DbConnector
url = https://github.com/chaconinc/DbConnector
+ branch = stable
Submodule DbConnector c3f01dc..c87d55d:
> catch non-null terminated lines
> more robust error handling
> more efficient db routine
> better connection routine
Git will by default try to update all of your submodules when you run git submodule update --remote so if you have a lot of them, you may want to pass the name of just the submodule you want to try to update.
Pulling Upstream Changes from the Project Remote
Let’s now step into the shoes of your collaborator, who has their own local clone of the MainProject repository.
Simply executing git pull to get your newly committed changes is not enough:
$ git pull From https://github.com/chaconinc/MainProject fb9093c..0a24cfc master -> origin/master Fetching submodule DbConnector From https://github.com/chaconinc/DbConnector c3f01dc..c87d55d stable -> origin/stable Updating fb9093c..0a24cfc Fast-forward .gitmodules | 2 +- DbConnector | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-) $ git status On branch master Your branch is up-to-date with 'origin/master'. Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: DbConnector (new commits) Submodules changed but not updated: * DbConnector c87d55d...c3f01dc (4): < catch non-null terminated lines < more robust error handling < more efficient db routine < better connection routine no changes added to commit (use "git add" and/or "git commit -a")
By default, the git pull command recursively fetches submodules changes, as we can see in the output of the first command above.
However, it does not update the submodules.
This is shown by the output of the git status command, which shows the submodule is modified'', and has new commits''.
What’s more, the brackets showing the new commits point left (<), indicating that these commits are recorded in MainProject but are not present in the local DbConnector checkout.
To finalize the update, you need to run git submodule update:
$ git submodule update --init --recursive Submodule path 'vendor/plugins/demo': checked out '48679c6302815f6c76f1fe30625d795d9e55fc56' $ git status On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working tree clean
Note that to be on the safe side, you should run git submodule update with the --init flag in case the MainProject commits you just pulled added new submodules, and with the --recursive flag if any submodules have nested submodules.
If you want to automate this process, you can add the --recurse-submodules flag to the git pull command (since Git 2.14).
This will make Git run git submodule update right after the pull, putting the submodules in the correct state.
Moreover, if you want to make Git always pull with --recurse-submodules, you can set the configuration option submodule.recurse to true (this works for git pull since Git 2.15).
This option will make Git use the --recurse-submodules flag for all commands that support it (except clone).
There is a special situation that can happen when pulling superproject updates: it could be that the upstream repository has changed the URL of the submodule in the .gitmodules file in one of the commits you pull.
This can happen for example if the submodule project changes its hosting platform.
In that case, it is possible for git pull --recurse-submodules, or git submodule update, to fail if the superproject references a submodule commit that is not found in the submodule remote locally configured in your repository.
In order to remedy this situation, the git submodule sync command is required:
# copy the new URL to your local config $ git submodule sync --recursive # update the submodule from the new URL $ git submodule update --init --recursive
Working on a Submodule
It’s quite likely that if you’re using submodules, you’re doing so because you really want to work on the code in the submodule at the same time as you’re working on the code in the main project (or across several submodules). Otherwise you would probably instead be using a simpler dependency management system (such as Maven or Rubygems).
So now let’s go through an example of making changes to the submodule at the same time as the main project and committing and publishing those changes at the same time.
So far, when we’ve run the git submodule update command to fetch changes from the submodule repositories, Git would get the changes and update the files in the subdirectory but will leave the sub-repository in what’s called a `detached HEAD'' state.
This means that there is no local working branch (like `master, for example) tracking changes.
With no working branch tracking changes, that means even if you commit changes to the submodule, those changes will quite possibly be lost the next time you run git submodule update.
You have to do some extra steps if you want changes in a submodule to be tracked.
In order to set up your submodule to be easier to go in and hack on, you need to do two things.
You need to go into each submodule and check out a branch to work on.
Then you need to tell Git what to do if you have made changes and then git submodule update --remote pulls in new work from upstream.
The options are that you can merge them into your local work, or you can try to rebase your local work on top of the new changes.
First of all, let’s go into our submodule directory and check out a branch.
$ cd DbConnector/ $ git checkout stable Switched to branch 'stable'
Let’s try updating our submodule with the `merge'' option.
To specify it manually, we can just add the `--merge option to our update call.
Here we’ll see that there was a change on the server for this submodule and it gets merged in.
$ cd .. $ git submodule update --remote --merge remote: Counting objects: 4, done. remote: Compressing objects: 100% (2/2), done. remote: Total 4 (delta 2), reused 4 (delta 2) Unpacking objects: 100% (4/4), done. From https://github.com/chaconinc/DbConnector c87d55d..92c7337 stable -> origin/stable Updating c87d55d..92c7337 Fast-forward src/main.c | 1 + 1 file changed, 1 insertion(+) Submodule path 'DbConnector': merged in '92c7337b30ef9e0893e758dac2459d07362ab5ea'
If we go into the DbConnector directory, we have the new changes already merged into our local stable branch.
Now let’s see what happens when we make our own local change to the library and someone else pushes another change upstream at the same time.
$ cd DbConnector/ $ vim src/db.c $ git commit -am 'unicode support' [stable f906e16] unicode support 1 file changed, 1 insertion(+)
Now if we update our submodule we can see what happens when we have made a local change and upstream also has a change we need to incorporate.
$ cd .. $ git submodule update --remote --rebase First, rewinding head to replay your work on top of it... Applying: unicode support Submodule path 'DbConnector': rebased into '5d60ef9bbebf5a0c1c1050f242ceeb54ad58da94'
If you forget the --rebase or --merge, Git will just update the submodule to whatever is on the server and reset your project to a detached HEAD state.
$ git submodule update --remote Submodule path 'DbConnector': checked out '5d60ef9bbebf5a0c1c1050f242ceeb54ad58da94'
If this happens, don’t worry, you can simply go back into the directory and check out your branch again (which will still contain your work) and merge or rebase origin/stable (or whatever remote branch you want) manually.
If you haven’t committed your changes in your submodule and you run a submodule update that would cause issues, Git will fetch the changes but not overwrite unsaved work in your submodule directory.
$ git submodule update --remote remote: Counting objects: 4, done. remote: Compressing objects: 100% (3/3), done. remote: Total 4 (delta 0), reused 4 (delta 0) Unpacking objects: 100% (4/4), done. From https://github.com/chaconinc/DbConnector 5d60ef9..c75e92a stable -> origin/stable error: Your local changes to the following files would be overwritten by checkout: scripts/setup.sh Please, commit your changes or stash them before you can switch branches. Aborting Unable to checkout 'c75e92a2b3855c9e5b66f915308390d9db204aca' in submodule path 'DbConnector'
If you made changes that conflict with something changed upstream, Git will let you know when you run the update.
$ git submodule update --remote --merge Auto-merging scripts/setup.sh CONFLICT (content): Merge conflict in scripts/setup.sh Recorded preimage for 'scripts/setup.sh' Automatic merge failed; fix conflicts and then commit the result. Unable to merge 'c75e92a2b3855c9e5b66f915308390d9db204aca' in submodule path 'DbConnector'
You can go into the submodule directory and fix the conflict just as you normally would.
Publishing Submodule Changes
Now we have some changes in our submodule directory. Some of these were brought in from upstream by our updates and others were made locally and aren’t available to anyone else yet as we haven’t pushed them yet.
$ git diff Submodule DbConnector c87d55d..82d2ad3: > Merge from origin/stable > updated setup script > unicode support > remove unnecessary method > add new option for conn pooling
If we commit in the main project and push it up without pushing the submodule changes up as well, other people who try to check out our changes are going to be in trouble since they will have no way to get the submodule changes that are depended on. Those changes will only exist on our local copy.
In order to make sure this doesn’t happen, you can ask Git to check that all your submodules have been pushed properly before pushing the main project.
The git push command takes the --recurse-submodules argument which can be set to either check'' or on-demand''.
The `check'' option will make `push simply fail if any of the committed submodule changes haven’t been pushed.
$ git push --recurse-submodules=check The following submodule paths contain changes that can not be found on any remote: DbConnector Please try git push --recurse-submodules=on-demand or cd to the path and use git push to push them to a remote.
As you can see, it also gives us some helpful advice on what we might want to do next.
The simple option is to go into each submodule and manually push to the remotes to make sure they’re externally available and then try this push again.
If you want the check behavior to happen for all pushes, you can make this behavior the default by doing git config push.recurseSubmodules check.
The other option is to use the ``on-demand'' value, which will try to do this for you.
$ git push --recurse-submodules=on-demand Pushing submodule 'DbConnector' Counting objects: 9, done. Delta compression using up to 8 threads. Compressing objects: 100% (8/8), done. Writing objects: 100% (9/9), 917 bytes | 0 bytes/s, done. Total 9 (delta 3), reused 0 (delta 0) To https://github.com/chaconinc/DbConnector c75e92a..82d2ad3 stable -> stable Counting objects: 2, done. Delta compression using up to 8 threads. Compressing objects: 100% (2/2), done. Writing objects: 100% (2/2), 266 bytes | 0 bytes/s, done. Total 2 (delta 1), reused 0 (delta 0) To https://github.com/chaconinc/MainProject 3d6d338..9a377d1 master -> master
As you can see there, Git went into the DbConnector module and pushed it before pushing the main project.
If that submodule push fails for some reason, the main project push will also fail.
You can make this behavior the default by doing git config push.recurseSubmodules on-demand.
Merging Submodule Changes
If you change a submodule reference at the same time as someone else, you may run into some problems. That is, if the submodule histories have diverged and are committed to diverging branches in a superproject, it may take a bit of work for you to fix.
If one of the commits is a direct ancestor of the other (a fast-forward merge), then Git will simply choose the latter for the merge, so that works fine.
Git will not attempt even a trivial merge for you, however. If the submodule commits diverge and need to be merged, you will get something that looks like this:
$ git pull remote: Counting objects: 2, done. remote: Compressing objects: 100% (1/1), done. remote: Total 2 (delta 1), reused 2 (delta 1) Unpacking objects: 100% (2/2), done. From https://github.com/chaconinc/MainProject 9a377d1..eb974f8 master -> origin/master Fetching submodule DbConnector warning: Failed to merge submodule DbConnector (merge following commits not found) Auto-merging DbConnector CONFLICT (submodule): Merge conflict in DbConnector Automatic merge failed; fix conflicts and then commit the result.
So basically what has happened here is that Git has figured out that the two branches record points in the submodule’s history that are divergent and need to be merged. It explains it as ``merge following commits not found'', which is confusing but we’ll explain why that is in a bit.
To solve the problem, you need to figure out what state the submodule should be in.
Strangely, Git doesn’t really give you much information to help out here, not even the SHA-1s of the commits of both sides of the history.
Fortunately, it’s simple to figure out.
If you run git diff you can get the SHA-1s of the commits recorded in both branches you were trying to merge.
$ git diff diff --cc DbConnector index eb41d76,c771610..0000000 --- a/DbConnector +++ b/DbConnector
So, in this case, eb41d76 is the commit in our submodule that we had and c771610 is the commit that upstream had.
If we go into our submodule directory, it should already be on eb41d76 as the merge would not have touched it.
If for whatever reason it’s not, you can simply create and checkout a branch pointing to it.
What is important is the SHA-1 of the commit from the other side. This is what you’ll have to merge in and resolve. You can either just try the merge with the SHA-1 directly, or you can create a branch for it and then try to merge that in. We would suggest the latter, even if only to make a nicer merge commit message.
So, we will go into our submodule directory, create a branch based on that second SHA-1 from git diff and manually merge.
$ cd DbConnector $ git rev-parse HEAD eb41d764bccf88be77aced643c13a7fa86714135 $ git branch try-merge c771610 (DbConnector) $ git merge try-merge Auto-merging src/main.c CONFLICT (content): Merge conflict in src/main.c Recorded preimage for 'src/main.c' Automatic merge failed; fix conflicts and then commit the result.
We got an actual merge conflict here, so if we resolve that and commit it, then we can simply update the main project with the result.
$ vim src/main.c 1 $ git add src/main.c $ git commit -am 'merged our changes' Recorded resolution for 'src/main.c'. [master 9fd905e] merged our changes $ cd .. 2 $ git diff 3 diff --cc DbConnector index eb41d76,c771610..0000000 --- a/DbConnector +++ b/DbConnector @@@ -1,1 -1,1 +1,1 @@@ - Subproject commit eb41d764bccf88be77aced643c13a7fa86714135 -Subproject commit c77161012afbbe1f58b5053316ead08f4b7e6d1d ++Subproject commit 9fd905e5d7f45a0d4cbc43d1ee550f16a30e825a $ git add DbConnector 4 $ git commit -m "Merge Tom's Changes" 5 [master 10d2c60] Merge Tom's Changes
- 1 First we resolve the conflict
- 2 Then we go back to the main project directory
- 3 We can check the SHA-1s again
- 4 Resolve the conflicted submodule entry
- 5 Commit our merge
It can be a bit confusing, but it’s really not very hard.
Interestingly, there is another case that Git handles. If a merge commit exists in the submodule directory that contains both commits in its history, Git will suggest it to you as a possible solution. It sees that at some point in the submodule project, someone merged branches containing these two commits, so maybe you’ll want that one.
This is why the error message from before was ``merge following commits not found'', because it could not do this. It’s confusing because who would expect it to try to do this?
If it does find a single acceptable merge commit, you’ll see something like this:
$ git merge origin/master warning: Failed to merge submodule DbConnector (not fast-forward) Found a possible merge resolution for the submodule: 9fd905e5d7f45a0d4cbc43d1ee550f16a30e825a: > merged our changes If this is correct simply add it to the index for example by using: git update-index --cacheinfo 160000 9fd905e5d7f45a0d4cbc43d1ee550f16a30e825a "DbConnector" which will accept this suggestion. Auto-merging DbConnector CONFLICT (submodule): Merge conflict in DbConnector Automatic merge failed; fix conflicts and then commit the result.
The suggested command Git is providing will update the index as though you had run git add (which clears the conflict), then commit.
You probably shouldn’t do this though.
You can just as easily go into the submodule directory, see what the difference is, fast-forward to this commit, test it properly, and then commit it.
$ cd DbConnector/ $ git merge 9fd905e Updating eb41d76..9fd905e Fast-forward $ cd .. $ git add DbConnector $ git commit -am 'Fast forwarded to a common submodule child'
This accomplishes the same thing, but at least this way you can verify that it works and you have the code in your submodule directory when you’re done.
Submodule Tips
There are a few things you can do to make working with submodules a little easier.
Submodule Foreach
There is a foreach submodule command to run some arbitrary command in each submodule.
This can be really helpful if you have a number of submodules in the same project.
For example, let’s say we want to start a new feature or do a bugfix and we have work going on in several submodules. We can easily stash all the work in all our submodules.
$ git submodule foreach 'git stash' Entering 'CryptoLibrary' No local changes to save Entering 'DbConnector' Saved working directory and index state WIP on stable: 82d2ad3 Merge from origin/stable HEAD is now at 82d2ad3 Merge from origin/stable
Then we can create a new branch and switch to it in all our submodules.
$ git submodule foreach 'git checkout -b featureA' Entering 'CryptoLibrary' Switched to a new branch 'featureA' Entering 'DbConnector' Switched to a new branch 'featureA'
You get the idea. One really useful thing you can do is produce a nice unified diff of what is changed in your main project and all your subprojects as well.
$ git diff; git submodule foreach 'git diff'
Submodule DbConnector contains modified content
diff --git a/src/main.c b/src/main.c
index 210f1ae..1f0acdc 100644
--- a/src/main.c
+++ b/src/main.c
@@ -245,6 +245,8 @@ static int handle_alias(int *argcp, const char ***argv)
commit_pager_choice();
+ url = url_decode(url_orig);
+
/* build alias_argv */
alias_argv = xmalloc(sizeof(*alias_argv) * (argc + 1));
alias_argv[0] = alias_string + 1;
Entering 'DbConnector'
diff --git a/src/db.c b/src/db.c
index 1aaefb6..5297645 100644
--- a/src/db.c
+++ b/src/db.c
@@ -93,6 +93,11 @@ char *url_decode_mem(const char *url, int len)
return url_decode_internal(&url, len, NULL, &out, 0);
}
+char *url_decode(const char *url)
+{
+ return url_decode_mem(url, strlen(url));
+}
+
char *url_decode_parameter_name(const char **query)
{
struct strbuf out = STRBUF_INIT;
Here we can see that we’re defining a function in a submodule and calling it in the main project. This is obviously a simplified example, but hopefully it gives you an idea of how this may be useful.
Useful Aliases
You may want to set up some aliases for some of these commands as they can be quite long and you can’t set configuration options for most of them to make them defaults. We covered setting up Git aliases in Git Aliases, but here is an example of what you may want to set up if you plan on working with submodules in Git a lot.
$ git config alias.sdiff '!'"git diff && git submodule foreach 'git diff'" $ git config alias.spush 'push --recurse-submodules=on-demand' $ git config alias.supdate 'submodule update --remote --merge'
This way you can simply run git supdate when you want to update your submodules, or git spush to push with submodule dependency checking.
Issues with Submodules
Using submodules isn’t without hiccups, however.
Switching branches
For instance, switching branches with submodules in them can also be tricky with Git versions older than Git 2.13. If you create a new branch, add a submodule there, and then switch back to a branch without that submodule, you still have the submodule directory as an untracked directory:
$ git --version git version 2.12.2 $ git checkout -b add-crypto Switched to a new branch 'add-crypto' $ git submodule add https://github.com/chaconinc/CryptoLibrary Cloning into 'CryptoLibrary'... ... $ git commit -am 'adding crypto library' [add-crypto 4445836] adding crypto library 2 files changed, 4 insertions(+) create mode 160000 CryptoLibrary $ git checkout master warning: unable to rmdir CryptoLibrary: Directory not empty Switched to branch 'master' Your branch is up-to-date with 'origin/master'. $ git status On branch master Your branch is up-to-date with 'origin/master'. Untracked files: (use "git add <file>..." to include in what will be committed) CryptoLibrary/ nothing added to commit but untracked files present (use "git add" to track)
Removing the directory isn’t difficult, but it can be a bit confusing to have that in there.
If you do remove it and then switch back to the branch that has that submodule, you will need to run submodule update --init to repopulate it.
$ git clean -ffdx Removing CryptoLibrary/ $ git checkout add-crypto Switched to branch 'add-crypto' $ ls CryptoLibrary/ $ git submodule update --init Submodule path 'CryptoLibrary': checked out 'b8dda6aa182ea4464f3f3264b11e0268545172af' $ ls CryptoLibrary/ Makefile includes scripts src
Again, not really very difficult, but it can be a little confusing.
Newer Git versions (Git >= 2.13) simplify all this by adding the --recurse-submodules flag to the git checkout command, which takes care of placing the submodules in the right state for the branch we are switching to.
$ git --version git version 2.13.3 $ git checkout -b add-crypto Switched to a new branch 'add-crypto' $ git submodule add https://github.com/chaconinc/CryptoLibrary Cloning into 'CryptoLibrary'... ... $ git commit -am 'adding crypto library' [add-crypto 4445836] adding crypto library 2 files changed, 4 insertions(+) create mode 160000 CryptoLibrary $ git checkout --recurse-submodules master Switched to branch 'master' Your branch is up-to-date with 'origin/master'. $ git status On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working tree clean
Using the --recurse-submodules flag of git checkout can also be useful when you work on several branches in the superproject, each having your submodule pointing at different commits.
Indeed, if you switch between branches that record the submodule at different commits, upon executing git status the submodule will appear as modified'', and indicate new commits''. That is because the submodule state is by default not carried over when switching branches.
This can be really confusing, so it’s a good idea to always git checkout --recurse-submodules when your project has submodules.
(For older Git versions that do not have the --recurse-submodules flag, after the checkout you can use git submodule update --init --recursive to put the submodules in the right state.)
Luckily, you can tell Git (>=2.14) to always use the --recurse-submodules flag by setting the configuration option submodule.recurse: git config submodule.recurse true.
As noted above, this will also make Git recurse into submodules for every command that has a --recurse-submodules option (except git clone).
Switching from subdirectories to submodules
The other main caveat that many people run into involves switching from subdirectories to submodules.
If you’ve been tracking files in your project and you want to move them out into a submodule, you must be careful or Git will get angry at you.
Assume that you have files in a subdirectory of your project, and you want to switch it to a submodule.
If you delete the subdirectory and then run submodule add, Git yells at you:
$ rm -Rf CryptoLibrary/ $ git submodule add https://github.com/chaconinc/CryptoLibrary 'CryptoLibrary' already exists in the index
You have to unstage the CryptoLibrary directory first.
Then you can add the submodule:
$ git rm -r CryptoLibrary $ git submodule add https://github.com/chaconinc/CryptoLibrary Cloning into 'CryptoLibrary'... remote: Counting objects: 11, done. remote: Compressing objects: 100% (10/10), done. remote: Total 11 (delta 0), reused 11 (delta 0) Unpacking objects: 100% (11/11), done. Checking connectivity... done.
Now suppose you did that in a branch. If you try to switch back to a branch where those files are still in the actual tree rather than a submodule – you get this error:
$ git checkout master error: The following untracked working tree files would be overwritten by checkout: CryptoLibrary/Makefile CryptoLibrary/includes/crypto.h ... Please move or remove them before you can switch branches. Aborting
You can force it to switch with checkout -f, but be careful that you don’t have unsaved changes in there as they could be overwritten with that command.
$ git checkout -f master warning: unable to rmdir CryptoLibrary: Directory not empty Switched to branch 'master'
Then, when you switch back, you get an empty CryptoLibrary directory for some reason and git submodule update may not fix it either.
You may need to go into your submodule directory and run a git checkout . to get all your files back.
You could run this in a submodule foreach script to run it for multiple submodules.
It’s important to note that submodules these days keep all their Git data in the top project’s .git directory, so unlike much older versions of Git, destroying a submodule directory won’t lose any commits or branches that you had.
With these tools, submodules can be a fairly simple and effective method for developing on several related but still separate projects simultaneously.
Bundling
Though we’ve covered the common ways to transfer Git data over a network (HTTP, SSH, etc), there is actually one more way to do so that is not commonly used but can actually be quite useful.
Git is capable of `bundling'' its data into a single file.
This can be useful in various scenarios.
Maybe your network is down and you want to send changes to your co-workers.
Perhaps you’re working somewhere offsite and don’t have access to the local network for security reasons.
Maybe your wireless/ethernet card just broke.
Maybe you don’t have access to a shared server for the moment, you want to email someone updates and you don’t want to transfer 40 commits via `format-patch.
This is where the git bundle command can be helpful.
The bundle command will package up everything that would normally be pushed over the wire with a git push command into a binary file that you can email to someone or put on a flash drive, then unbundle into another repository.
Let’s see a simple example. Let’s say you have a repository with two commits:
$ git log
commit 9a466c572fe88b195efd356c3f2bbeccdb504102
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Mar 10 07:34:10 2010 -0800
second commit
commit b1ec3248f39900d2a406049d762aa68e9641be25
Author: Scott Chacon <schacon@gmail.com>
Date: Wed Mar 10 07:34:01 2010 -0800
first commit
If you want to send that repository to someone and you don’t have access to a repository to push to, or simply don’t want to set one up, you can bundle it with git bundle create.
$ git bundle create repo.bundle HEAD master Counting objects: 6, done. Delta compression using up to 2 threads. Compressing objects: 100% (2/2), done. Writing objects: 100% (6/6), 441 bytes, done. Total 6 (delta 0), reused 0 (delta 0)
Now you have a file named repo.bundle that has all the data needed to re-create the repository’s master branch.
With the bundle command you need to list out every reference or specific range of commits that you want to be included.
If you intend for this to be cloned somewhere else, you should add HEAD as a reference as well as we’ve done here.
You can email this repo.bundle file to someone else, or put it on a USB drive and walk it over.
On the other side, say you are sent this repo.bundle file and want to work on the project.
You can clone from the binary file into a directory, much like you would from a URL.
$ git clone repo.bundle repo Cloning into 'repo'... ... $ cd repo $ git log --oneline 9a466c5 second commit b1ec324 first commit
If you don’t include HEAD in the references, you have to also specify -b master or whatever branch is included because otherwise it won’t know what branch to check out.
Now let’s say you do three commits on it and want to send the new commits back via a bundle on a USB stick or email.
$ git log --oneline 71b84da last commit - second repo c99cf5b fourth commit - second repo 7011d3d third commit - second repo 9a466c5 second commit b1ec324 first commit
First we need to determine the range of commits we want to include in the bundle. Unlike the network protocols which figure out the minimum set of data to transfer over the network for us, we’ll have to figure this out manually. Now, you could just do the same thing and bundle the entire repository, which will work, but it’s better to just bundle up the difference - just the three commits we just made locally.
In order to do that, you’ll have to calculate the difference.
As we described in Commit Ranges, you can specify a range of commits in a number of ways.
To get the three commits that we have in our master branch that weren’t in the branch we originally cloned, we can use something like origin/master..master or master ^origin/master.
You can test that with the log command.
$ git log --oneline master ^origin/master 71b84da last commit - second repo c99cf5b fourth commit - second repo 7011d3d third commit - second repo
So now that we have the list of commits we want to include in the bundle, let’s bundle them up.
We do that with the git bundle create command, giving it a filename we want our bundle to be and the range of commits we want to go into it.
$ git bundle create commits.bundle master ^9a466c5 Counting objects: 11, done. Delta compression using up to 2 threads. Compressing objects: 100% (3/3), done. Writing objects: 100% (9/9), 775 bytes, done. Total 9 (delta 0), reused 0 (delta 0)
Now we have a commits.bundle file in our directory.
If we take that and send it to our partner, she can then import it into the original repository, even if more work has been done there in the meantime.
When she gets the bundle, she can inspect it to see what it contains before she imports it into her repository.
The first command is the bundle verify command that will make sure the file is actually a valid Git bundle and that you have all the necessary ancestors to reconstitute it properly.
$ git bundle verify ../commits.bundle The bundle contains 1 ref 71b84daaf49abed142a373b6e5c59a22dc6560dc refs/heads/master The bundle requires these 1 ref 9a466c572fe88b195efd356c3f2bbeccdb504102 second commit ../commits.bundle is okay
If the bundler had created a bundle of just the last two commits they had done, rather than all three, the original repository would not be able to import it, since it is missing requisite history.
The verify command would have looked like this instead:
$ git bundle verify ../commits-bad.bundle error: Repository lacks these prerequisite commits: error: 7011d3d8fc200abe0ad561c011c3852a4b7bbe95 third commit - second repo
However, our first bundle is valid, so we can fetch in commits from it. If you want to see what branches are in the bundle that can be imported, there is also a command to just list the heads:
$ git bundle list-heads ../commits.bundle 71b84daaf49abed142a373b6e5c59a22dc6560dc refs/heads/master
The verify sub-command will tell you the heads as well.
The point is to see what can be pulled in, so you can use the fetch or pull commands to import commits from this bundle.
Here we’ll fetch the master branch of the bundle to a branch named other-master in our repository:
$ git fetch ../commits.bundle master:other-master From ../commits.bundle * [new branch] master -> other-master
Now we can see that we have the imported commits on the other-master branch as well as any commits we’ve done in the meantime in our own master branch.
$ git log --oneline --decorate --graph --all * 8255d41 (HEAD, master) third commit - first repo | * 71b84da (other-master) last commit - second repo | * c99cf5b fourth commit - second repo | * 7011d3d third commit - second repo |/ * 9a466c5 second commit * b1ec324 first commit
So, git bundle can be really useful for sharing or doing network-type operations when you don’t have the proper network or shared repository to do so.
Replace
As we’ve emphasized before, the objects in Git’s object database are unchangeable, but Git does provide an interesting way to pretend to replace objects in its database with other objects.
The replace command lets you specify an object in Git and say "every time you refer to this object, pretend it’s a different object".
This is most commonly useful for replacing one commit in your history with another one without having to rebuild the entire history with, say, git filter-branch.
For example, let’s say you have a huge code history and want to split your repository into one short history for new developers and one much longer and larger history for people interested in data mining. You can graft one history onto the other by "replacing" the earliest commit in the new line with the latest commit on the older one. This is nice because it means that you don’t actually have to rewrite every commit in the new history, as you would normally have to do to join them together (because the parentage affects the SHA-1s).
Let’s try this out.
Let’s take an existing repository, split it into two repositories, one recent and one historical, and then we’ll see how we can recombine them without modifying the recent repositories SHA-1 values via replace.
We’ll use a simple repository with five simple commits:
$ git log --oneline ef989d8 fifth commit c6e1e95 fourth commit 9c68fdc third commit 945704c second commit c1822cf first commit
We want to break this up into two lines of history. One line goes from commit one to commit four - that will be the historical one. The second line will just be commits four and five - that will be the recent history.
Well, creating the historical history is easy, we can just put a branch in the history and then push that branch to the master branch of a new remote repository.
$ git branch history c6e1e95 $ git log --oneline --decorate ef989d8 (HEAD, master) fifth commit c6e1e95 (history) fourth commit 9c68fdc third commit 945704c second commit c1822cf first commit
Now we can push the new history branch to the master branch of our new repository:
$ git remote add project-history https://github.com/schacon/project-history $ git push project-history history:master Counting objects: 12, done. Delta compression using up to 2 threads. Compressing objects: 100% (4/4), done. Writing objects: 100% (12/12), 907 bytes, done. Total 12 (delta 0), reused 0 (delta 0) Unpacking objects: 100% (12/12), done. To git@github.com:schacon/project-history.git * [new branch] history -> master
OK, so our history is published. Now the harder part is truncating our recent history down so it’s smaller. We need an overlap so we can replace a commit in one with an equivalent commit in the other, so we’re going to truncate this to just commits four and five (so commit four overlaps).
$ git log --oneline --decorate ef989d8 (HEAD, master) fifth commit c6e1e95 (history) fourth commit 9c68fdc third commit 945704c second commit c1822cf first commit
It’s useful in this case to create a base commit that has instructions on how to expand the history, so other developers know what to do if they hit the first commit in the truncated history and need more. So, what we’re going to do is create an initial commit object as our base point with instructions, then rebase the remaining commits (four and five) on top of it.
To do that, we need to choose a point to split at, which for us is the third commit, which is 9c68fdc in SHA-speak.
So, our base commit will be based off of that tree.
We can create our base commit using the commit-tree command, which just takes a tree and will give us a brand new, parentless commit object SHA-1 back.
$ echo 'get history from blah blah blah' | git commit-tree 9c68fdc^{tree}
622e88e9cbfbacfb75b5279245b9fb38dfea10cf
The commit-tree command is one of a set of commands that are commonly referred to as 'plumbing' commands.
These are commands that are not generally meant to be used directly, but instead are used by other Git commands to do smaller jobs.
On occasions when we’re doing weirder things like this, they allow us to do really low-level things but are not meant for daily use.
You can read more about plumbing commands in Plumbing and Porcelain
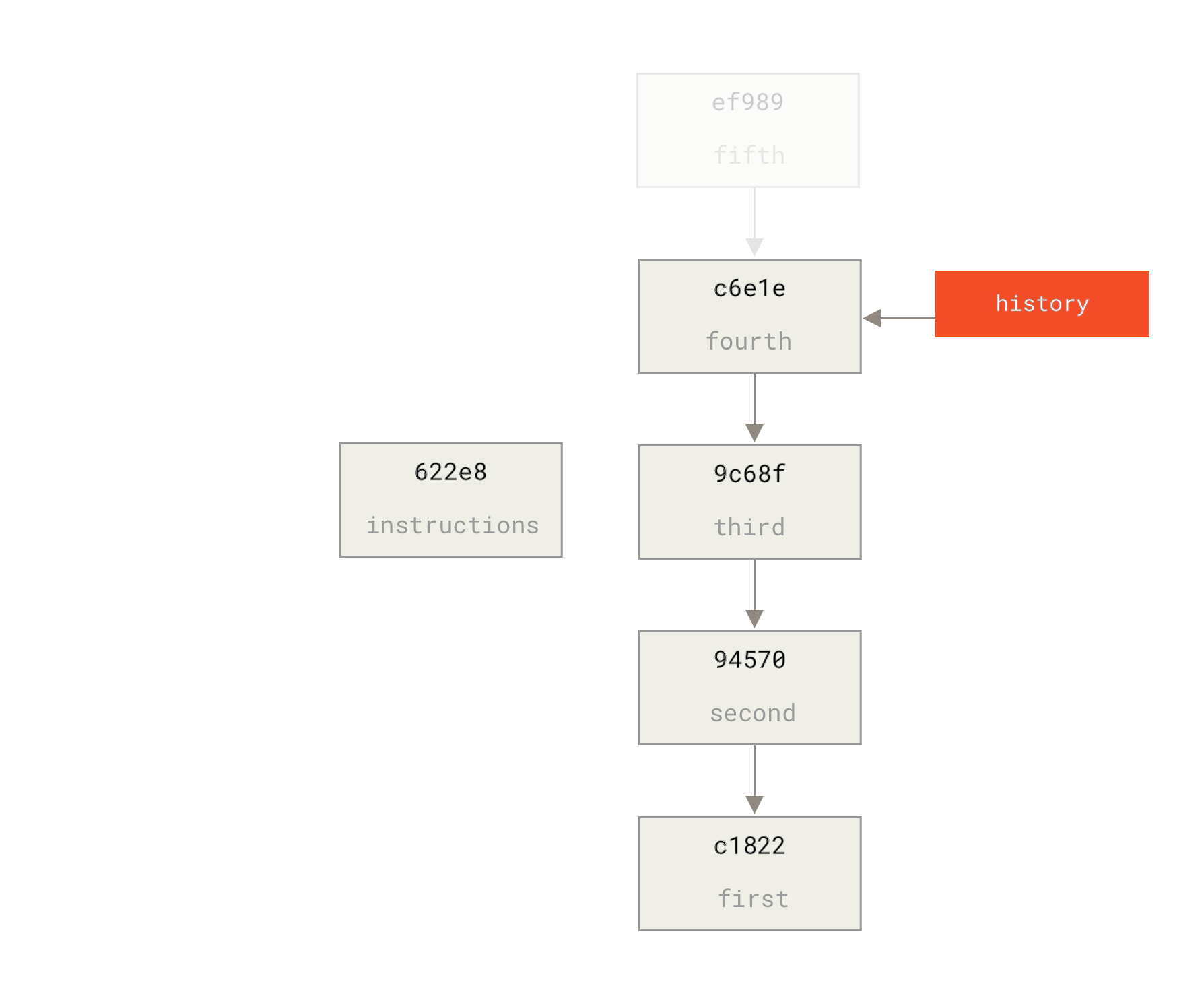
OK, so now that we have a base commit, we can rebase the rest of our history on top of that with git rebase --onto.
The --onto argument will be the SHA-1 we just got back from commit-tree and the rebase point will be the third commit (the parent of the first commit we want to keep, 9c68fdc):
$ git rebase --onto 622e88 9c68fdc First, rewinding head to replay your work on top of it... Applying: fourth commit Applying: fifth commit
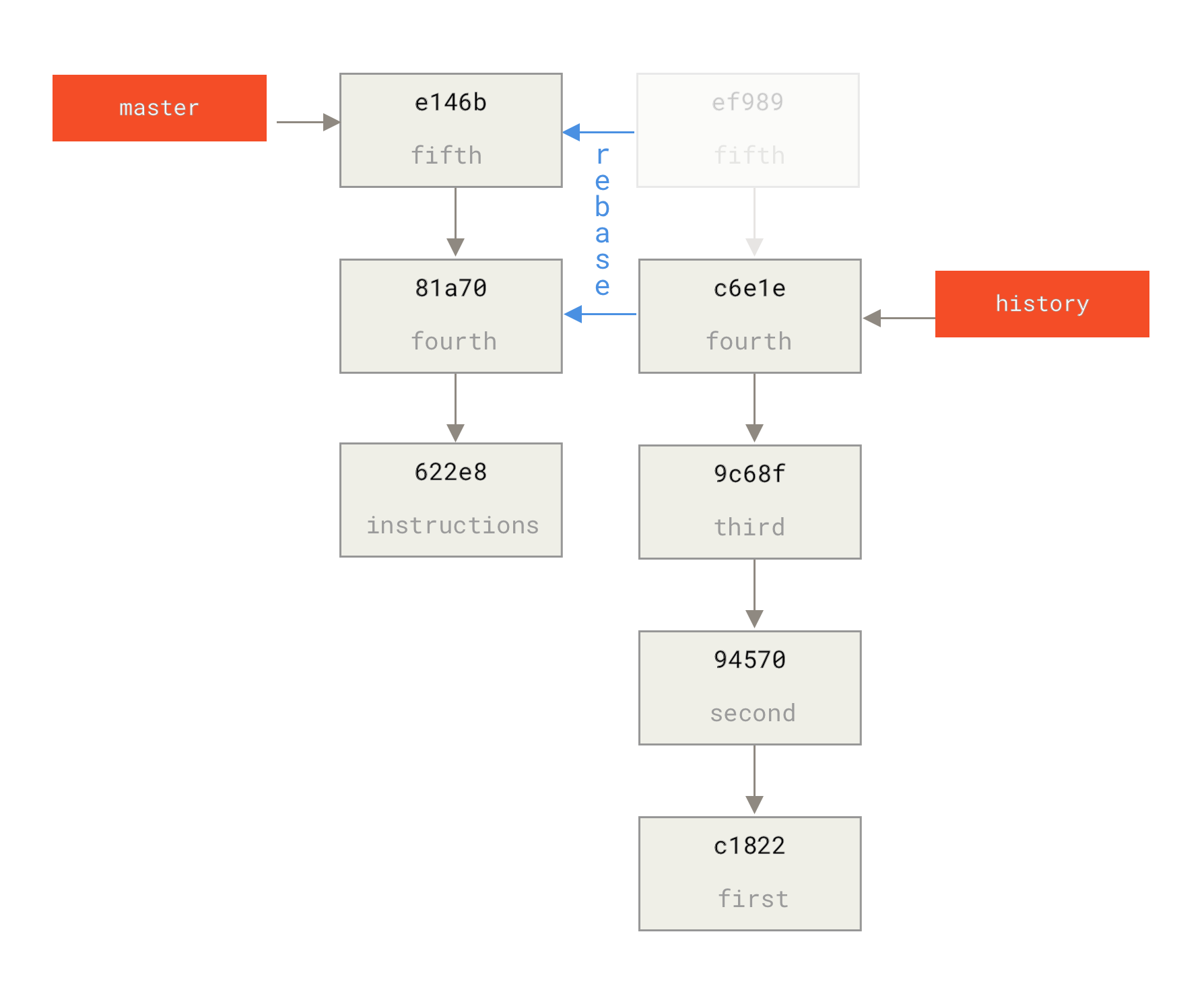
OK, so now we’ve re-written our recent history on top of a throw away base commit that now has instructions in it on how to reconstitute the entire history if we wanted to. We can push that new history to a new project and now when people clone that repository, they will only see the most recent two commits and then a base commit with instructions.
Let’s now switch roles to someone cloning the project for the first time who wants the entire history. To get the history data after cloning this truncated repository, one would have to add a second remote for the historical repository and fetch:
$ git clone https://github.com/schacon/project $ cd project $ git log --oneline master e146b5f fifth commit 81a708d fourth commit 622e88e get history from blah blah blah $ git remote add project-history https://github.com/schacon/project-history $ git fetch project-history From https://github.com/schacon/project-history * [new branch] master -> project-history/master
Now the collaborator would have their recent commits in the master branch and the historical commits in the project-history/master branch.
$ git log --oneline master e146b5f fifth commit 81a708d fourth commit 622e88e get history from blah blah blah $ git log --oneline project-history/master c6e1e95 fourth commit 9c68fdc third commit 945704c second commit c1822cf first commit
To combine them, you can simply call git replace with the commit you want to replace and then the commit you want to replace it with.
So we want to replace the "fourth" commit in the master branch with the "fourth" commit in the project-history/master branch:
$ git replace 81a708d c6e1e95
Now, if you look at the history of the master branch, it appears to look like this:
$ git log --oneline master e146b5f fifth commit 81a708d fourth commit 9c68fdc third commit 945704c second commit c1822cf first commit
Cool, right? Without having to change all the SHA-1s upstream, we were able to replace one commit in our history with an entirely different commit and all the normal tools (bisect, blame, etc) will work how we would expect them to.
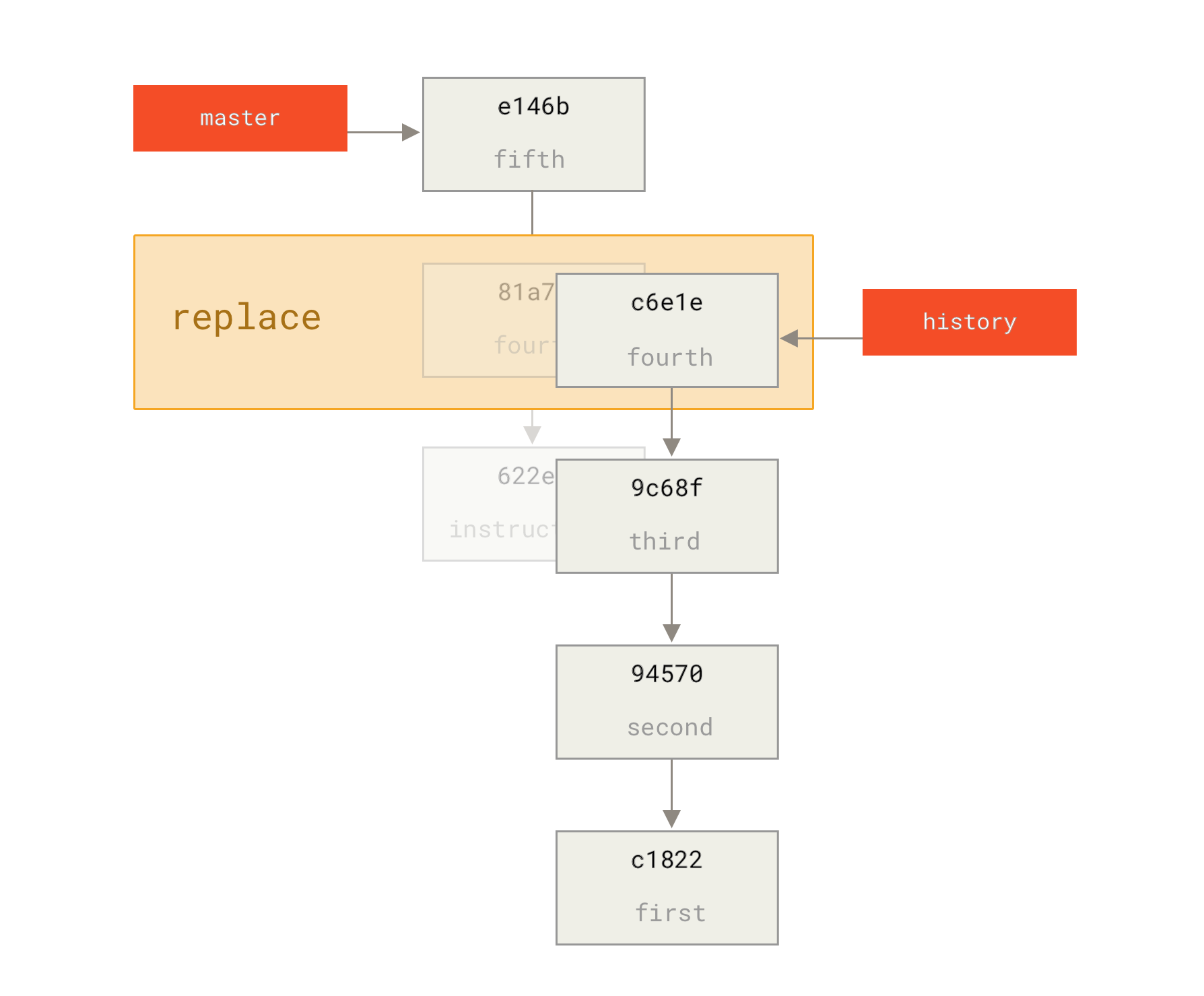
Interestingly, it still shows 81a708d as the SHA-1, even though it’s actually using the c6e1e95 commit data that we replaced it with.
Even if you run a command like cat-file, it will show you the replaced data:
$ git cat-file -p 81a708d tree 7bc544cf438903b65ca9104a1e30345eee6c083d parent 9c68fdceee073230f19ebb8b5e7fc71b479c0252 author Scott Chacon <schacon@gmail.com> 1268712581 -0700 committer Scott Chacon <schacon@gmail.com> 1268712581 -0700 fourth commit
Remember that the actual parent of 81a708d was our placeholder commit (622e88e), not 9c68fdce as it states here.
Another interesting thing is that this data is kept in our references:
$ git for-each-ref e146b5f14e79d4935160c0e83fb9ebe526b8da0d commit refs/heads/master c6e1e95051d41771a649f3145423f8809d1a74d4 commit refs/remotes/history/master e146b5f14e79d4935160c0e83fb9ebe526b8da0d commit refs/remotes/origin/HEAD e146b5f14e79d4935160c0e83fb9ebe526b8da0d commit refs/remotes/origin/master c6e1e95051d41771a649f3145423f8809d1a74d4 commit refs/replace/81a708dd0e167a3f691541c7a6463343bc457040
This means that it’s easy to share our replacement with others, because we can push this to our server and other people can easily download it. This is not that helpful in the history grafting scenario we’ve gone over here (since everyone would be downloading both histories anyhow, so why separate them?) but it can be useful in other circumstances.
Credential Storage
If you use the SSH transport for connecting to remotes, it’s possible for you to have a key without a passphrase, which allows you to securely transfer data without typing in your username and password. However, this isn’t possible with the HTTP protocols – every connection needs a username and password. This gets even harder for systems with two-factor authentication, where the token you use for a password is randomly generated and unpronounceable.
Fortunately, Git has a credentials system that can help with this. Git has a few options provided in the box:
-
The default is not to cache at all. Every connection will prompt you for your username and password.
-
The ``cache'' mode keeps credentials in memory for a certain period of time. None of the passwords are ever stored on disk, and they are purged from the cache after 15 minutes.
-
The ``store'' mode saves the credentials to a plain-text file on disk, and they never expire. This means that until you change your password for the Git host, you won’t ever have to type in your credentials again. The downside of this approach is that your passwords are stored in cleartext in a plain file in your home directory.
-
If you’re using a Mac, Git comes with an ``osxkeychain'' mode, which caches credentials in the secure keychain that’s attached to your system account. This method stores the credentials on disk, and they never expire, but they’re encrypted with the same system that stores HTTPS certificates and Safari auto-fills.
-
If you’re using Windows, you can install a helper called
Git Credential Manager for Windows.'' This is similar to theosxkeychain'' helper described above, but uses the Windows Credential Store to control sensitive information. It can be found at https://github.com/Microsoft/Git-Credential-Manager-for-Windows.
You can choose one of these methods by setting a Git configuration value:
$ git config --global credential.helper cache
Some of these helpers have options.
The store'' helper can take a cache'' helper accepts the --file <path> argument, which customizes where the plain-text file is saved (the default is ~/.git-credentials).
The --timeout <seconds> option, which changes the amount of time its daemon is kept running (the default is 900'', or 15 minutes).
Here’s an example of how you’d configure the store'' helper with a custom file name:
$ git config --global credential.helper 'store --file ~/.my-credentials'
Git even allows you to configure several helpers.
When looking for credentials for a particular host, Git will query them in order, and stop after the first answer is provided.
When saving credentials, Git will send the username and password to all of the helpers in the list, and they can choose what to do with them.
Here’s what a .gitconfig would look like if you had a credentials file on a thumb drive, but wanted to use the in-memory cache to save some typing if the drive isn’t plugged in:
[credential]
helper = store --file /mnt/thumbdrive/.git-credentials
helper = cache --timeout 30000
Under the Hood
How does this all work?
Git’s root command for the credential-helper system is git credential, which takes a command as an argument, and then more input through stdin.
This might be easier to understand with an example.
Let’s say that a credential helper has been configured, and the helper has stored credentials for mygithost.
Here’s a session that uses the ``fill'' command, which is invoked when Git is trying to find credentials for a host:
$ git credential fill 1 protocol=https 2 host=mygithost 3 protocol=https 4 host=mygithost username=bob password=s3cre7 $ git credential fill 5 protocol=https host=unknownhost Username for 'https://unknownhost': bob Password for 'https://bob@unknownhost': protocol=https host=unknownhost username=bob password=s3cre7
- 1 This is the command line that initiates the interaction.
- 2 Git-credential is then waiting for input on stdin. We provide it with the things we know: the protocol and hostname.
- 3 A blank line indicates that the input is complete, and the credential system should answer with what it knows.
- 4 Git-credential then takes over, and writes to stdout with the bits of information it found.
- 5 If credentials are not found, Git asks the user for the username and password, and provides them back to the invoking stdout (here they’re attached to the same console).
The credential system is actually invoking a program that’s separate from Git itself; which one and how depends on the credential.helper configuration value.
There are several forms it can take:
| Configuration Value | Behavior |
|---|---|
foo |
Runs git-credential-foo |
foo -a --opt=bcd |
Runs git-credential-foo -a --opt=bcd |
/absolute/path/foo -xyz |
Runs /absolute/path/foo -xyz |
!f() { echo "password=s3cre7"; }; f |
Code after ! evaluated in shell |
So the helpers described above are actually named git-credential-cache, git-credential-store, and so on, and we can configure them to take command-line arguments.
The general form for this is ``git-credential-foo [args] <action>.''
The stdin/stdout protocol is the same as git-credential, but they use a slightly different set of actions:
-
getis a request for a username/password pair. -
storeis a request to save a set of credentials in this helper’s memory. -
erasepurge the credentials for the given properties from this helper’s memory.
For the store and erase actions, no response is required (Git ignores it anyway).
For the get action, however, Git is very interested in what the helper has to say.
If the helper doesn’t know anything useful, it can simply exit with no output, but if it does know, it should augment the provided information with the information it has stored.
The output is treated like a series of assignment statements; anything provided will replace what Git already knows.
Here’s the same example from above, but skipping git-credential and going straight for git-credential-store:
$ git credential-store --file ~/git.store store 1 protocol=https host=mygithost username=bob password=s3cre7 $ git credential-store --file ~/git.store get 2 protocol=https host=mygithost username=bob 3 password=s3cre7
-
1 Here we tell
git-credential-storeto save some credentials: the usernamebob'' and the passwords3cre7'' are to be used whenhttps://mygithostis accessed. -
2 Now we’ll retrieve those credentials.
We provide the parts of the connection we already know (
https://mygithost), and an empty line. -
3
git-credential-storereplies with the username and password we stored above.
Here’s what the ~/git.store file looks like:
https://bob:s3cre7@mygithost
It’s just a series of lines, each of which contains a credential-decorated URL.
The osxkeychain and wincred helpers use the native format of their backing stores, while cache uses its own in-memory format (which no other process can read).
A Custom Credential Cache
Given that git-credential-store and friends are separate programs from Git, it’s not much of a leap to realize that any program can be a Git credential helper.
The helpers provided by Git cover many common use cases, but not all.
For example, let’s say your team has some credentials that are shared with the entire team, perhaps for deployment.
These are stored in a shared directory, but you don’t want to copy them to your own credential store, because they change often.
None of the existing helpers cover this case; let’s see what it would take to write our own.
There are several key features this program needs to have:
-
The only action we need to pay attention to is
get;storeanderaseare write operations, so we’ll just exit cleanly when they’re received. -
The file format of the shared-credential file is the same as that used by
git-credential-store. -
The location of that file is fairly standard, but we should allow the user to pass a custom path just in case.
Once again, we’ll write this extension in Ruby, but any language will work so long as Git can execute the finished product. Here’s the full source code of our new credential helper:
#!/usr/bin/env ruby require 'optparse' path = File.expand_path '~/.git-credentials' 1 OptionParser.new do |opts| opts.banner = 'USAGE: git-credential-read-only [options] <action>' opts.on('-f', '--file PATH', 'Specify path for backing store') do |argpath| path = File.expand_path argpath end end.parse! exit(0) unless ARGV[0].downcase == 'get' 2 exit(0) unless File.exists? path known = {} 3 while line = STDIN.gets break if line.strip == '' k,v = line.strip.split '=', 2 known[k] = v end File.readlines(path).each do |fileline| 4 prot,user,pass,host = fileline.scan(/^(.*?):\/\/(.*?):(.*?)@(.*)$/).first if prot == known['protocol'] and host == known['host'] and user == known['username'] then puts "protocol=#{prot}" puts "host=#{host}" puts "username=#{user}" puts "password=#{pass}" exit(0) end end
-
1 Here we parse the command-line options, allowing the user to specify the input file.
The default is
~/.git-credentials. -
2 This program only responds if the action is
getand the backing-store file exists. -
3 This loop reads from stdin until the first blank line is reached.
The inputs are stored in the
knownhash for later reference. -
4 This loop reads the contents of the storage file, looking for matches.
If the protocol and host from
knownmatch this line, the program prints the results to stdout and exits.
We’ll save our helper as git-credential-read-only, put it somewhere in our PATH and mark it executable.
Here’s what an interactive session looks like:
$ git credential-read-only --file=/mnt/shared/creds get protocol=https host=mygithost protocol=https host=mygithost username=bob password=s3cre7
Since its name starts with ``git-'', we can use the simple syntax for the configuration value:
$ git config --global credential.helper 'read-only --file /mnt/shared/creds'
As you can see, extending this system is pretty straightforward, and can solve some common problems for you and your team.
Summary
You’ve seen a number of advanced tools that allow you to manipulate your commits and staging area more precisely. When you notice issues, you should be able to easily figure out what commit introduced them, when, and by whom. If you want to use subprojects in your project, you’ve learned how to accommodate those needs. At this point, you should be able to do most of the things in Git that you’ll need on the command line day to day and feel comfortable doing so.