Git Internals
You may have skipped to this chapter from a much earlier chapter, or you may have gotten here after sequentially reading the entire book up to this point — in either case, this is where we’ll go over the inner workings and implementation of Git. We found that understanding this information was fundamentally important to appreciating how useful and powerful Git is, but others have argued to us that it can be confusing and unnecessarily complex for beginners. Thus, we’ve made this discussion the last chapter in the book so you could read it early or later in your learning process. We leave it up to you to decide.
Now that you’re here, let’s get started. First, if it isn’t yet clear, Git is fundamentally a content-addressable filesystem with a VCS user interface written on top of it. You’ll learn more about what this means in a bit.
In the early days of Git (mostly pre 1.5), the user interface was much more complex because it emphasized this filesystem rather than a polished VCS. In the last few years, the UI has been refined until it’s as clean and easy to use as any system out there; however, the stereotype lingers about the early Git UI that was complex and difficult to learn.
The content-addressable filesystem layer is amazingly cool, so we’ll cover that first in this chapter; then, you’ll learn about the transport mechanisms and the repository maintenance tasks that you may eventually have to deal with.
Plumbing and Porcelain
This book covers primarily how to use Git with 30 or so subcommands such as checkout, branch, remote, and so on.
But because Git was initially a toolkit for a version control system rather than a full user-friendly VCS, it has a number of subcommands that do low-level work and were designed to be chained together UNIX-style or called from scripts.
These commands are generally referred to as Git’s plumbing'' commands, while the more user-friendly commands are called porcelain'' commands.
As you will have noticed by now, this book’s first nine chapters deal almost exclusively with porcelain commands. But in this chapter, you’ll be dealing mostly with the lower-level plumbing commands, because they give you access to the inner workings of Git, and help demonstrate how and why Git does what it does. Many of these commands aren’t meant to be used manually on the command line, but rather to be used as building blocks for new tools and custom scripts.
When you run git init in a new or existing directory, Git creates the .git directory, which is where almost everything that Git stores and manipulates is located.
If you want to back up or clone your repository, copying this single directory elsewhere gives you nearly everything you need.
This entire chapter basically deals with what you can see in this directory.
Here’s what a newly-initialized .git directory typically looks like:
$ ls -F1 config description HEAD hooks/ info/ objects/ refs/
Depending on your version of Git, you may see some additional content there, but this is a fresh git init repository — it’s what you see by default.
The description file is used only by the GitWeb program, so don’t worry about it.
The config file contains your project-specific configuration options, and the info directory keeps a global exclude file for ignored patterns that you don’t want to track in a .gitignore file.
The hooks directory contains your client- or server-side hook scripts, which are discussed in detail in Git Hooks.
This leaves four important entries: the HEAD and (yet to be created) index files, and the objects and refs directories.
These are the core parts of Git.
The objects directory stores all the content for your database, the refs directory stores pointers into commit objects in that data (branches, tags, remotes and more), the HEAD file points to the branch you currently have checked out, and the index file is where Git stores your staging area information.
You’ll now look at each of these sections in detail to see how Git operates.
Git Objects
Git is a content-addressable filesystem. Great. What does that mean? It means that at the core of Git is a simple key-value data store. What this means is that you can insert any kind of content into a Git repository, for which Git will hand you back a unique key you can use later to retrieve that content.
As a demonstration, let’s look at the plumbing command git hash-object, which takes some data, stores it in your .git/objects directory (the object database), and gives you back the unique key that now refers to that data object.
First, you initialize a new Git repository and verify that there is (predictably) nothing in the objects directory:
$ git init test Initialized empty Git repository in /tmp/test/.git/ $ cd test $ find .git/objects .git/objects .git/objects/info .git/objects/pack $ find .git/objects -type f
Git has initialized the objects directory and created pack and info subdirectories in it, but there are no regular files.
Now, let’s use git hash-object to create a new data object and manually store it in your new Git database:
$ echo 'test content' | git hash-object -w --stdin d670460b4b4aece5915caf5c68d12f560a9fe3e4
In its simplest form, git hash-object would take the content you handed to it and merely return the unique key that would be used to store it in your Git database.
The -w option then tells the command to not simply return the key, but to write that object to the database.
Finally, the --stdin option tells git hash-object to get the content to be processed from stdin; otherwise, the command would expect a filename argument at the end of the command containing the content to be used.
The output from the above command is a 40-character checksum hash. This is the SHA-1 hash — a checksum of the content you’re storing plus a header, which you’ll learn about in a bit. Now you can see how Git has stored your data:
$ find .git/objects -type f .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
If you again examine your objects directory, you can see that it now contains a file for that new content.
This is how Git stores the content initially — as a single file per piece of content, named with the SHA-1 checksum of the content and its header.
The subdirectory is named with the first 2 characters of the SHA-1, and the filename is the remaining 38 characters.
Once you have content in your object database, you can examine that content with the git cat-file command.
This command is sort of a Swiss army knife for inspecting Git objects.
Passing -p to cat-file instructs the command to first figure out the type of content, then display it appropriately:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4 test content
Now, you can add content to Git and pull it back out again. You can also do this with content in files. For example, you can do some simple version control on a file. First, create a new file and save its contents in your database:
$ echo 'version 1' > test.txt $ git hash-object -w test.txt 83baae61804e65cc73a7201a7252750c76066a30
Then, write some new content to the file, and save it again:
$ echo 'version 2' > test.txt $ git hash-object -w test.txt 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
Your object database now contains both versions of this new file (as well as the first content you stored there):
$ find .git/objects -type f .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
At this point, you can delete your local copy of that test.txt file, then use Git to retrieve, from the object database, either the first version you saved:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt $ cat test.txt version 1
or the second version:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt $ cat test.txt version 2
But remembering the SHA-1 key for each version of your file isn’t practical; plus, you aren’t storing the filename in your system — just the content.
This object type is called a blob.
You can have Git tell you the object type of any object in Git, given its SHA-1 key, with git cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob
Tree Objects
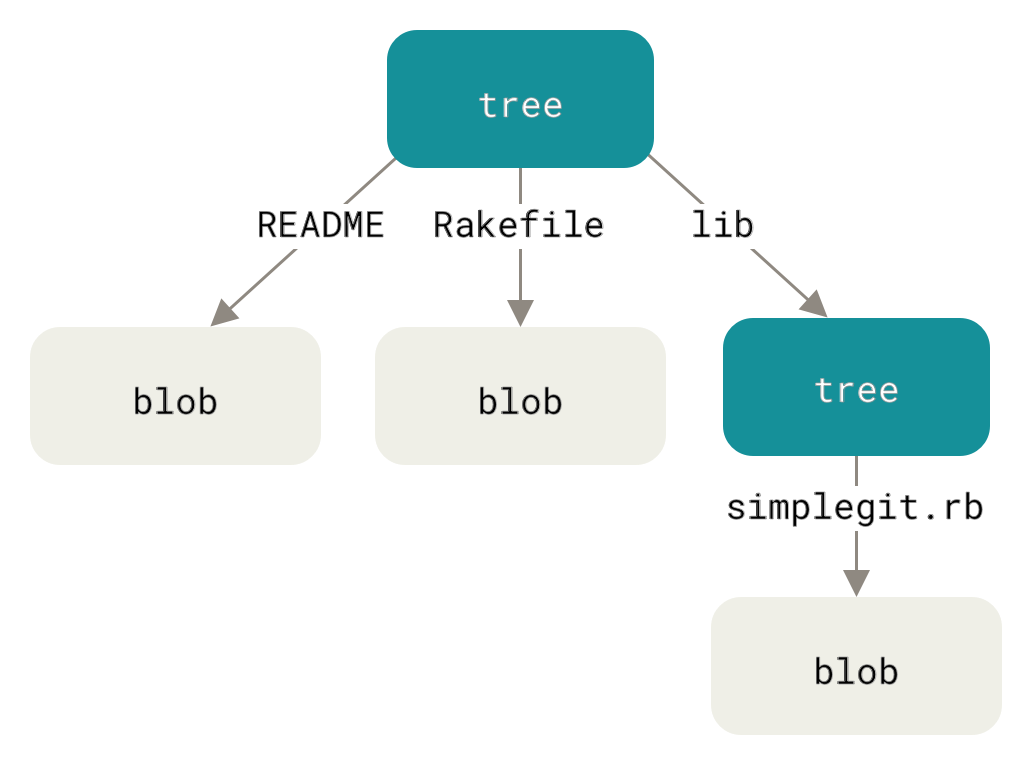
The next type of Git object we’ll examine is the tree, which solves the problem of storing the filename and also allows you to store a group of files together. Git stores content in a manner similar to a UNIX filesystem, but a bit simplified. All the content is stored as tree and blob objects, with trees corresponding to UNIX directory entries and blobs corresponding more or less to inodes or file contents. A single tree object contains one or more entries, each of which is the SHA-1 hash of a blob or subtree with its associated mode, type, and filename. For example, the most recent tree in a project may look something like this:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
The master^{tree} syntax specifies the tree object that is pointed to by the last commit on your master branch.
Notice that the lib subdirectory isn’t a blob but a pointer to another tree:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Depending on what shell you use, you may encounter errors when using the master^{tree} syntax.
In CMD on Windows, the ^ character is used for escaping, so you have to double it to avoid this: git cat-file -p master^^{tree}.
When using PowerShell, parameters using {} characters have to be quoted to avoid the parameter being parsed incorrectly: git cat-file -p 'master^{tree}'.
If you’re using ZSH, the ^ character is used for globbing, so you have to enclose the whole expression in quotes: git cat-file -p "master^{tree}".
Conceptually, the data that Git is storing looks something like this:
You can fairly easily create your own tree.
Git normally creates a tree by taking the state of your staging area or index and writing a series of tree objects from it.
So, to create a tree object, you first have to set up an index by staging some files.
To create an index with a single entry — the first version of your test.txt file — you can use the plumbing command git update-index.
You use this command to artificially add the earlier version of the test.txt file to a new staging area.
You must pass it the --add option because the file doesn’t yet exist in your staging area (you don’t even have a staging area set up yet) and --cacheinfo because the file you’re adding isn’t in your directory but is in your database.
Then, you specify the mode, SHA-1, and filename:
$ git update-index --add --cacheinfo 100644 \ 83baae61804e65cc73a7201a7252750c76066a30 test.txt
In this case, you’re specifying a mode of 100644, which means it’s a normal file.
Other options are 100755, which means it’s an executable file; and 120000, which specifies a symbolic link.
The mode is taken from normal UNIX modes but is much less flexible — these three modes are the only ones that are valid for files (blobs) in Git (although other modes are used for directories and submodules).
Now, you can use git write-tree to write the staging area out to a tree object.
No -w option is needed — calling this command automatically creates a tree object from the state of the index if that tree doesn’t yet exist:
$ git write-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 $ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579 100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
You can also verify that this is a tree object using the same git cat-file command you saw earlier:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree
You’ll now create a new tree with the second version of test.txt and a new file as well:
$ echo 'new file' > new.txt $ git update-index --add --cacheinfo 100644 \ 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt $ git update-index --add new.txt
Your staging area now has the new version of test.txt as well as the new file new.txt.
Write out that tree (recording the state of the staging area or index to a tree object) and see what it looks like:
$ git write-tree 0155eb4229851634a0f03eb265b69f5a2d56f341 $ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Notice that this tree has both file entries and also that the test.txt SHA-1 is the `version 2'' SHA-1 from earlier (`1f7a7a).
Just for fun, you’ll add the first tree as a subdirectory into this one.
You can read trees into your staging area by calling git read-tree.
In this case, you can read an existing tree into your staging area as a subtree by using the --prefix option with this command:
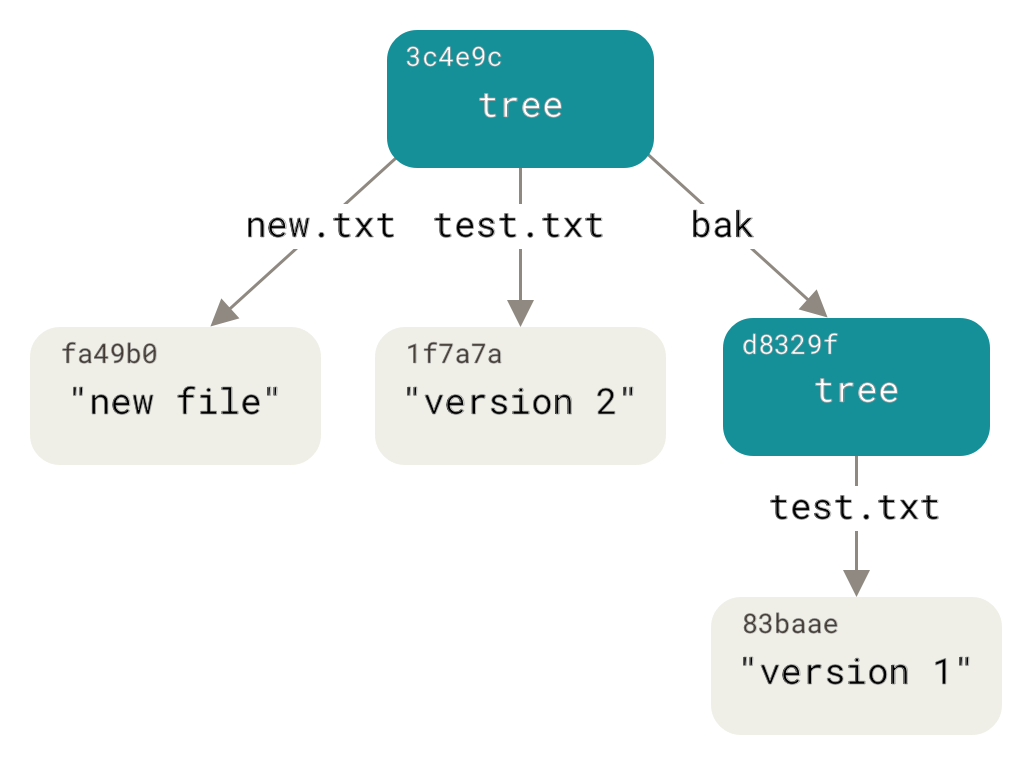
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579 $ git write-tree 3c4e9cd789d88d8d89c1073707c3585e41b0e614 $ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614 040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
If you created a working directory from the new tree you just wrote, you would get the two files in the top level of the working directory and a subdirectory named bak that contained the first version of the test.txt file.
You can think of the data that Git contains for these structures as being like this:
Commit Objects
If you’ve done all of the above, you now have three trees that represent the different snapshots of your project that you want to track, but the earlier problem remains: you must remember all three SHA-1 values in order to recall the snapshots. You also don’t have any information about who saved the snapshots, when they were saved, or why they were saved. This is the basic information that the commit object stores for you.
To create a commit object, you call commit-tree and specify a single tree SHA-1 and which commit objects, if any, directly preceded it.
Start with the first tree you wrote:
$ echo 'first commit' | git commit-tree d8329f fdf4fc3344e67ab068f836878b6c4951e3b15f3d
You will get a different hash value because of different creation time and author data.
Replace commit and tag hashes with your own checksums further in this chapter.
Now you can look at your new commit object with git cat-file:
$ git cat-file -p fdf4fc3 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 author Scott Chacon <schacon@gmail.com> 1243040974 -0700 committer Scott Chacon <schacon@gmail.com> 1243040974 -0700 first commit
The format for a commit object is simple: it specifies the top-level tree for the snapshot of the project at that point; the parent commits if any (the commit object described above does not have any parents); the author/committer information (which uses your user.name and user.email configuration settings and a timestamp); a blank line, and then the commit message.
Next, you’ll write the other two commit objects, each referencing the commit that came directly before it:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3 cac0cab538b970a37ea1e769cbbde608743bc96d $ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab 1a410efbd13591db07496601ebc7a059dd55cfe9
Each of the three commit objects points to one of the three snapshot trees you created.
Oddly enough, you have a real Git history now that you can view with the git log command, if you run it on the last commit SHA-1:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)
Amazing.
You’ve just done the low-level operations to build up a Git history without using any of the front end commands.
This is essentially what Git does when you run the git add and git commit commands — it stores blobs for the files that have changed, updates the index, writes out trees, and writes commit objects that reference the top-level trees and the commits that came immediately before them.
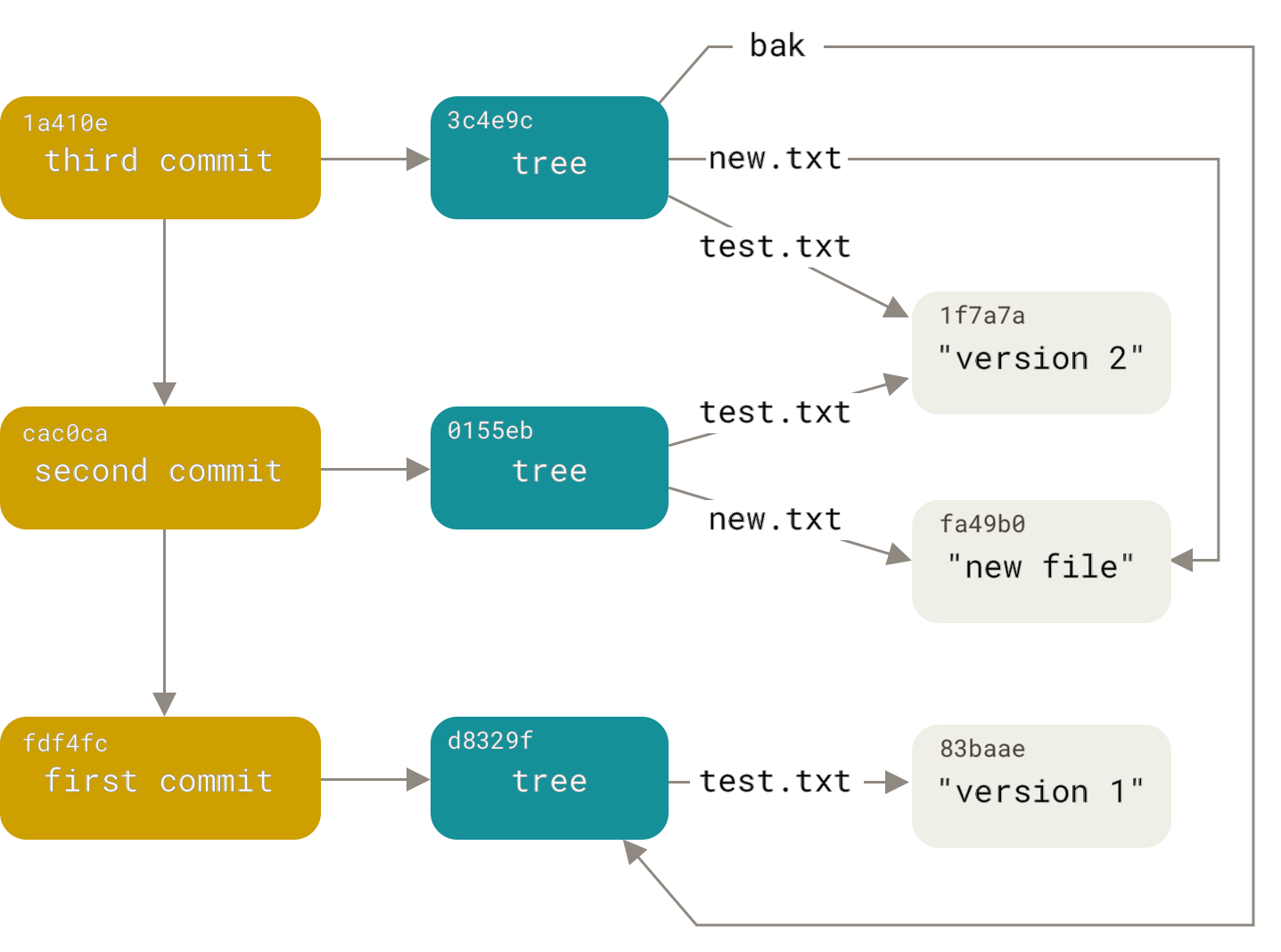
These three main Git objects — the blob, the tree, and the commit — are initially stored as separate files in your .git/objects directory.
Here are all the objects in the example directory now, commented with what they store:
$ find .git/objects -type f .git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2 .git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2 .git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1 .git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content' .git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt .git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
If you follow all the internal pointers, you get an object graph something like this:
Object Storage
We mentioned earlier that there is a header stored with every object you commit to your Git object database. Let’s take a minute to see how Git stores its objects. You’ll see how to store a blob object — in this case, the string ``what is up, doc?'' — interactively in the Ruby scripting language.
You can start up interactive Ruby mode with the irb command:
$ irb >> content = "what is up, doc?" => "what is up, doc?"
Git first constructs a header which starts by identifying the type of object — in this case, a blob. To that first part of the header, Git adds a space followed by the size in bytes of the content, and adding a final null byte:
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"
Git concatenates the header and the original content and then calculates the SHA-1 checksum of that new content.
You can calculate the SHA-1 value of a string in Ruby by including the SHA1 digest library with the require command and then calling Digest::SHA1.hexdigest() with the string:
>> store = header + content => "blob 16\u0000what is up, doc?" >> require 'digest/sha1' => true >> sha1 = Digest::SHA1.hexdigest(store) => "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Let’s compare that to the output of git hash-object.
Here we use echo -n to prevent adding a newline to the input.
$ echo -n "what is up, doc?" | git hash-object --stdin bd9dbf5aae1a3862dd1526723246b20206e5fc37
Git compresses the new content with zlib, which you can do in Ruby with the zlib library.
First, you need to require the library and then run Zlib::Deflate.deflate() on the content:
>> require 'zlib' => true >> zlib_content = Zlib::Deflate.deflate(store) => "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"
Finally, you’ll write your zlib-deflated content to an object on disk.
You’ll determine the path of the object you want to write out (the first two characters of the SHA-1 value being the subdirectory name, and the last 38 characters being the filename within that directory).
In Ruby, you can use the FileUtils.mkdir_p() function to create the subdirectory if it doesn’t exist.
Then, open the file with File.open() and write out the previously zlib-compressed content to the file with a write() call on the resulting file handle:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
Let’s check the content of the object using git cat-file:
--- $ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37 what is up, doc? ---
That’s it – you’ve created a valid Git blob object.
All Git objects are stored the same way, just with different types – instead of the string blob, the header will begin with commit or tree. Also, although the blob content can be nearly anything, the commit and tree content are very specifically formatted.
Git References
If you were interested in seeing the history of your repository reachable from commit, say, 1a410e, you could run something like git log 1a410e to display that history, but you would still have to remember that 1a410e is the commit you want to use as the starting point for that history.
Instead, it would be easier if you had a file in which you could store that SHA-1 value under a simple name so you could use that simple name rather than the raw SHA-1 value.
In Git, these simple names are called references'' or refs''; you can find the files that contain those SHA-1 values in the .git/refs directory.
In the current project, this directory contains no files, but it does contain a simple structure:
$ find .git/refs .git/refs .git/refs/heads .git/refs/tags $ find .git/refs -type f
To create a new reference that will help you remember where your latest commit is, you can technically do something as simple as this:
$ echo 1a410efbd13591db07496601ebc7a059dd55cfe9 > .git/refs/heads/master
Now, you can use the head reference you just created instead of the SHA-1 value in your Git commands:
$ git log --pretty=oneline master 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit cac0cab538b970a37ea1e769cbbde608743bc96d second commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
You aren’t encouraged to directly edit the reference files; instead, Git provides the safer command git update-ref to do this if you want to update a reference:
$ git update-ref refs/heads/master 1a410efbd13591db07496601ebc7a059dd55cfe9
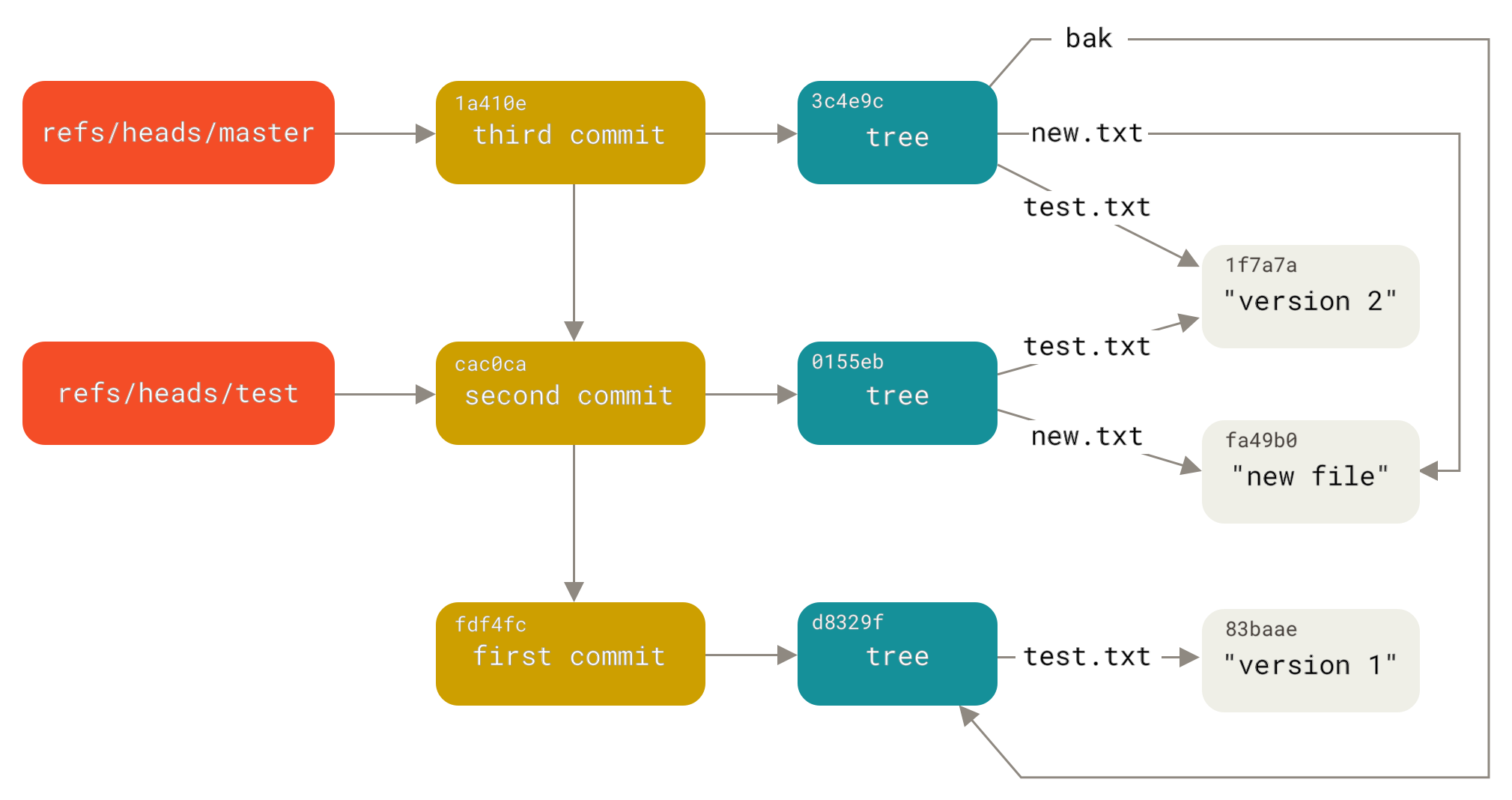
That’s basically what a branch in Git is: a simple pointer or reference to the head of a line of work. To create a branch back at the second commit, you can do this:
$ git update-ref refs/heads/test cac0ca
Your branch will contain only work from that commit down:
$ git log --pretty=oneline test cac0cab538b970a37ea1e769cbbde608743bc96d second commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Now, your Git database conceptually looks something like this:
When you run commands like git branch <branch>, Git basically runs that update-ref command to add the SHA-1 of the last commit of the branch you’re on into whatever new reference you want to create.
The HEAD
The question now is, when you run git branch <branch>, how does Git know the SHA-1 of the last commit?
The answer is the HEAD file.
Usually the HEAD file is a symbolic reference to the branch you’re currently on. By symbolic reference, we mean that unlike a normal reference, it contains a pointer to another reference.
However in some rare cases the HEAD file may contain the SHA-1 value of a git object. This happens when you checkout a tag, commit, or remote branch, which puts your repository in "detached HEAD" state.
If you look at the file, you’ll normally see something like this:
$ cat .git/HEAD ref: refs/heads/master
If you run git checkout test, Git updates the file to look like this:
$ cat .git/HEAD ref: refs/heads/test
When you run git commit, it creates the commit object, specifying the parent of that commit object to be whatever SHA-1 value the reference in HEAD points to.
You can also manually edit this file, but again a safer command exists to do so: git symbolic-ref.
You can read the value of your HEAD via this command:
$ git symbolic-ref HEAD refs/heads/master
You can also set the value of HEAD using the same command:
$ git symbolic-ref HEAD refs/heads/test $ cat .git/HEAD ref: refs/heads/test
You can’t set a symbolic reference outside of the refs style:
$ git symbolic-ref HEAD test fatal: Refusing to point HEAD outside of refs/
Tags
We just finished discussing Git’s three main object types (blobs, trees and commits), but there is a fourth. The tag object is very much like a commit object — it contains a tagger, a date, a message, and a pointer. The main difference is that a tag object generally points to a commit rather than a tree. It’s like a branch reference, but it never moves — it always points to the same commit but gives it a friendlier name.
As discussed in Git Basics, there are two types of tags: annotated and lightweight. You can make a lightweight tag by running something like this:
$ git update-ref refs/tags/v1.0 cac0cab538b970a37ea1e769cbbde608743bc96d
That is all a lightweight tag is — a reference that never moves.
An annotated tag is more complex, however.
If you create an annotated tag, Git creates a tag object and then writes a reference to point to it rather than directly to the commit.
You can see this by creating an annotated tag (using the -a option):
$ git tag -a v1.1 1a410efbd13591db07496601ebc7a059dd55cfe9 -m 'test tag'
Here’s the object SHA-1 value it created:
$ cat .git/refs/tags/v1.1 9585191f37f7b0fb9444f35a9bf50de191beadc2
Now, run git cat-file -p on that SHA-1 value:
$ git cat-file -p 9585191f37f7b0fb9444f35a9bf50de191beadc2 object 1a410efbd13591db07496601ebc7a059dd55cfe9 type commit tag v1.1 tagger Scott Chacon <schacon@gmail.com> Sat May 23 16:48:58 2009 -0700 test tag
Notice that the object entry points to the commit SHA-1 value that you tagged. Also notice that it doesn’t need to point to a commit; you can tag any Git object. In the Git source code, for example, the maintainer has added their GPG public key as a blob object and then tagged it. You can view the public key by running this in a clone of the Git repository:
$ git cat-file blob junio-gpg-pub
The Linux kernel repository also has a non-commit-pointing tag object — the first tag created points to the initial tree of the import of the source code.
Remotes
The third type of reference that you’ll see is a remote reference.
If you add a remote and push to it, Git stores the value you last pushed to that remote for each branch in the refs/remotes directory.
For instance, you can add a remote called origin and push your master branch to it:
$ git remote add origin git@github.com:schacon/simplegit-progit.git $ git push origin master Counting objects: 11, done. Compressing objects: 100% (5/5), done. Writing objects: 100% (7/7), 716 bytes, done. Total 7 (delta 2), reused 4 (delta 1) To git@github.com:schacon/simplegit-progit.git a11bef0..ca82a6d master -> master
Then, you can see what the master branch on the origin remote was the last time you communicated with the server, by checking the refs/remotes/origin/master file:
$ cat .git/refs/remotes/origin/master ca82a6dff817ec66f44342007202690a93763949
Remote references differ from branches (refs/heads references) mainly in that they’re considered read-only.
You can git checkout to one, but Git won’t point HEAD at one, so you’ll never update it with a commit command.
Git manages them as bookmarks to the last known state of where those branches were on those servers.
Packfiles
If you followed all of the instructions in the example from the previous section, you should now have a test Git repository with 11 objects — four blobs, three trees, three commits, and one tag:
$ find .git/objects -type f .git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2 .git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2 .git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1 .git/objects/95/85191f37f7b0fb9444f35a9bf50de191beadc2 # tag .git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content' .git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1 .git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt .git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Git compresses the contents of these files with zlib, and you’re not storing much, so all these files collectively take up only 925 bytes.
Now you’ll add some more sizable content to the repository to demonstrate an interesting feature of Git.
To demonstrate, we’ll add the repo.rb file from the Grit library — this is about a 22K source code file:
$ curl https://raw.githubusercontent.com/mojombo/grit/master/lib/grit/repo.rb > repo.rb $ git checkout master $ git add repo.rb $ git commit -m 'added repo.rb' [master 484a592] added repo.rb 3 files changed, 709 insertions(+), 2 deletions(-) delete mode 100644 bak/test.txt create mode 100644 repo.rb rewrite test.txt (100%)
If you look at the resulting tree, you can see the SHA-1 value that was calculated for your new repo.rb blob object:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
You can then use git cat-file to see how large that object is:
$ git cat-file -s 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 22044
At this point, modify that file a little, and see what happens:
$ echo '# testing' >> repo.rb $ git commit -am 'modified repo.rb a bit' [master 2431da6] modified repo.rb a bit 1 file changed, 1 insertion(+)
Check the tree created by that last commit, and you see something interesting:
$ git cat-file -p master^{tree}
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob b042a60ef7dff760008df33cee372b945b6e884e repo.rb
100644 blob e3f094f522629ae358806b17daf78246c27c007b test.txt
The blob is now a different blob, which means that although you added only a single line to the end of a 400-line file, Git stored that new content as a completely new object:
$ git cat-file -s b042a60ef7dff760008df33cee372b945b6e884e 22054
You have two nearly identical 22K objects on your disk (each compressed to approximately 7K). Wouldn’t it be nice if Git could store one of them in full but then the second object only as the delta between it and the first?
It turns out that it can.
The initial format in which Git saves objects on disk is called a loose'' object format.
However, occasionally Git packs up several of these objects into a single binary file called a packfile'' in order to save space and be more efficient.
Git does this if you have too many loose objects around, if you run the git gc command manually, or if you push to a remote server.
To see what happens, you can manually ask Git to pack up the objects by calling the git gc command:
$ git gc Counting objects: 18, done. Delta compression using up to 8 threads. Compressing objects: 100% (14/14), done. Writing objects: 100% (18/18), done. Total 18 (delta 3), reused 0 (delta 0)
If you look in your objects directory, you’ll find that most of your objects are gone, and a new pair of files has appeared:
$ find .git/objects -type f .git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37 .git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 .git/objects/info/packs .git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.idx .git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.pack
The objects that remain are the blobs that aren’t pointed to by any commit — in this case, the what is up, doc?'' example and the test content'' example blobs you created earlier.
Because you never added them to any commits, they’re considered dangling and aren’t packed up in your new packfile.
The other files are your new packfile and an index.
The packfile is a single file containing the contents of all the objects that were removed from your filesystem.
The index is a file that contains offsets into that packfile so you can quickly seek to a specific object.
What is cool is that although the objects on disk before you ran the gc command were collectively about 15K in size, the new packfile is only 7K.
You’ve cut your disk usage by half by packing your objects.
How does Git do this?
When Git packs objects, it looks for files that are named and sized similarly, and stores just the deltas from one version of the file to the next.
You can look into the packfile and see what Git did to save space.
The git verify-pack plumbing command allows you to see what was packed up:
$ git verify-pack -v .git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.idx 2431da676938450a4d72e260db3bf7b0f587bbc1 commit 223 155 12 69bcdaff5328278ab1c0812ce0e07fa7d26a96d7 commit 214 152 167 80d02664cb23ed55b226516648c7ad5d0a3deb90 commit 214 145 319 43168a18b7613d1281e5560855a83eb8fde3d687 commit 213 146 464 092917823486a802e94d727c820a9024e14a1fc2 commit 214 146 610 702470739ce72005e2edff522fde85d52a65df9b commit 165 118 756 d368d0ac0678cbe6cce505be58126d3526706e54 tag 130 122 874 fe879577cb8cffcdf25441725141e310dd7d239b tree 136 136 996 d8329fc1cc938780ffdd9f94e0d364e0ea74f579 tree 36 46 1132 deef2e1b793907545e50a2ea2ddb5ba6c58c4506 tree 136 136 1178 d982c7cb2c2a972ee391a85da481fc1f9127a01d tree 6 17 1314 1 \ deef2e1b793907545e50a2ea2ddb5ba6c58c4506 3c4e9cd789d88d8d89c1073707c3585e41b0e614 tree 8 19 1331 1 \ deef2e1b793907545e50a2ea2ddb5ba6c58c4506 0155eb4229851634a0f03eb265b69f5a2d56f341 tree 71 76 1350 83baae61804e65cc73a7201a7252750c76066a30 blob 10 19 1426 fa49b077972391ad58037050f2a75f74e3671e92 blob 9 18 1445 b042a60ef7dff760008df33cee372b945b6e884e blob 22054 5799 1463 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 blob 9 20 7262 1 \ b042a60ef7dff760008df33cee372b945b6e884e 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob 10 19 7282 non delta: 15 objects chain length = 1: 3 objects .git/objects/pack/pack-978e03944f5c581011e6998cd0e9e30000905586.pack: ok
Here, the 033b4 blob, which if you remember was the first version of your repo.rb file, is referencing the b042a blob, which was the second version of the file.
The third column in the output is the size of the object in the pack, so you can see that b042a takes up 22K of the file, but that 033b4 only takes up 9 bytes.
What is also interesting is that the second version of the file is the one that is stored intact, whereas the original version is stored as a delta — this is because you’re most likely to need faster access to the most recent version of the file.
The really nice thing about this is that it can be repacked at any time.
Git will occasionally repack your database automatically, always trying to save more space, but you can also manually repack at any time by running git gc by hand.
The Refspec
Throughout this book, we’ve used simple mappings from remote branches to local references, but they can be more complex. Suppose you were following along with the last couple sections and had created a small local Git repository, and now wanted to add a remote to it:
$ git remote add origin https://github.com/schacon/simplegit-progit
Running the command above adds a section to your repository’s .git/config file, specifying the name of the remote (origin), the URL of the remote repository, and the refspec to be used for fetching:
[remote "origin"] url = https://github.com/schacon/simplegit-progit fetch = +refs/heads/*:refs/remotes/origin/*
The format of the refspec is, first, an optional +, followed by <src>:<dst>, where <src> is the pattern for references on the remote side and <dst> is where those references will be tracked locally.
The + tells Git to update the reference even if it isn’t a fast-forward.
In the default case that is automatically written by a git remote add origin command, Git fetches all the references under refs/heads/ on the server and writes them to refs/remotes/origin/ locally.
So, if there is a master branch on the server, you can access the log of that branch locally via any of the following:
$ git log origin/master $ git log remotes/origin/master $ git log refs/remotes/origin/master
They’re all equivalent, because Git expands each of them to refs/remotes/origin/master.
If you want Git instead to pull down only the master branch each time, and not every other branch on the remote server, you can change the fetch line to refer to that branch only:
fetch = +refs/heads/master:refs/remotes/origin/master
This is just the default refspec for git fetch for that remote.
If you want to do a one-time only fetch, you can specify the specific refspec on the command line, too.
To pull the master branch on the remote down to origin/mymaster locally, you can run:
$ git fetch origin master:refs/remotes/origin/mymaster
You can also specify multiple refspecs. On the command line, you can pull down several branches like so:
$ git fetch origin master:refs/remotes/origin/mymaster \ topic:refs/remotes/origin/topic From git@github.com:schacon/simplegit ! [rejected] master -> origin/mymaster (non fast forward) * [new branch] topic -> origin/topic
In this case, the master branch pull was rejected because it wasn’t listed as a fast-forward reference.
You can override that by specifying the + in front of the refspec.
You can also specify multiple refspecs for fetching in your configuration file.
If you want to always fetch the master and experiment branches from the origin remote, add two lines:
[remote "origin"] url = https://github.com/schacon/simplegit-progit fetch = +refs/heads/master:refs/remotes/origin/master fetch = +refs/heads/experiment:refs/remotes/origin/experiment
You can’t use partial globs in the pattern, so this would be invalid:
fetch = +refs/heads/qa*:refs/remotes/origin/qa*
However, you can use namespaces (or directories) to accomplish something like that.
If you have a QA team that pushes a series of branches, and you want to get the master branch and any of the QA team’s branches but nothing else, you can use a config section like this:
[remote "origin"] url = https://github.com/schacon/simplegit-progit fetch = +refs/heads/master:refs/remotes/origin/master fetch = +refs/heads/qa/*:refs/remotes/origin/qa/*
If you have a complex workflow process that has a QA team pushing branches, developers pushing branches, and integration teams pushing and collaborating on remote branches, you can namespace them easily this way.
Pushing Refspecs
It’s nice that you can fetch namespaced references that way, but how does the QA team get their branches into a qa/ namespace in the first place?
You accomplish that by using refspecs to push.
If the QA team wants to push their master branch to qa/master on the remote server, they can run
$ git push origin master:refs/heads/qa/master
If they want Git to do that automatically each time they run git push origin, they can add a push value to their config file:
[remote "origin"] url = https://github.com/schacon/simplegit-progit fetch = +refs/heads/*:refs/remotes/origin/* push = refs/heads/master:refs/heads/qa/master
Again, this will cause a git push origin to push the local master branch to the remote qa/master branch by default.
You cannot use the refspec to fetch from one repository and push to another one. For an example to do so, refer to Keep your GitHub public repository up-to-date.
Deleting References
You can also use the refspec to delete references from the remote server by running something like this:
$ git push origin :topic
Because the refspec is <src>:<dst>, by leaving off the <src> part, this basically says to make the topic branch on the remote nothing, which deletes it.
Or you can use the newer syntax (available since Git v1.7.0):
$ git push origin --delete topic
Transfer Protocols
Git can transfer data between two repositories in two major ways: the dumb'' protocol and the smart'' protocol.
This section will quickly cover how these two main protocols operate.
The Dumb Protocol
If you’re setting up a repository to be served read-only over HTTP, the dumb protocol is likely what will be used.
This protocol is called `dumb'' because it requires no Git-specific code on the server side during the transport process; the fetch process is a series of HTTP `GET requests, where the client can assume the layout of the Git repository on the server.
The dumb protocol is fairly rarely used these days. It’s difficult to secure or make private, so most Git hosts (both cloud-based and on-premises) will refuse to use it. It’s generally advised to use the smart protocol, which we describe a bit further on.
Let’s follow the http-fetch process for the simplegit library:
$ git clone http://server/simplegit-progit.git
The first thing this command does is pull down the info/refs file.
This file is written by the update-server-info command, which is why you need to enable that as a post-receive hook in order for the HTTP transport to work properly:
=> GET info/refs ca82a6dff817ec66f44342007202690a93763949 refs/heads/master
Now you have a list of the remote references and SHA-1s. Next, you look for what the HEAD reference is so you know what to check out when you’re finished:
=> GET HEAD ref: refs/heads/master
You need to check out the master branch when you’ve completed the process.
At this point, you’re ready to start the walking process.
Because your starting point is the ca82a6 commit object you saw in the info/refs file, you start by fetching that:
=> GET objects/ca/82a6dff817ec66f44342007202690a93763949 (179 bytes of binary data)
You get an object back – that object is in loose format on the server, and you fetched it over a static HTTP GET request. You can zlib-uncompress it, strip off the header, and look at the commit content:
$ git cat-file -p ca82a6dff817ec66f44342007202690a93763949 tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf parent 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 author Scott Chacon <schacon@gmail.com> 1205815931 -0700 committer Scott Chacon <schacon@gmail.com> 1240030591 -0700 changed the version number
Next, you have two more objects to retrieve – cfda3b, which is the tree of content that the commit we just retrieved points to; and 085bb3, which is the parent commit:
=> GET objects/08/5bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 (179 bytes of data)
That gives you your next commit object. Grab the tree object:
=> GET objects/cf/da3bf379e4f8dba8717dee55aab78aef7f4daf (404 - Not Found)
Oops – it looks like that tree object isn’t in loose format on the server, so you get a 404 response back. There are a couple of reasons for this – the object could be in an alternate repository, or it could be in a packfile in this repository. Git checks for any listed alternates first:
=> GET objects/info/http-alternates (empty file)
If this comes back with a list of alternate URLs, Git checks for loose files and packfiles there – this is a nice mechanism for projects that are forks of one another to share objects on disk.
However, because no alternates are listed in this case, your object must be in a packfile.
To see what packfiles are available on this server, you need to get the objects/info/packs file, which contains a listing of them (also generated by update-server-info):
=> GET objects/info/packs P pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack
There is only one packfile on the server, so your object is obviously in there, but you’ll check the index file to make sure. This is also useful if you have multiple packfiles on the server, so you can see which packfile contains the object you need:
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.idx (4k of binary data)
Now that you have the packfile index, you can see if your object is in it – because the index lists the SHA-1s of the objects contained in the packfile and the offsets to those objects. Your object is there, so go ahead and get the whole packfile:
=> GET objects/pack/pack-816a9b2334da9953e530f27bcac22082a9f5b835.pack (13k of binary data)
You have your tree object, so you continue walking your commits.
They’re all also within the packfile you just downloaded, so you don’t have to do any more requests to your server.
Git checks out a working copy of the master branch that was pointed to by the HEAD reference you downloaded at the beginning.
The Smart Protocol
The dumb protocol is simple but a bit inefficient, and it can’t handle writing of data from the client to the server. The smart protocol is a more common method of transferring data, but it requires a process on the remote end that is intelligent about Git – it can read local data, figure out what the client has and needs, and generate a custom packfile for it. There are two sets of processes for transferring data: a pair for uploading data and a pair for downloading data.
Uploading Data
To upload data to a remote process, Git uses the send-pack and receive-pack processes.
The send-pack process runs on the client and connects to a receive-pack process on the remote side.
SSH
For example, say you run git push origin master in your project, and origin is defined as a URL that uses the SSH protocol.
Git fires up the send-pack process, which initiates a connection over SSH to your server.
It tries to run a command on the remote server via an SSH call that looks something like this:
$ ssh -x git@server "git-receive-pack 'simplegit-progit.git'" 00a5ca82a6dff817ec66f4437202690a93763949 refs/heads/master□report-status \ delete-refs side-band-64k quiet ofs-delta \ agent=git/2:2.1.1+github-607-gfba4028 delete-refs 0000
The git-receive-pack command immediately responds with one line for each reference it currently has – in this case, just the master branch and its SHA-1.
The first line also has a list of the server’s capabilities (here, report-status, delete-refs, and some others, including the client identifier).
Each line starts with a 4-character hex value specifying how long the rest of the line is. Your first line starts with 00a5, which is hexadecimal for 165, meaning that 165 bytes remain on that line. The next line is 0000, meaning the server is done with its references listing.
Now that it knows the server’s state, your send-pack process determines what commits it has that the server doesn’t.
For each reference that this push will update, the send-pack process tells the receive-pack process that information.
For instance, if you’re updating the master branch and adding an experiment branch, the send-pack response may look something like this:
0076ca82a6dff817ec66f44342007202690a93763949 15027957951b64cf874c3557a0f3547bd83b3ff6 \ refs/heads/master report-status 006c0000000000000000000000000000000000000000 cdfdb42577e2506715f8cfeacdbabc092bf63e8d \ refs/heads/experiment 0000
Git sends a line for each reference you’re updating with the line’s length, the old SHA-1, the new SHA-1, and the reference that is being updated. The first line also has the client’s capabilities. The SHA-1 value of all '0’s means that nothing was there before – because you’re adding the experiment reference. If you were deleting a reference, you would see the opposite: all '0’s on the right side.
Next, the client sends a packfile of all the objects the server doesn’t have yet. Finally, the server responds with a success (or failure) indication:
000eunpack ok
HTTP(S)
This process is mostly the same over HTTP, though the handshaking is a bit different. The connection is initiated with this request:
=> GET http://server/simplegit-progit.git/info/refs?service=git-receive-pack 001f# service=git-receive-pack 00ab6c5f0e45abd7832bf23074a333f739977c9e8188 refs/heads/master□report-status \ delete-refs side-band-64k quiet ofs-delta \ agent=git/2:2.1.1~vmg-bitmaps-bugaloo-608-g116744e 0000
That’s the end of the first client-server exchange.
The client then makes another request, this time a POST, with the data that send-pack provides.
=> POST http://server/simplegit-progit.git/git-receive-pack
The POST request includes the send-pack output and the packfile as its payload.
The server then indicates success or failure with its HTTP response.
Downloading Data
When you download data, the fetch-pack and upload-pack processes are involved.
The client initiates a fetch-pack process that connects to an upload-pack process on the remote side to negotiate what data will be transferred down.
SSH
If you’re doing the fetch over SSH, fetch-pack runs something like this:
$ ssh -x git@server "git-upload-pack 'simplegit-progit.git'"
After fetch-pack connects, upload-pack sends back something like this:
00dfca82a6dff817ec66f44342007202690a93763949 HEAD□multi_ack thin-pack \ side-band side-band-64k ofs-delta shallow no-progress include-tag \ multi_ack_detailed symref=HEAD:refs/heads/master \ agent=git/2:2.1.1+github-607-gfba4028 003fe2409a098dc3e53539a9028a94b6224db9d6a6b6 refs/heads/master 0000
This is very similar to what receive-pack responds with, but the capabilities are different.
In addition, it sends back what HEAD points to (symref=HEAD:refs/heads/master) so the client knows what to check out if this is a clone.
At this point, the fetch-pack process looks at what objects it has and responds with the objects that it needs by sending want'' and then the SHA-1 it wants.
It sends all the objects it already has with have'' and then the SHA-1.
At the end of this list, it writes `done'' to initiate the `upload-pack process to begin sending the packfile of the data it needs:
003cwant ca82a6dff817ec66f44342007202690a93763949 ofs-delta 0032have 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 0009done 0000
HTTP(S)
The handshake for a fetch operation takes two HTTP requests.
The first is a GET to the same endpoint used in the dumb protocol:
=> GET $GIT_URL/info/refs?service=git-upload-pack 001e# service=git-upload-pack 00e7ca82a6dff817ec66f44342007202690a93763949 HEAD□multi_ack thin-pack \ side-band side-band-64k ofs-delta shallow no-progress include-tag \ multi_ack_detailed no-done symref=HEAD:refs/heads/master \ agent=git/2:2.1.1+github-607-gfba4028 003fca82a6dff817ec66f44342007202690a93763949 refs/heads/master 0000
This is very similar to invoking git-upload-pack over an SSH connection, but the second exchange is performed as a separate request:
=> POST $GIT_URL/git-upload-pack HTTP/1.0 0032want 0a53e9ddeaddad63ad106860237bbf53411d11a7 0032have 441b40d833fdfa93eb2908e52742248faf0ee993 0000
Again, this is the same format as above. The response to this request indicates success or failure, and includes the packfile.
Protocols Summary
This section contains a very basic overview of the transfer protocols.
The protocol includes many other features, such as multi_ack or side-band capabilities, but covering them is outside the scope of this book.
We’ve tried to give you a sense of the general back-and-forth between client and server; if you need more knowledge than this, you’ll probably want to take a look at the Git source code.
Maintenance and Data Recovery
Occasionally, you may have to do some cleanup – make a repository more compact, clean up an imported repository, or recover lost work. This section will cover some of these scenarios.
Maintenance
Occasionally, Git automatically runs a command called auto gc''.
Most of the time, this command does nothing.
However, if there are too many loose objects (objects not in a packfile) or too many packfiles, Git launches a full-fledged gc'' stands for garbage collect, and the command does a number of things: it gathers up all the loose objects and places them in packfiles, it consolidates packfiles into one big packfile, and it removes objects that aren’t reachable from any commit and are a few months old.git gc command.
The
You can run auto gc manually as follows:
$ git gc --auto
Again, this generally does nothing.
You must have around 7,000 loose objects or more than 50 packfiles for Git to fire up a real gc command.
You can modify these limits with the gc.auto and gc.autopacklimit config settings, respectively.
The other thing gc will do is pack up your references into a single file.
Suppose your repository contains the following branches and tags:
$ find .git/refs -type f .git/refs/heads/experiment .git/refs/heads/master .git/refs/tags/v1.0 .git/refs/tags/v1.1
If you run git gc, you’ll no longer have these files in the refs directory.
Git will move them for the sake of efficiency into a file named .git/packed-refs that looks like this:
$ cat .git/packed-refs # pack-refs with: peeled fully-peeled cac0cab538b970a37ea1e769cbbde608743bc96d refs/heads/experiment ab1afef80fac8e34258ff41fc1b867c702daa24b refs/heads/master cac0cab538b970a37ea1e769cbbde608743bc96d refs/tags/v1.0 9585191f37f7b0fb9444f35a9bf50de191beadc2 refs/tags/v1.1 ^1a410efbd13591db07496601ebc7a059dd55cfe9
If you update a reference, Git doesn’t edit this file but instead writes a new file to refs/heads.
To get the appropriate SHA-1 for a given reference, Git checks for that reference in the refs directory and then checks the packed-refs file as a fallback.
However, if you can’t find a reference in the refs directory, it’s probably in your packed-refs file.
Notice the last line of the file, which begins with a ^.
This means the tag directly above is an annotated tag and that line is the commit that the annotated tag points to.
Data Recovery
At some point in your Git journey, you may accidentally lose a commit. Generally, this happens because you force-delete a branch that had work on it, and it turns out you wanted the branch after all; or you hard-reset a branch, thus abandoning commits that you wanted something from. Assuming this happens, how can you get your commits back?
Here’s an example that hard-resets the master branch in your test repository to an older commit and then recovers the lost commits.
First, let’s review where your repository is at this point:
$ git log --pretty=oneline ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit 484a59275031909e19aadb7c92262719cfcdf19a added repo.rb 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit cac0cab538b970a37ea1e769cbbde608743bc96d second commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Now, move the master branch back to the middle commit:
$ git reset --hard 1a410efbd13591db07496601ebc7a059dd55cfe9 HEAD is now at 1a410ef third commit $ git log --pretty=oneline 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit cac0cab538b970a37ea1e769cbbde608743bc96d second commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
You’ve effectively lost the top two commits – you have no branch from which those commits are reachable. You need to find the latest commit SHA-1 and then add a branch that points to it. The trick is finding that latest commit SHA-1 – it’s not like you’ve memorized it, right?
Often, the quickest way is to use a tool called git reflog.
As you’re working, Git silently records what your HEAD is every time you change it.
Each time you commit or change branches, the reflog is updated.
The reflog is also updated by the git update-ref command, which is another reason to use it instead of just writing the SHA-1 value to your ref files, as we covered in Git References.
You can see where you’ve been at any time by running git reflog:
$ git reflog
1a410ef HEAD@{0}: reset: moving to 1a410ef
ab1afef HEAD@{1}: commit: modified repo.rb a bit
484a592 HEAD@{2}: commit: added repo.rb
Here we can see the two commits that we have had checked out, however there is not much information here.
To see the same information in a much more useful way, we can run git log -g, which will give you a normal log output for your reflog.
$ git log -g
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Reflog: HEAD@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: updating HEAD
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:22:37 2009 -0700
third commit
commit ab1afef80fac8e34258ff41fc1b867c702daa24b
Reflog: HEAD@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: updating HEAD
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
modified repo.rb a bit
It looks like the bottom commit is the one you lost, so you can recover it by creating a new branch at that commit.
For example, you can start a branch named recover-branch at that commit (ab1afef):
$ git branch recover-branch ab1afef $ git log --pretty=oneline recover-branch ab1afef80fac8e34258ff41fc1b867c702daa24b modified repo a bit 484a59275031909e19aadb7c92262719cfcdf19a added repo.rb 1a410efbd13591db07496601ebc7a059dd55cfe9 third commit cac0cab538b970a37ea1e769cbbde608743bc96d second commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d first commit
Cool – now you have a branch named recover-branch that is where your master branch used to be, making the first two commits reachable again.
Next, suppose your loss was for some reason not in the reflog – you can simulate that by removing recover-branch and deleting the reflog.
Now the first two commits aren’t reachable by anything:
$ git branch -D recover-branch $ rm -Rf .git/logs/
Because the reflog data is kept in the .git/logs/ directory, you effectively have no reflog.
How can you recover that commit at this point?
One way is to use the git fsck utility, which checks your database for integrity.
If you run it with the --full option, it shows you all objects that aren’t pointed to by another object:
$ git fsck --full Checking object directories: 100% (256/256), done. Checking objects: 100% (18/18), done. dangling blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b dangling tree aea790b9a58f6cf6f2804eeac9f0abbe9631e4c9 dangling blob 7108f7ecb345ee9d0084193f147cdad4d2998293
In this case, you can see your missing commit after the string ``dangling commit''. You can recover it the same way, by adding a branch that points to that SHA-1.
Removing Objects
There are a lot of great things about Git, but one feature that can cause issues is the fact that a git clone downloads the entire history of the project, including every version of every file.
This is fine if the whole thing is source code, because Git is highly optimized to compress that data efficiently.
However, if someone at any point in the history of your project added a single huge file, every clone for all time will be forced to download that large file, even if it was removed from the project in the very next commit.
Because it’s reachable from the history, it will always be there.
This can be a huge problem when you’re converting Subversion or Perforce repositories into Git. Because you don’t download the whole history in those systems, this type of addition carries few consequences. If you did an import from another system or otherwise find that your repository is much larger than it should be, here is how you can find and remove large objects.
Be warned: this technique is destructive to your commit history. It rewrites every commit object since the earliest tree you have to modify to remove a large file reference. If you do this immediately after an import, before anyone has started to base work on the commit, you’re fine – otherwise, you have to notify all contributors that they must rebase their work onto your new commits.
To demonstrate, you’ll add a large file into your test repository, remove it in the next commit, find it, and remove it permanently from the repository. First, add a large object to your history:
$ curl https://www.kernel.org/pub/software/scm/git/git-2.1.0.tar.gz > git.tgz $ git add git.tgz $ git commit -m 'add git tarball' [master 7b30847] add git tarball 1 file changed, 0 insertions(+), 0 deletions(-) create mode 100644 git.tgz
Oops – you didn’t want to add a huge tarball to your project. Better get rid of it:
$ git rm git.tgz rm 'git.tgz' $ git commit -m 'oops - removed large tarball' [master dadf725] oops - removed large tarball 1 file changed, 0 insertions(+), 0 deletions(-) delete mode 100644 git.tgz
Now, gc your database and see how much space you’re using:
$ git gc Counting objects: 17, done. Delta compression using up to 8 threads. Compressing objects: 100% (13/13), done. Writing objects: 100% (17/17), done. Total 17 (delta 1), reused 10 (delta 0)
You can run the count-objects command to quickly see how much space you’re using:
$ git count-objects -v count: 7 size: 32 in-pack: 17 packs: 1 size-pack: 4868 prune-packable: 0 garbage: 0 size-garbage: 0
The size-pack entry is the size of your packfiles in kilobytes, so you’re using almost 5MB.
Before the last commit, you were using closer to 2K – clearly, removing the file from the previous commit didn’t remove it from your history.
Every time anyone clones this repository, they will have to clone all 5MB just to get this tiny project, because you accidentally added a big file.
Let’s get rid of it.
First you have to find it.
In this case, you already know what file it is.
But suppose you didn’t; how would you identify what file or files were taking up so much space?
If you run git gc, all the objects are in a packfile; you can identify the big objects by running another plumbing command called git verify-pack and sorting on the third field in the output, which is file size.
You can also pipe it through the tail command because you’re only interested in the last few largest files:
$ git verify-pack -v .git/objects/pack/pack-29…69.idx \ | sort -k 3 -n \ | tail -3 dadf7258d699da2c8d89b09ef6670edb7d5f91b4 commit 229 159 12 033b4468fa6b2a9547a70d88d1bbe8bf3f9ed0d5 blob 22044 5792 4977696 82c99a3e86bb1267b236a4b6eff7868d97489af1 blob 4975916 4976258 1438
The big object is at the bottom: 5MB.
To find out what file it is, you’ll use the rev-list command, which you used briefly in Enforcing a Specific Commit-Message Format.
If you pass --objects to rev-list, it lists all the commit SHA-1s and also the blob SHA-1s with the file paths associated with them.
You can use this to find your blob’s name:
$ git rev-list --objects --all | grep 82c99a3 82c99a3e86bb1267b236a4b6eff7868d97489af1 git.tgz
Now, you need to remove this file from all trees in your past. You can easily see what commits modified this file:
$ git log --oneline --branches -- git.tgz dadf725 oops - removed large tarball 7b30847 add git tarball
You must rewrite all the commits downstream from 7b30847 to fully remove this file from your Git history.
To do so, you use filter-branch, which you used in Rewriting History:
$ git filter-branch --index-filter \ 'git rm --ignore-unmatch --cached git.tgz' -- 7b30847^.. Rewrite 7b30847d080183a1ab7d18fb202473b3096e9f34 (1/2)rm 'git.tgz' Rewrite dadf7258d699da2c8d89b09ef6670edb7d5f91b4 (2/2) Ref 'refs/heads/master' was rewritten
The --index-filter option is similar to the --tree-filter option used in Rewriting History, except that instead of passing a command that modifies files checked out on disk, you’re modifying your staging area or index each time.
Rather than remove a specific file with something like rm file, you have to remove it with git rm --cached – you must remove it from the index, not from disk.
The reason to do it this way is speed – because Git doesn’t have to check out each revision to disk before running your filter, the process can be much, much faster.
You can accomplish the same task with --tree-filter if you want.
The --ignore-unmatch option to git rm tells it not to error out if the pattern you’re trying to remove isn’t there.
Finally, you ask filter-branch to rewrite your history only from the 7b30847 commit up, because you know that is where this problem started.
Otherwise, it will start from the beginning and will unnecessarily take longer.
Your history no longer contains a reference to that file.
However, your reflog and a new set of refs that Git added when you did the filter-branch under .git/refs/original still do, so you have to remove them and then repack the database.
You need to get rid of anything that has a pointer to those old commits before you repack:
$ rm -Rf .git/refs/original $ rm -Rf .git/logs/ $ git gc Counting objects: 15, done. Delta compression using up to 8 threads. Compressing objects: 100% (11/11), done. Writing objects: 100% (15/15), done. Total 15 (delta 1), reused 12 (delta 0)
Let’s see how much space you saved.
$ git count-objects -v count: 11 size: 4904 in-pack: 15 packs: 1 size-pack: 8 prune-packable: 0 garbage: 0 size-garbage: 0
The packed repository size is down to 8K, which is much better than 5MB.
You can see from the size value that the big object is still in your loose objects, so it’s not gone; but it won’t be transferred on a push or subsequent clone, which is what is important.
If you really wanted to, you could remove the object completely by running git prune with the --expire option:
$ git prune --expire now $ git count-objects -v count: 0 size: 0 in-pack: 15 packs: 1 size-pack: 8 prune-packable: 0 garbage: 0 size-garbage: 0
Environment Variables
Git always runs inside a bash shell, and uses a number of shell environment variables to determine how it behaves.
Occasionally, it comes in handy to know what these are, and how they can be used to make Git behave the way you want it to.
This isn’t an exhaustive list of all the environment variables Git pays attention to, but we’ll cover the most useful.
Global Behavior
Some of Git’s general behavior as a computer program depends on environment variables.
GIT_EXEC_PATH determines where Git looks for its sub-programs (like git-commit, git-diff, and others).
You can check the current setting by running git --exec-path.
HOME isn’t usually considered customizable (too many other things depend on it), but it’s where Git looks for the global configuration file.
If you want a truly portable Git installation, complete with global configuration, you can override HOME in the portable Git’s shell profile.
PREFIX is similar, but for the system-wide configuration.
Git looks for this file at $PREFIX/etc/gitconfig.
GIT_CONFIG_NOSYSTEM, if set, disables the use of the system-wide configuration file.
This is useful if your system config is interfering with your commands, but you don’t have access to change or remove it.
GIT_PAGER controls the program used to display multi-page output on the command line.
If this is unset, PAGER will be used as a fallback.
GIT_EDITOR is the editor Git will launch when the user needs to edit some text (a commit message, for example).
If unset, EDITOR will be used.
Repository Locations
Git uses several environment variables to determine how it interfaces with the current repository.
GIT_DIR is the location of the .git folder.
If this isn’t specified, Git walks up the directory tree until it gets to ~ or /, looking for a .git directory at every step.
GIT_CEILING_DIRECTORIES controls the behavior of searching for a .git directory.
If you access directories that are slow to load (such as those on a tape drive, or across a slow network connection), you may want to have Git stop trying earlier than it might otherwise, especially if Git is invoked when building your shell prompt.
GIT_WORK_TREE is the location of the root of the working directory for a non-bare repository.
If --git-dir or GIT_DIR is specified but none of --work-tree, GIT_WORK_TREE or core.worktree is specified, the current working directory is regarded as the top level of your working tree.
GIT_INDEX_FILE is the path to the index file (non-bare repositories only).
GIT_OBJECT_DIRECTORY can be used to specify the location of the directory that usually resides at .git/objects.
GIT_ALTERNATE_OBJECT_DIRECTORIES is a colon-separated list (formatted like /dir/one:/dir/two:…) which tells Git where to check for objects if they aren’t in GIT_OBJECT_DIRECTORY.
If you happen to have a lot of projects with large files that have the exact same contents, this can be used to avoid storing too many copies of them.
Pathspecs
A `pathspec'' refers to how you specify paths to things in Git, including the use of wildcards.
These are used in the `.gitignore file, but also on the command-line (git add *.c).
GIT_GLOB_PATHSPECS and GIT_NOGLOB_PATHSPECS control the default behavior of wildcards in pathspecs.
If GIT_GLOB_PATHSPECS is set to 1, wildcard characters act as wildcards (which is the default); if GIT_NOGLOB_PATHSPECS is set to 1, wildcard characters only match themselves, meaning something like .c would only match a file named `.c'', rather than any file whose name ends with `.c.
You can override this in individual cases by starting the pathspec with :(glob) or :(literal), as in :(glob)*.c.
GIT_LITERAL_PATHSPECS disables both of the above behaviors; no wildcard characters will work, and the override prefixes are disabled as well.
GIT_ICASE_PATHSPECS sets all pathspecs to work in a case-insensitive manner.
Committing
The final creation of a Git commit object is usually done by git-commit-tree, which uses these environment variables as its primary source of information, falling back to configuration values only if these aren’t present.
GIT_AUTHOR_NAME is the human-readable name in the ``author'' field.
GIT_AUTHOR_EMAIL is the email for the ``author'' field.
GIT_AUTHOR_DATE is the timestamp used for the ``author'' field.
GIT_COMMITTER_NAME sets the human name for the ``committer'' field.
GIT_COMMITTER_EMAIL is the email address for the ``committer'' field.
GIT_COMMITTER_DATE is used for the timestamp in the ``committer'' field.
EMAIL is the fallback email address in case the user.email configuration value isn’t set.
If this isn’t set, Git falls back to the system user and host names.
Networking
Git uses the curl library to do network operations over HTTP, so GIT_CURL_VERBOSE tells Git to emit all the messages generated by that library.
This is similar to doing curl -v on the command line.
GIT_SSL_NO_VERIFY tells Git not to verify SSL certificates.
This can sometimes be necessary if you’re using a self-signed certificate to serve Git repositories over HTTPS, or you’re in the middle of setting up a Git server but haven’t installed a full certificate yet.
If the data rate of an HTTP operation is lower than GIT_HTTP_LOW_SPEED_LIMIT bytes per second for longer than GIT_HTTP_LOW_SPEED_TIME seconds, Git will abort that operation.
These values override the http.lowSpeedLimit and http.lowSpeedTime configuration values.
GIT_HTTP_USER_AGENT sets the user-agent string used by Git when communicating over HTTP.
The default is a value like git/2.0.0.
Diffing and Merging
GIT_DIFF_OPTS is a bit of a misnomer.
The only valid values are -u<n> or --unified=<n>, which controls the number of context lines shown in a git diff command.
GIT_EXTERNAL_DIFF is used as an override for the diff.external configuration value.
If it’s set, Git will invoke this program when git diff is invoked.
GIT_DIFF_PATH_COUNTER and GIT_DIFF_PATH_TOTAL are useful from inside the program specified by GIT_EXTERNAL_DIFF or diff.external.
The former represents which file in a series is being diffed (starting with 1), and the latter is the total number of files in the batch.
GIT_MERGE_VERBOSITY controls the output for the recursive merge strategy.
The allowed values are as follows:
-
0 outputs nothing, except possibly a single error message.
-
1 shows only conflicts.
-
2 also shows file changes.
-
3 shows when files are skipped because they haven’t changed.
-
4 shows all paths as they are processed.
-
5 and above show detailed debugging information.
The default value is 2.
Debugging
Want to really know what Git is up to? Git has a fairly complete set of traces embedded, and all you need to do is turn them on. The possible values of these variables are as follows:
-
true'',1'', or ``2'' – the trace category is written to stderr. -
An absolute path starting with
/– the trace output will be written to that file.
GIT_TRACE controls general traces, which don’t fit into any specific category.
This includes the expansion of aliases, and delegation to other sub-programs.
$ GIT_TRACE=true git lga 20:12:49.877982 git.c:554 trace: exec: 'git-lga' 20:12:49.878369 run-command.c:341 trace: run_command: 'git-lga' 20:12:49.879529 git.c:282 trace: alias expansion: lga => 'log' '--graph' '--pretty=oneline' '--abbrev-commit' '--decorate' '--all' 20:12:49.879885 git.c:349 trace: built-in: git 'log' '--graph' '--pretty=oneline' '--abbrev-commit' '--decorate' '--all' 20:12:49.899217 run-command.c:341 trace: run_command: 'less' 20:12:49.899675 run-command.c:192 trace: exec: 'less'
GIT_TRACE_PACK_ACCESS controls tracing of packfile access.
The first field is the packfile being accessed, the second is the offset within that file:
$ GIT_TRACE_PACK_ACCESS=true git status 20:10:12.081397 sha1_file.c:2088 .git/objects/pack/pack-c3fa...291e.pack 12 20:10:12.081886 sha1_file.c:2088 .git/objects/pack/pack-c3fa...291e.pack 34662 20:10:12.082115 sha1_file.c:2088 .git/objects/pack/pack-c3fa...291e.pack 35175 # […] 20:10:12.087398 sha1_file.c:2088 .git/objects/pack/pack-e80e...e3d2.pack 56914983 20:10:12.087419 sha1_file.c:2088 .git/objects/pack/pack-e80e...e3d2.pack 14303666 On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working directory clean
GIT_TRACE_PACKET enables packet-level tracing for network operations.
$ GIT_TRACE_PACKET=true git ls-remote origin 20:15:14.867043 pkt-line.c:46 packet: git< # service=git-upload-pack 20:15:14.867071 pkt-line.c:46 packet: git< 0000 20:15:14.867079 pkt-line.c:46 packet: git< 97b8860c071898d9e162678ea1035a8ced2f8b1f HEAD\0multi_ack thin-pack side-band side-band-64k ofs-delta shallow no-progress include-tag multi_ack_detailed no-done symref=HEAD:refs/heads/master agent=git/2.0.4 20:15:14.867088 pkt-line.c:46 packet: git< 0f20ae29889d61f2e93ae00fd34f1cdb53285702 refs/heads/ab/add-interactive-show-diff-func-name 20:15:14.867094 pkt-line.c:46 packet: git< 36dc827bc9d17f80ed4f326de21247a5d1341fbc refs/heads/ah/doc-gitk-config # […]
GIT_TRACE_PERFORMANCE controls logging of performance data.
The output shows how long each particular git invocation takes.
$ GIT_TRACE_PERFORMANCE=true git gc 20:18:19.499676 trace.c:414 performance: 0.374835000 s: git command: 'git' 'pack-refs' '--all' '--prune' 20:18:19.845585 trace.c:414 performance: 0.343020000 s: git command: 'git' 'reflog' 'expire' '--all' Counting objects: 170994, done. Delta compression using up to 8 threads. Compressing objects: 100% (43413/43413), done. Writing objects: 100% (170994/170994), done. Total 170994 (delta 126176), reused 170524 (delta 125706) 20:18:23.567927 trace.c:414 performance: 3.715349000 s: git command: 'git' 'pack-objects' '--keep-true-parents' '--honor-pack-keep' '--non-empty' '--all' '--reflog' '--unpack-unreachable=2.weeks.ago' '--local' '--delta-base-offset' '.git/objects/pack/.tmp-49190-pack' 20:18:23.584728 trace.c:414 performance: 0.000910000 s: git command: 'git' 'prune-packed' 20:18:23.605218 trace.c:414 performance: 0.017972000 s: git command: 'git' 'update-server-info' 20:18:23.606342 trace.c:414 performance: 3.756312000 s: git command: 'git' 'repack' '-d' '-l' '-A' '--unpack-unreachable=2.weeks.ago' Checking connectivity: 170994, done. 20:18:25.225424 trace.c:414 performance: 1.616423000 s: git command: 'git' 'prune' '--expire' '2.weeks.ago' 20:18:25.232403 trace.c:414 performance: 0.001051000 s: git command: 'git' 'rerere' 'gc' 20:18:25.233159 trace.c:414 performance: 6.112217000 s: git command: 'git' 'gc'
GIT_TRACE_SETUP shows information about what Git is discovering about the repository and environment it’s interacting with.
$ GIT_TRACE_SETUP=true git status 20:19:47.086765 trace.c:315 setup: git_dir: .git 20:19:47.087184 trace.c:316 setup: worktree: /Users/ben/src/git 20:19:47.087191 trace.c:317 setup: cwd: /Users/ben/src/git 20:19:47.087194 trace.c:318 setup: prefix: (null) On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working directory clean
Miscellaneous
GIT_SSH, if specified, is a program that is invoked instead of ssh when Git tries to connect to an SSH host.
It is invoked like $GIT_SSH [username@]host [-p <port>] <command>.
Note that this isn’t the easiest way to customize how ssh is invoked; it won’t support extra command-line parameters, so you’d have to write a wrapper script and set GIT_SSH to point to it.
It’s probably easier just to use the ~/.ssh/config file for that.
GIT_ASKPASS is an override for the core.askpass configuration value.
This is the program invoked whenever Git needs to ask the user for credentials, which can expect a text prompt as a command-line argument, and should return the answer on stdout.
(See Credential Storage for more on this subsystem.)
GIT_NAMESPACE controls access to namespaced refs, and is equivalent to the --namespace flag.
This is mostly useful on the server side, where you may want to store multiple forks of a single repository in one repository, only keeping the refs separate.
GIT_FLUSH can be used to force Git to use non-buffered I/O when writing incrementally to stdout.
A value of 1 causes Git to flush more often, a value of 0 causes all output to be buffered.
The default value (if this variable is not set) is to choose an appropriate buffering scheme depending on the activity and the output mode.
GIT_REFLOG_ACTION lets you specify the descriptive text written to the reflog.
Here’s an example:
$ GIT_REFLOG_ACTION="my action" git commit --allow-empty -m 'my message'
[master 9e3d55a] my message
$ git reflog -1
9e3d55a HEAD@{0}: my action: my message
Summary
At this point, you should have a pretty good understanding of what Git does in the background and, to some degree, how it’s implemented. This chapter has covered a number of plumbing commands — commands that are lower level and simpler than the porcelain commands you’ve learned about in the rest of the book. Understanding how Git works at a lower level should make it easier to understand why it’s doing what it’s doing and also to write your own tools and helper scripts to make your specific workflow work for you.
Git as a content-addressable filesystem is a very powerful tool that you can easily use as more than just a VCS. We hope you can use your newfound knowledge of Git internals to implement your own cool application of this technology and feel more comfortable using Git in more advanced ways.